在过去一年中,AI Agent相关技术经历了快速的演进:从最初简单的函数调用,发展到特定领域的工具开发,直到现在涌现出各种通用Agent应用平台。伴随技术进步,新名词也层出不穷,这对于很多人来说可能会感到困惑。在这篇文章中,我将用通俗易懂的语言解释Agent、MCP和Responses API这三个关键概念,并结合实践经验,分享如何选择合适的技术栈来快速构建智能应用。
为了方便理解,可以这样简单概括:
* AI Agent:能自主思考、规划并执行任务的AI程序,就好比你雇佣了一个"AI员工"
* MCP协议:可以理解为AI工具的"通用插座",统一了各种工具的接入标准
* Responses API:OpenAI专门为构建Agent而设计的工具包,它提供了许多开箱即用的高级功能。
从生活中的例子理解这三大概念
举一个场景来说明,假设你正在组建一个团队,那么你需要:
1. 招聘员工(Agent) :寻找那些具备独立思考和执行能力的人才。
2. 制定沟通协议(MCP) :需要建立一套规则,确保团队成员和外部资源之间能够高效协作。
3. 配备工具套装(Responses API) :给团队成员提供一个包含各种必要工具的办公套件
让我们通过一个具体的场景来加深理解:假设你需要为公司搭建一个自动化客服系统,那么:
* 这里的Agent 就是能够与客户交流并解决问题"AI客服专员"。
* MCP 则是这位"AI客服"与公司内部的CRM系统、邮件系统以及知识库进行通信时所遵循的标准协议。
* Responses API 就像是OpenAI提供的一套客服"工具箱",包含了搜索、知识库查询等功能。
Agent的三大核心能力
一个功能完善的Agent通常需要具备以下三个核心能力:
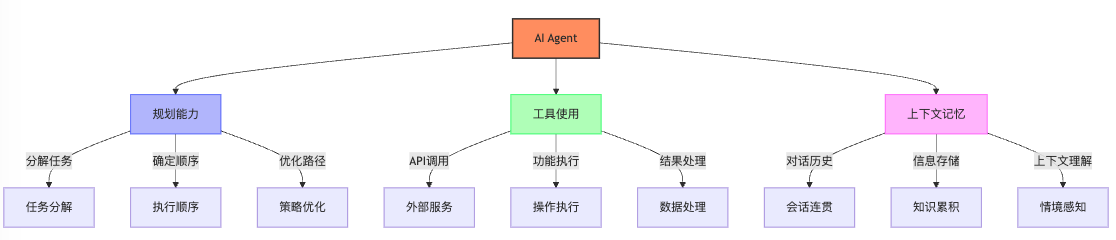
1. 规划能力:将复杂的任务分解为更小的步骤,并确定合理的执行顺序。
2. 工具使用:能够调用各种API服务来完成具体的任务操作,比如查询数据、发送邮件等。
3. 上下文记忆:通过保持对话的连贯性、记住关键信息来便于后续的使用。
这三个能力对于Agent来说都至关重要。以企业客服Agent为例:
* 如果缺乏规划能力,它就无法处理需要多个步骤才能完成的任务,例如“帮我查一下账单,然后安排退款”。
* 如果缺乏工具使用能力,它可能只会说“我理解您的问题”,但实际上无法查询订单系统来获取信息。
* 如果缺乏记忆能力,用户可能需要反复提供相同的信息,因为Agent无法记住之前的对话内容。
为什么我们需要标准化工具调用?
在早期,开发者在构建Agent时,不得不为每一个需要使用的工具手动定义和管理接口:
传统方式:为每个服务定义不同的函数格式
def github_create_pr(repo, branch, title, description):
# GitHub特定逻辑
passdef jira_create_ticket(project, summary, description, priority):
# JIRA特定逻辑
pass
每添加一个工具就要编写特定适配代码
这种方式可能会导致以下问题:
* 开发效率低下 : 每集成一个工具都需要编写大量的定制化代码。
* 扩展性差 : 有新的工具接入时,往往需要对模型的提示词和相关的执行逻辑进行重构。
* 难以维护 : 一旦相关工具的接口更新,对应的适配层也需要同步进行修改。
MCP:不只是协议,是生态
MCP(Model Context Protocol)就像是将AI世界从"各种充电接口"统一为"Type-C标准"的一次进化。
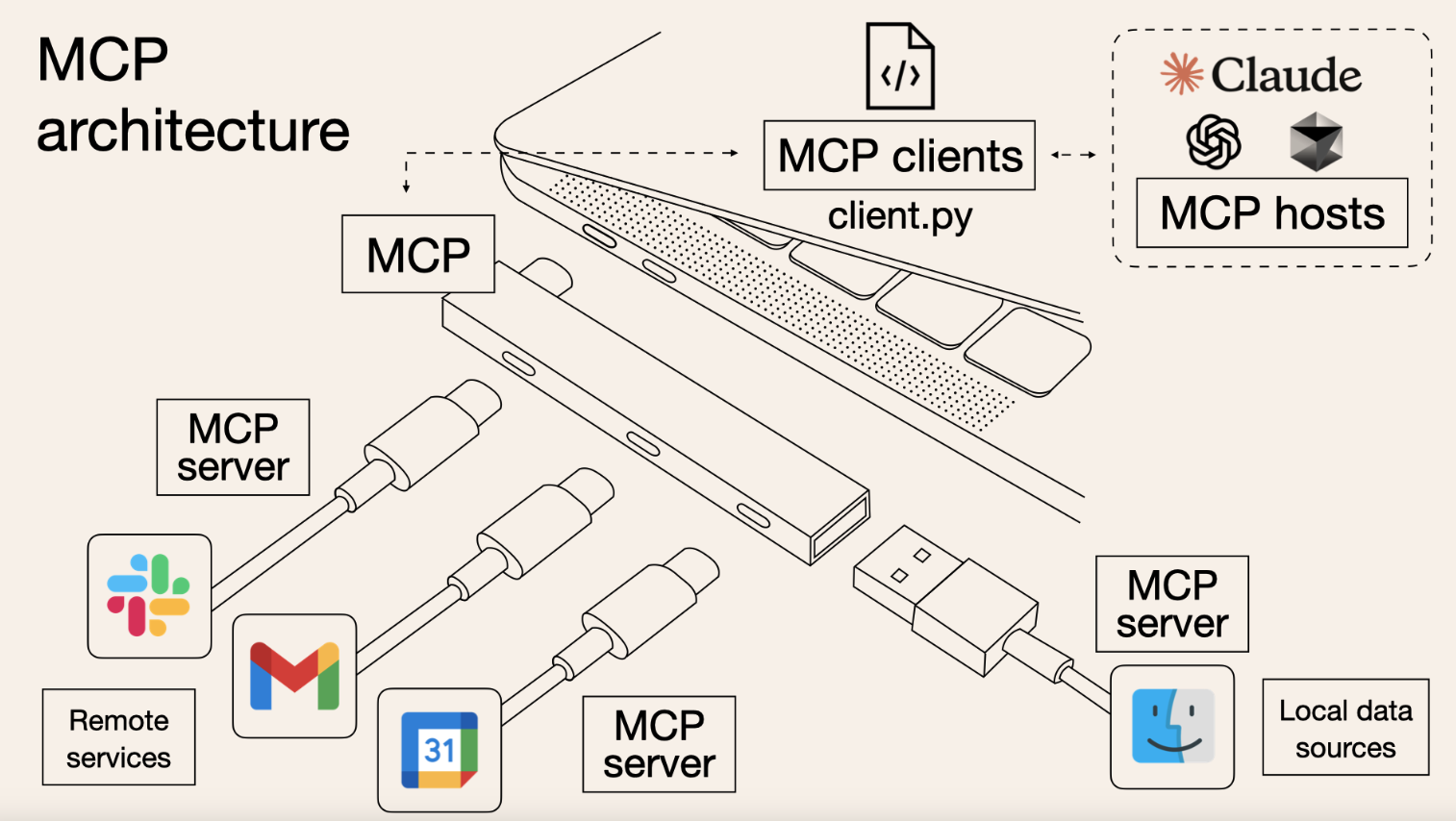
MCP期望实现AI工具的即插即用,从而降低开发者接入成本。
就如同这张图中,MPC作为拓展坞,可以同时连接多种设备(MCP Server),然后对MCP客户端保持统一标准。
实战体验:OpenAI的Responses API
相较于MCP,OpenAI近期推出的Responses API提供了更为直接的解决方案。尽管可能存在局限,但它满足了开发者快速构建智能代理的实际需求。
以下是我使用Responses API构建搜索增强客服机器人的代码示例:
// 实用的搜索增强客服Agent
async function createCustomerSupportAgent() {
// 1. 创建知识库向量存储
const supportDocs = await openai.vectorStores.create({
name: "CustomerSupportKnowledge",
file_ids: [policyDoc.id, faqDoc.id, productDoc.id],
});
// 2. 定义自定义函数
async function createTicket(issue, severity, customer_id) {
// 与票务系统集成的逻辑
const ticketId = await ticketSystem.create({issue, severity, customer_id});
return { ticketId, status: "created" };
}
// 3. 构建客服Agent
return async function(customerQuery, customerId) {
const response = await openai.responses.create({
model: "gpt-4o",
tools: [
// 内置文档搜索工具
{
type: "file_search",
vector_store_ids: [supportDocs.id]
},
// 内置网络搜索工具(获取最新产品信息)
{ type: "web_search_preview" },
// 自定义工具
{
type: "function",
function: {
name: "create_support_ticket",
description: "Creates a support ticket when customer issue cannot be resolved",
parameters: {
type: "object",
properties: {
issue: { type: "string", description: "Issue description" },
severity: { type: "string", enum: ["low", "medium", "high", "critical"] },
customer_id: { type: "string" }
},
required: ["issue", "severity", "customer_id"]
}
}
}
],
// 指导模型行为的系统提示
system: "你是专业客服代表。首先尝试使用知识库回答问题,需要时搜索最新信息,无法解决时创建工单。",
input: customerQuery,
// 传递上下文参数给函数
context: { customer_id: customerId }
});
return response.output_text;
};
}
// 使用方式
const customerSupport = await createCustomerSupportAgent();
const reply = await customerSupport("我的高级会员折扣没有显示,我上周已经升级了", "cust_12345");
使用下来,我发现Responses API最突出的三个优点是:
1. 无缝集成多种工具 - 可以在同一个请求中混用文档搜索、网络搜索和自定义函数
2. 上下文传递 - 比如客户ID这种信息可以安全地传给相关函数
3. 接口简洁 - 开发者只需要专注于业务逻辑,无需关注底层工具调用。
各方案性能实测对比
在一个企业知识库问答场景中,我对三种方案进行了性能测试:
| 指标 | 传统函数调用 | MCP方案 | Responses API |
|------|------------|---------|--------------|
| 开发时间 | 5天 | 2天 | 0.5天 |
| 平均响应时间 | 4.2秒 | 3.8秒 | 3.5秒 |
| 准确率 | 82% | 85% | 88% |
| 工具扩展难度 | 高 | 中 | 低 |
| 平台通用性 | 高 | 中 | 低(仅OpenAI) |
从测试结果来看,Responses API在开发速度和性能上领先,但受限于单一平台;传统方法通用性最好但是开发成本比较高;MCP则在各方面较为均衡。
实战案例:从0开发一个文档助手Agent
这里,我通过使用Responses API来演示如何从0到1开发一个文档助手Agent,以下是简化流程:
第一步是知识库准备:
// 上传并索引文档
const documentFiles = await Promise.all(
['guide.pdf', 'api.md', 'examples.ipynb'].map(async file => {
return await openai.files.create({
file: fs.createReadStream(file),
purpose: "vector-search"
});
})
);
// 创建向量存储
const docsVectorStore = await openai.vectorStores.create({
name: "ProductDocumentation",
file_ids: documentFiles.map(f => f.id)
});
第二步,加上代码执行功能:
// 定义代码执行函数
async function runPythonCode(code) {
try {
// 安全地执行代码(实际生产环境需更多安全措施)
const result = await sandboxedPythonExecute(code);
return { success: true, output: result };
} catch (error) {
return { success: false, error: error.message };
}
}
第三步,组装Agent的核心逻辑:
// 创建文档助手Agent
async function documentationHelperAgent(userQuery) {
const response = await openai.responses.create({
model: "gpt-4o",
tools: [
// 文档搜索工具
{ type: "file_search", vector_store_ids: [docsVectorStore.id] },
// 定义代码运行工具
{
type: "function",
function: {
name: "run_python_code",
description: "Executes Python code examples and returns the result",
parameters: {
type: "object",
properties: {
code: { type: "string", description: "Python code to execute" }
},
required: ["code"]
}
}
}
],
system: 作为文档助手,帮助用户理解产品文档并运行示例代码。
当用户询问特定功能时,先搜索相关文档,然后提供简洁解释,
必要时可运行示例代码验证功能或演示用法。,
input: userQuery
});
// 特别处理:如果有代码运行请求
if (response.tool_calls) {
// 适当处理并执行工具调用
// ...处理代码...
}
return response.output_text;
}
通过这个案例展示可以看到,如何结合文档检索和代码执行能力来打造出一个既能回答问题又能进行验证的实用助手。
如何选择适合你的方案?
基于之前做的一些对比测试工作,我总结了一些选择建议:
适合使用MCP的场景:
- 需要同时支持GPT和Claude等多种模型
- 已经有大量工具需要通过标准化的方式接入
- 目标是打造一个需要长期维护的企业应用
适合使用Responses API的场景:
- 需要尽快推出一个可用产品
- 已经在使用OpenAI的服务
- 你想利用现成的搜索、文件检索等工具)
- 你的团队规模较小,资源有限
适合传统函数调用的场景:
- 项目规模小,工具调用需求简单
- 在定制化流程控制方面的需求强烈
- 你需要与特定系统深度集成
---
最后说一点个人建议:
别在技术选择上浪费太多时间。选一个方案快速上手,从用户那里获得反馈,然后迭代改进 - 这比纠结于"完美方案"更实际。毕竟在这个领域,今天的"最佳实践"可能在六个月后就已经过时了。