利用DeepSeek R1模型,打造一款助力日常工作的深度研究助手
过去一个月,深度研究智能体(Deep Research Agents,或称深度研究助手)成为大型语言模型(LLM)行业的一个热门话题,各大厂商竞相开发并尝试商业化。这股热潮的催化剂是DeepSeek R1推理模型的发布及其开源特性。在本文中,我们将从零开始构建一个深度研究智能体系统,深入了解这些新兴智能体系统背后的运作原理,并使用DeepSeek R1模型运行我们的系统。
什么是深度研究智能体?
总的来说,深度研究智能体是一种利用大型语言模型(LLM)进行深入研究的系统,近期在AI领域引起了广泛关注。通常,这一过程至少包括以下步骤:
- 研究规划:制定研究报告的大纲,作为系统的最终输出框架。
- 任务拆分:将大纲拆分为可管理的步骤。
- 分段深入研究:针对报告的每个部分进行深入分析,推理所需数据,并利用网络搜索工具支持分析。
- 反思与改进:对研究各阶段生成的数据进行反思,优化结果。
- 总结与报告:汇总检索到的数据,生成最终的研究报告。
在今天的指南中,我们将不依赖任何LLM编排框架(即用于协调和管理大型语言模型的工具),独立实现上述所有功能。接下来,我们将逐步讲解实现过程。
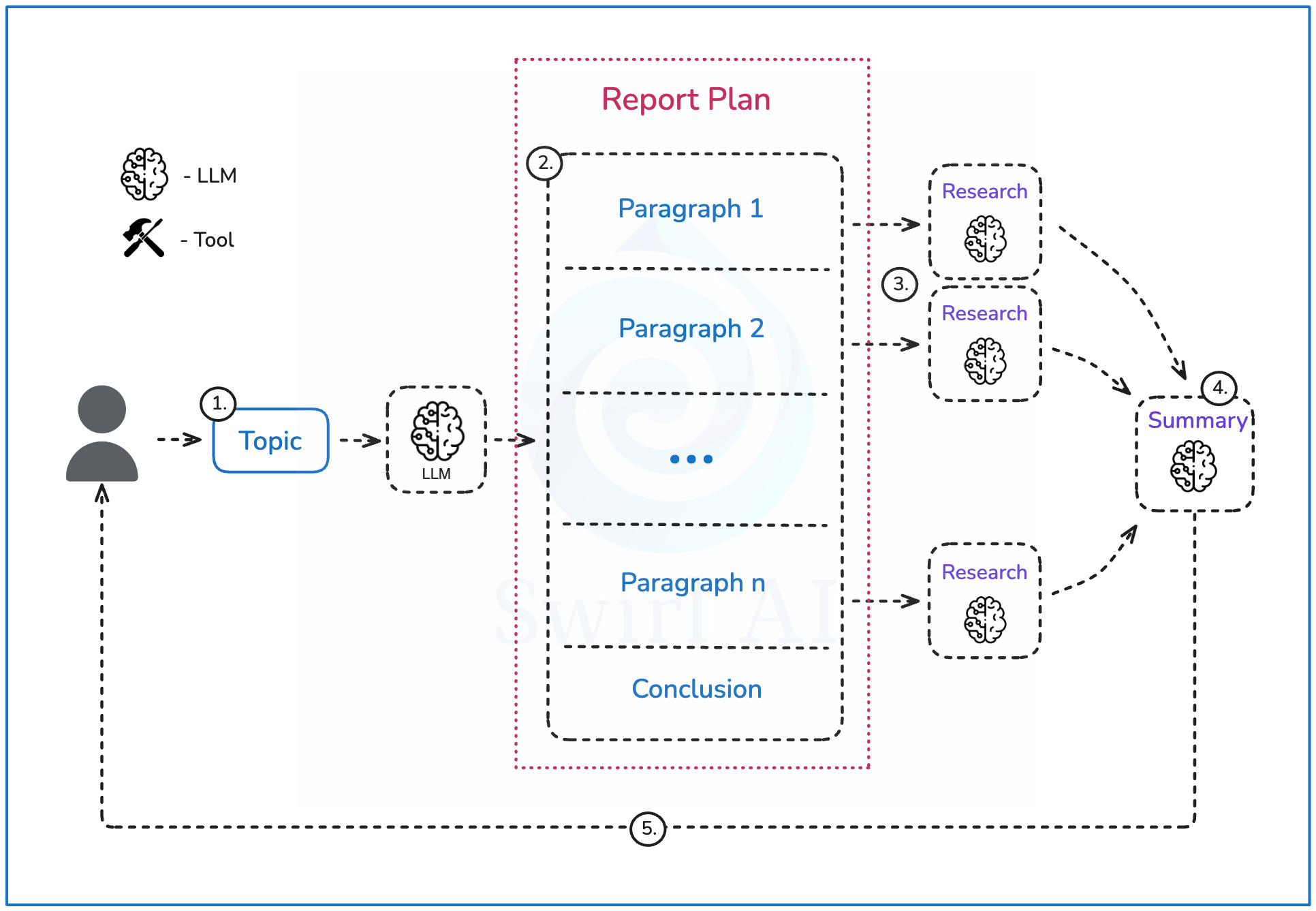
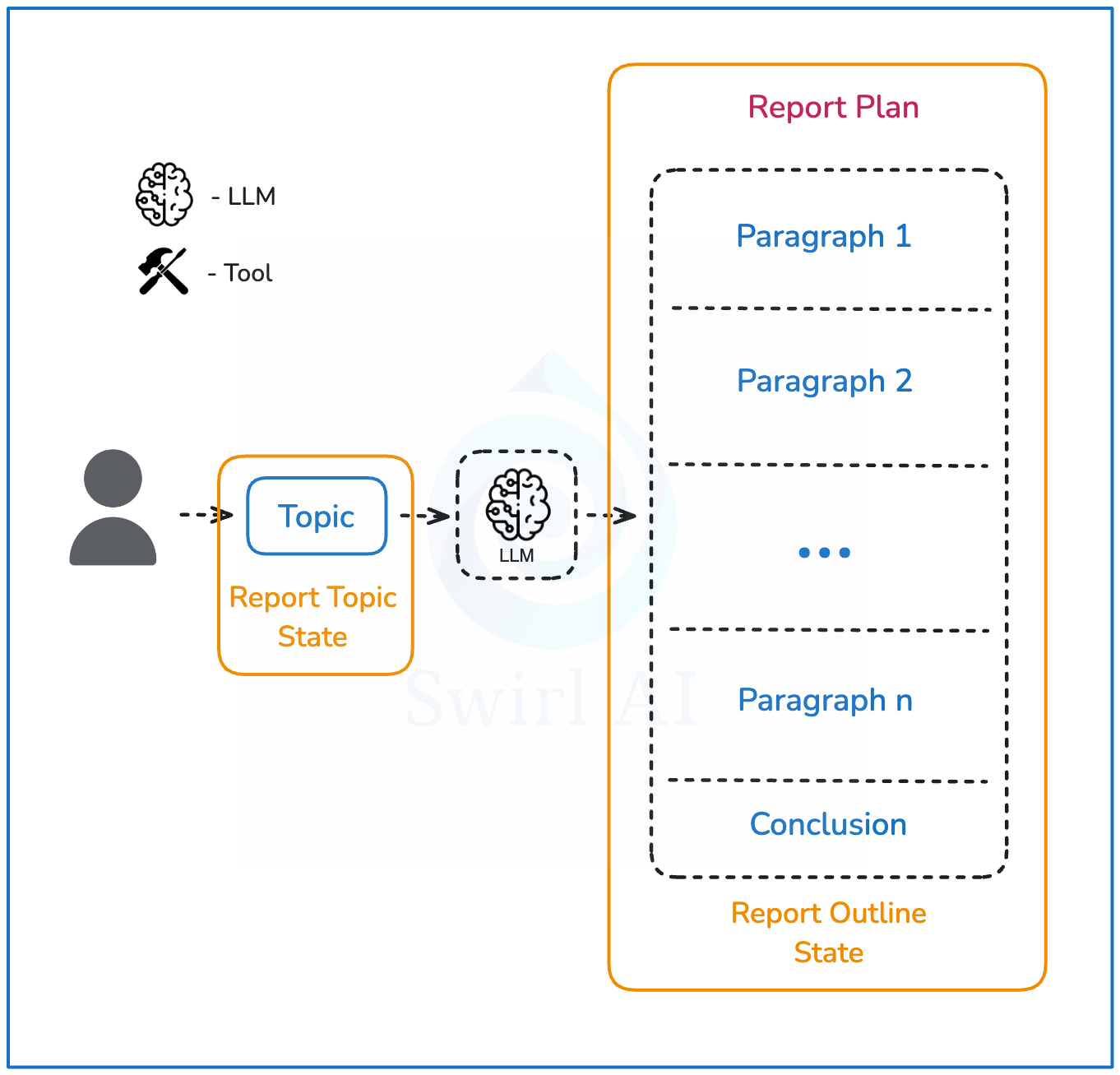
系统架构设计
下图展示了我们将要构建的系统架构及其运行步骤:
1. 用户提供一个需要研究的查询或主题。
2. 大型语言模型(LLM)生成最终报告的大纲,并限制段落数量不超过一定范围。
3. 针对每个段落描述,分别进入研究流程,生成用于报告构建的全面信息集(研究流程的详细描述将在下一部分中展开)。
4. 将所有信息输入总结步骤,构建包含结论在内的最终报告。
5. 以Markdown格式将报告交付给用户。
{kind=link}
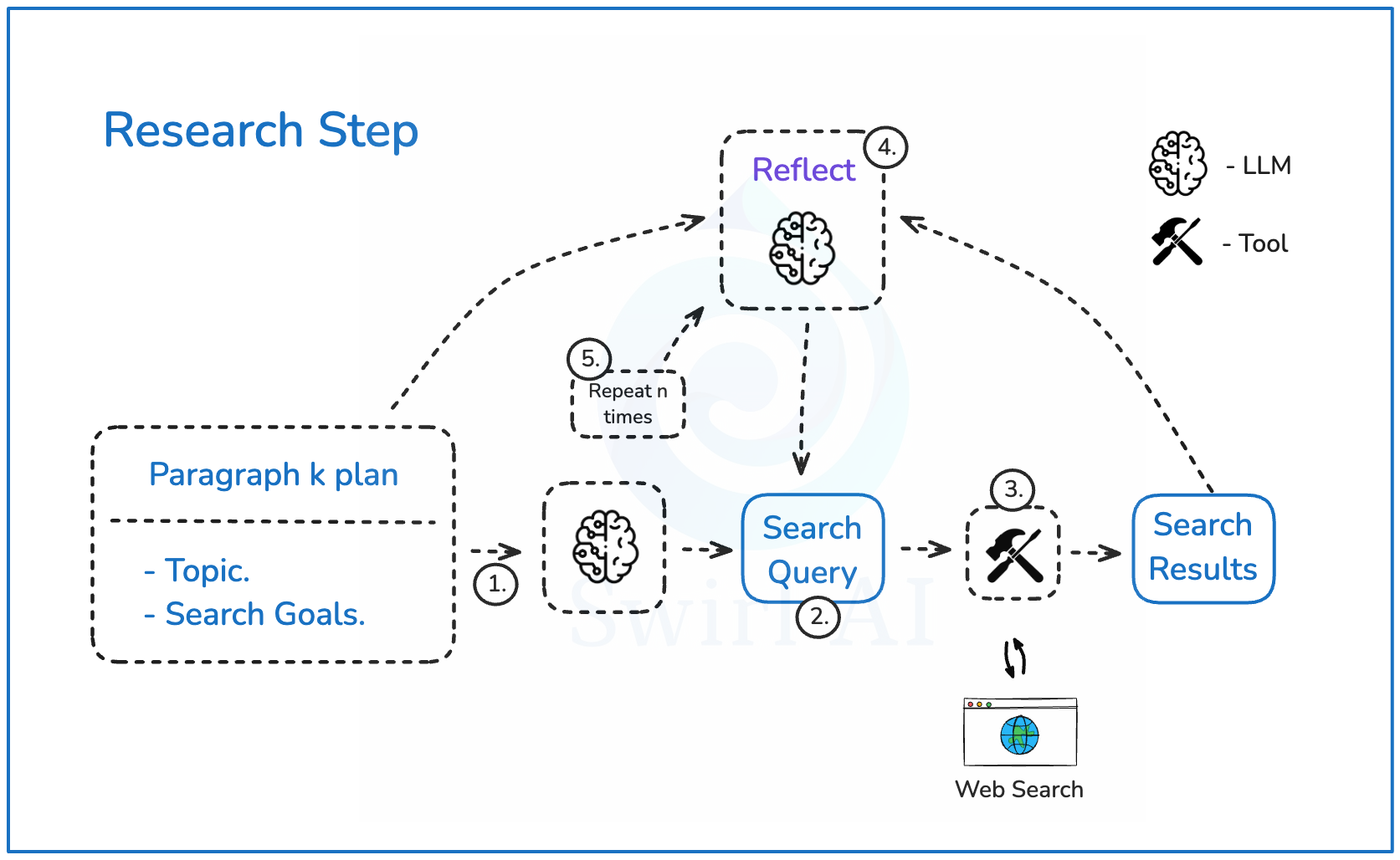
#### 研究步骤详解
以下是研究步骤的具体流程:
1. 拿到每个段落的大纲后,将其传递给LLM,生成网络搜索查询,以尽可能丰富所需信息。
2. LLM输出搜索查询及其背后的推理逻辑。
3. 根据查询执行网络搜索,获取最相关的顶部结果。
4. 将结果传递到反思步骤,LLM将推理是否遗漏了某些细微之处,并尝试提出新的搜索查询以补充初始结果。
5. 重复上述过程n次,力求获取最全面的信息集。
{kind=link}
智能体的实现
在进入实现阶段之前,我们需要进行一些技术准备。如果您尚未完成,可以前往SambaNova云控制台获取API密钥也可以选择其他的大模型厂商(如硅基流动、openrouter等等)。
您可以在这里注册。进入“APIs”选项卡,登录后即可获取密钥,无需添加信用卡信息即可运行本项目。
我们将使用OpenAI客户端来运行API查询。如果尚未安装,请执行以下命令:
pip install openai
在本项目中,我们将使用非精炼版的DeepSeek R1模型,参数规模为6710亿。
确保您的SAMBANOVA_API_KEY已作为环境变量导出,然后在控制台或Notebook中运行以下代码:
import os
import openaiclient = openai.OpenAI(
api_key=os.environ.get("SAMBANOVA_API_KEY"),
base_url="https://preview.snova.ai/v1",
)response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":"You are a helpful assistant"},\
{"role":"user","content":"Tell me something interesting about human species"}],
temperature=1
)
print(response.choices[0].message.content)
您将看到如下输出:
Okay, so I'm trying to ...
The human species is distinguished by the remarkable cognitive abilities of the brain, which underpin an array of unique traits. Our brain's advanced structure and function enable complex thought, language, and social organization. These capabilities have driven innovation, art, and the creation of intricate societies, setting humans apart in their ability to adapt, innovate, and create beyond any other species. This cognitive prowess is the cornerstone of human achievement and our profound impact on the world.
输出中会包含推理标记(reasoning tokens)。虽然观察推理过程有价值,但在我们的系统中,我们只需要最终答案。因此,可以编写一个简单的清理函数,移除
def remove_reasoning_from_output(output):
return output.split("")[-1].strip()
简洁而实用。现在我们已经完成了SambaNova账户的设置,并了解了DeepSeek R1模型的输出结构,接下来我们开始实现深度研究智能体。
实现步骤一:定义系统状态
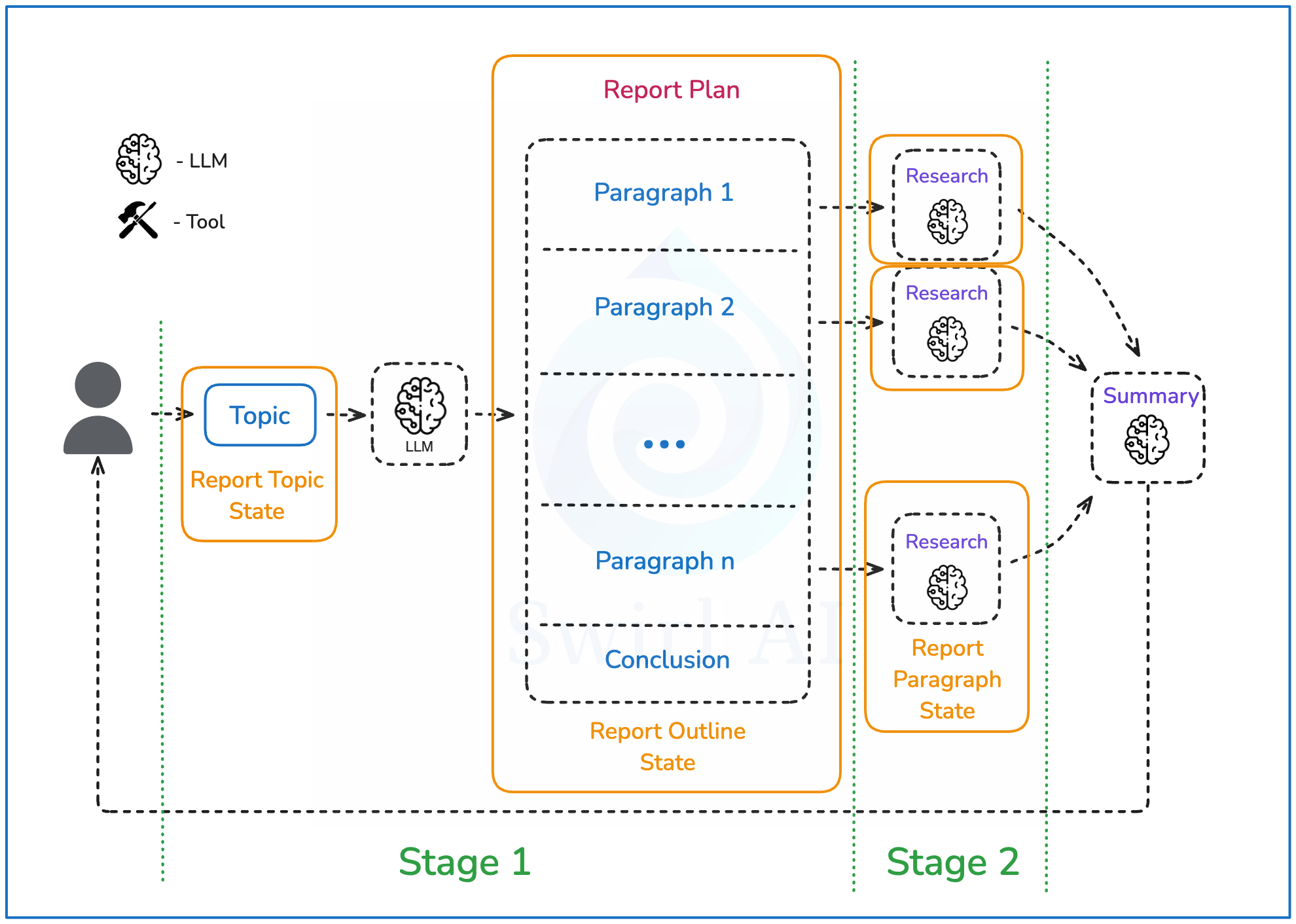
首先,我们需要定义整个系统的状态。这个状态将在智能体运行过程中不断演变,并被系统的不同部分选择性地使用。
我们将状态与智能体系统的各个阶段关联起来:
!架构状态
{kind=link}
- 阶段1(报告结构规划阶段):创建报告大纲,规划报告结构并演变状态。我们从空状态开始,但会将其演变为如下结构(推理将在阶段2中描述):
{
"report_title": "Report Title",
"paragraphs": [
{
"title": "Paragraph Title",
"content": "Paragraph Content",
"research": <...>
},
{
"title": "Paragraph Title",
"content": "Paragraph Content",
"research": <...>
}
]
}
我们使用Python的dataclasses实现上述状态:
from dataclasses import dataclass, field
from typing import List@dataclass
class Paragraph:
title: str = ""
content: str = ""
research: 'Research' = field(default_factory=lambda: Research())
@dataclass
class State:
report_title: str = ""
paragraphs: List[Paragraph] = field(default_factory=list)
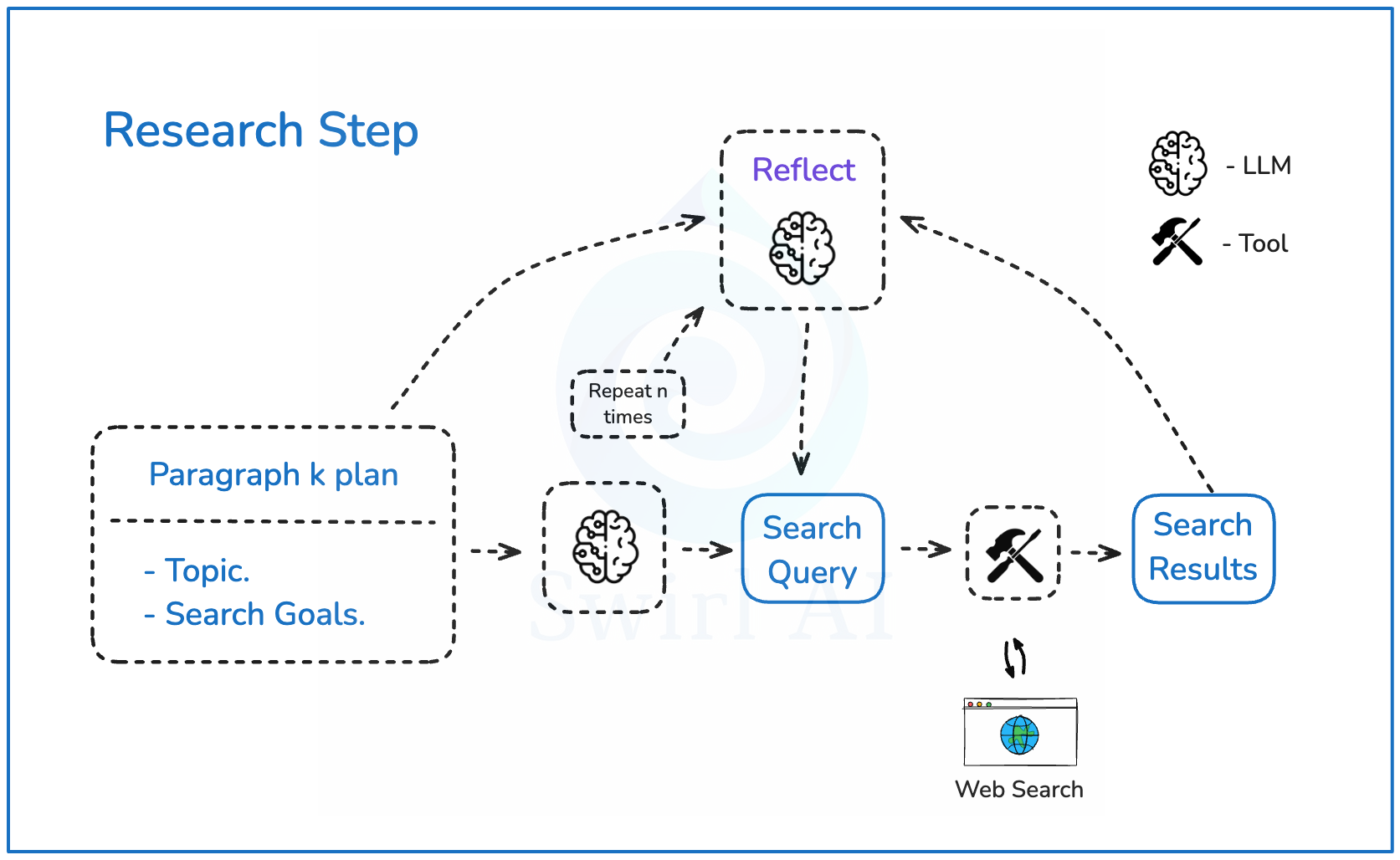
- 阶段2(段落详细研究阶段):对每个段落的状态进行迭代,更新其research字段。我们将为每个段落的研究状态采用以下结构:
{
"search_history": [{"url": "some url", "content": "some content"}],
"latest_summary": "summary of the combined search history",
"reflection_iteration": 1
}
!研究步骤
{kind=link}
- search_history:存储我们执行的所有搜索结果,包括URL和内容,以便去重并在后续报告中引用链接。
- latest_summary:基于所有搜索结果的段落总结,用于反思步骤判断是否需要更多搜索,并传递到总结和报告生成步骤。
- reflection_iteration:追踪当前反思迭代次数,若达到上限则强制停止。
同样,我们可以通过dataclasses实现研究状态:
@dataclass
class Search:
url: str = ""
content: str = ""
@dataclass
class Research:
search_history: List[Search] = field(default_factory=list)
latest_summary: str = ""
reflection_iteration: int = 0
定义好系统状态后,我们接下来需要创建报告大纲。
实现步骤二:创建报告大纲
不同模型版本在输出一致性上可能有所差异。经过多次实验,以下提示词(Prompt)在DeepSeek-R1模型上能够持续生成格式良好的输出:
import jsonoutput_schema_report_structure = {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"}
}
}
}SYSTEM_PROMPT_REPORT_STRUCTURE = f"""
You are a Deep Research assistant. Given a query, plan a structure for a report and the paragraphs to be included.
Make sure that the ordering of paragraphs makes sense.
Once the outline is created, you will be given tools to search the web and reflect for each of the sections separately.
Format the output in json with the following json schema definition:
Title and content properties will be used for deeper research.
Make sure that the output is a json object with an output json schema defined above.
Only return the json object, no explanation or additional text.
"""
{kind=link}
运行以下示例查询:
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":SYSTEM_PROMPT_REPORT_STRUCTURE},\
{"role":"user","content":"Tell me something interesting about human species"}],
temperature=1
)
print(response.choices[0].message.content)
您可能会得到如下输出:
[
{
"title": "Introduction to Human Adaptability",
"content": "Humans possess a unique capacity for adaptability, which has been crucial in their survival and dominance across various environments. This introduction sets the stage for exploring the different facets of human adaptability."
},
...
{
"title": "Conclusion: The Role of Adaptability in Human Survival",
"content": "Adaptability has been a cornerstone of human survival and evolution, enabling us to face challenges and explore new frontiers, offering insights into future potential."
}
]
输出中可能包含json代码块标记,需要将其清理并转换为Python字典:
def clean_json_tags(text):
return text.replace("", "")report_structure = json.loads(clean_json_tags(remove_reasoning_from_output(response.choices[0].message.content)))
STATE = State()
for paragraph in report_structure:
STATE.paragraphs.append(Paragraph(title=paragraph["title"], content=paragraph["content"]))
实现步骤三:网络搜索工具
我们使用Tavily执行网络搜索。您可以在这里获取您的令牌。
搜索工具的实现非常简单:
python
from tavily import TavilyClientdef tavily_search(query, include_raw_content=True, max_results=5):
tavily_client = TavilyClient(api_key=os.getenv("TAVILY_API_KEY"))
return tavily_client.search(query,
include_raw_content=include_raw_content,
max_results=max_results)
调用该函数将返回最多个搜索结果,每个结果包含标题、URL、内容摘要以及可能的完整页面内容(我们需要完整内容以获得最佳结果)。获取搜索结果后,我们可以直接将其添加到全局状态中,无需再次调用LLM,但需要确保更新正确的段落索引。
以下函数可以根据Tavily搜索结果、段落索引和状态对象正确更新状态:
python
def update_state_with_search_results(search_results, idx_paragraph, state):
for search_result in search_results["results"]:
search = Search(url=search_result["url"], content=search_result["raw_content"])
state.paragraphs[idx_paragraph].research.search_history.append(search)
return state
我们将追加到搜索历史中。和reflection_iteration字段需要LLM进一步处理,将在后续“反思”部分讨论。这一工具的目的是为后续研究提供丰富的数据支持。实现步骤四:规划搜索
以下提示词能持续产生较好的结果,用于规划首次搜索:
python
input_schema_first_search = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"}
}
}output_schema_first_search = {
"type": "object",
"properties": {
"search_query": {"type": "string"},
"reasoning": {"type": "string"}
}
}
SYSTEM_PROMPT_FIRST_SEARCH = f"""
You are a Deep Research assistant. You will be given a paragraph in a report, its title and expected content in the following json schema definition:
{json.dumps(input_schema_first_search, indent=2)}
You can use a web search tool that takes a 'search_query' as parameter.
Your job is to reflect on the topic and provide the most optimal web search query to enrich your current knowledge.
Format the output in json with the following json schema definition:
Make sure that the output is a json object with an output json schema defined above.
Only return the json object, no explanation or additional text.
"""
在输出模式中要求推理内容,以促使模型对查询进行更多思考。虽然对于推理模型来说这可能有些多余,但对于普通LLM可能是个好主意。现在,我们已经有了规划好的段落列表及其内容和描述,可以直接将步骤三的输出输入到提示词中:
python
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content":SYSTEM_PROMPT_FIRST_SEARCH},\
{"role":"user","content":json.dumps(STATE.paragraphs[0])}],
temperature=1
)print(response.choices[0].message.content)
首次搜索计划如下:
json
{"search_query": "Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits"}
我们可以直接将该查询输入搜索工具:
python
tavily_search("Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits")
实现步骤五:首次总结
首次总结与后续的反思步骤不同,因为此时尚无内容可供反思,本步骤将生成可供反思的内容。以下提示词效果较好:
python
input_schema_first_summary = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"},
"search_query": {"type": "string"},
"search_results": {
"type": "array",
"items": {"type": "string"}
}
}
}output_schema_first_summary = {
"type": "object",
"properties": {
"paragraph_latest_state": {"type": "string"}
}
}
SYSTEM_PROMPT_FIRST_SUMMARY = f"""
You are a Deep Research assistant. You will be given a search query, search results and the paragraph of a report that you are researching following json schema definition:
{json.dumps(input_schema_first_summary, indent=2)}
Your job is to write the paragraph as a researcher using the search results to align with the paragraph topic and structure it properly to be included in the report.
Format the output in json with the following json schema definition:
Make sure that the output is a json object with an output json schema defined above.
Only return the json object, no explanation or additional text.
"""
应以以下格式为LLM提供数据:
json
{
"title": "Title",
"content": "Content",
"search_query": "Search Query",
"search_results": []
}
我们可以从已有数据构建该JSON:
python
search_results = tavily_search("Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits")input_data = {
"title": "Introduction to Human Adaptability",
"content": "Humans possess a unique capacity for adaptability, which has been crucial in their survival and dominance across various environments. This introduction sets the stage for exploring the different facets of human adaptability.",
"search_query": "Homo sapiens characteristics basic biological traits cognitive abilities behavioral traits",
"search_results": [result["raw_content"][0:20000] for result in search_results["results"] if result["raw_content"]]
}
response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_FIRST_SUMMARY},\
{"role":"user","content":json.dumps(input_data)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))
您将得到如下输出:
json
{
"paragraph_latest_state": "Homo sapiens, the species to which modern humans belong, represents a unique and fascinating chapter in the evolutionary narrative of life on Earth. As the only living species within the Homo genus, Homo sapiens are distinguished by a combination of biological, cognitive, and behavioral traits that set us apart from other primates and extinct human relatives. Our biological characteristics include a large and structurally advanced brain, with a neocortex that has expanded significantly compared to our evolutionary ancestors. This anatomical development has enabled exceptional cognitive abilities, such as complex problem-solving, abstract thought, and the capacity for language and symbolic communication. Behaviorally, Homo sapiens exhibit sophisticated social structures, cultural practices, and technological innovations, which have been critical in shaping our ability to adapt to diverse environments and thrive as a species. These traits collectively underscore the intricate interplay between biology and behavior that defines the human condition."
}
我们将用此内容更新字段,并在后续“反思”部分继续基于段落总结的最新状态进行改进。这一总结的目的是为报告奠定基础内容。实现步骤六:反思
有了报告段落内容的最新状态后,通过提示LLM反思文本,寻找可能遗漏的角度,以改进内容。以下提示词效果很好:
python
input_schema_reflection = {
"type": "object",
"properties": {
"title": {"type": "string"},
"content": {"type": "string"},
"paragraph_latest_state": {"type": "string"}
}
}output_schema_reflection = {
"type": "object",
"properties": {
"search_query": {"type": "string"},
"reasoning": {"type": "string"}
}
}
SYSTEM_PROMPT_REFLECTION = f"""
You are a Deep Research assistant. You are responsible for constructing comprehensive paragraphs for a research report. You will be provided paragraph title and planned content summary, as well as the latest state of the paragraph that you have already created, all in the following json schema definition:
{json.dumps(input_schema_reflection, indent=2)}
You can use a web search tool that takes a 'search_query' as a parameter.
Your job is to reflect on the current state of the paragraph text and think if you haven't missed some critical aspect of the topic and provide the most optimal web search query to enrich the latest state.
Format the output in json with the following json schema definition:
Make sure that the output is a json object with an output json schema defined above.
Only return the json object, no explanation or additional text.
"""
输入数据样例:
python
input_data = {
"paragraph_latest_state": "Homo sapiens, the species to which modern humans belong, represents a unique and fascinating chapter in the evolutionary narrative of life on Earth. As the only living species within the Homo genus, Homo sapiens are distinguished by a combination of biological, cognitive, and behavioral traits that set us apart from other primates and extinct human relatives. Our biological characteristics include a large and structurally advanced brain, with a neocortex that has expanded significantly compared to our evolutionary ancestors. This anatomical development has enabled exceptional cognitive abilities, such as complex problem-solving, abstract thought, and the capacity for language and symbolic communication. Behaviorally, Homo sapiens exhibit sophisticated social structures, cultural practices, and technological innovations, which have been critical in shaping our ability to adapt to diverse environments and thrive as a species. These traits collectively underscore the intricate interplay between biology and behavior that defines the human condition.",
"title": "Introduction",
"content": "The human species, Homo sapiens, is one of the most unique and fascinating species on Earth. This section will introduce the basic characteristics of humans and set the stage for exploring interesting aspects of the species."
}response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_REFLECTION},\
{"role":"user","content":json.dumps(input_data)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))
输出样例:
json
{
"search_query": "Recent research on Homo sapiens evolution, interaction with other human species, and factors contributing to their success",
"reasoning": "The current paragraph provides a good overview of Homo sapiens' characteristics but lacks depth on evolutionary history and interactions with other species. Including recent research on these topics will enhance the paragraph's comprehensiveness and provide up-to-date information."
}
现在我们可以运行查询,将新结果追加到段落状态中,并结合新结果与段落的最新状态。反思步骤通过重新评估已有信息,帮助我们发现可能遗漏的关键点,从而提升研究的全面性和准确性。实现步骤七:用反思搜索结果丰富段落状态
执行反思步骤的搜索查询后:
python
search_results = tavily_search("Recent research on Homo sapiens evolution, interaction with other human species, and factors contributing to their success")
我们可以用以下方式更新段落的搜索状态:
python
update_state_with_search_results(search_results, idx_paragraph, state)
我们将重复执行步骤六和步骤七指定次数,以确保内容的深度和广度。实现步骤八:总结并生成报告
对步骤二中规划的每个段落执行步骤四到步骤七。一旦所有段落的最终状态准备就绪,我们就可以将所有内容整合在一起,使用LLM生成格式优美的Markdown文档。如果结论段落不存在,则从其他段落的最新状态中添加到报告的末尾。以下是提示词:
python
input_schema_report_formatting = {
"type": "array",
"items": {
"type": "object",
"properties": {
"title": {"type": "string"},
"paragraph_latest_state": {"type": "string"}
}
}
}SYSTEM_PROMPT_REPORT_FORMATTING = f"""
You are a Deep Research assistant. You have already performed the research and constructed final versions of all paragraphs in the report.
You will get the data in the following json format:
{json.dumps(input_schema_report_formatting, indent=2)}
Your job is to format the Report nicely and return it in Markdown.
If a Conclusion paragraph is not present, add it to the end of the report from the latest state of the other paragraphs.
"""
执行以下代码:
python
report_data = [{"title": paragraph.title, "paragraph_latest_state": paragraph.research.latest_summary} for paragraph in STATE.paragraphs]response = client.chat.completions.create(
model="DeepSeek-R1",
messages=[{"role":"system","content": SYSTEM_PROMPT_REPORT_FORMATTING},\
{"role":"user","content":json.dumps(report_data)}],
temperature=1
)
print(remove_reasoning_from_output(response.choices[0].message.content))``
至此,您已完成了一份关于所提供主题的深度研究报告。
总结
恭喜您成功从零开始构建了一个深度研究智能体。构建深度研究智能体不仅需要技术知识,更需要不断的实践和创新。希望本文能为您提供一些启发!
如需查看更规范的实现代码,请访问我的GitHub仓库:
另外,还有许多细节可以优化以提升系统的稳定性:
- 推理模型在结构化输出方面表现不佳,难以保证一致的JSON格式输出。
- 针对系统架构中的不同任务,可以考虑使用不同的模型,推理模型主要在报告结构规划的首步中最为关键。
- 网络搜索和结果排序的方式有许多改进空间。
- 反思步骤的数量可以设置为动态,由LLM决定是否需要更多步骤。
- 可以在报告中为每个段落提供搜索时使用的链接作为参考。