今天想和大家分享的是如何基于DeepSeek、Tavily打造本地deep research研究助手。
主要使用到的工具有:
* Deep Research Web UI : 这是一个Deep research可视化开源工具,它可以把研究过程用树状图展示出来,通过配置大模型和搜索工具API可以在浏览器生成专业的行业研究报告。
* 大语言模型 : 这里采用DeepSeek R1作为深度研究的推理模型,也支持其他像chatgpt、claude、QwQ 32B等等
* 搜索工具: 可以选择Tavily或者Firecrawl。这里使用Tavily来做演示,Tavily是一个搜索引擎,由斯坦福的团队开发,每月有1000次的免费额度。
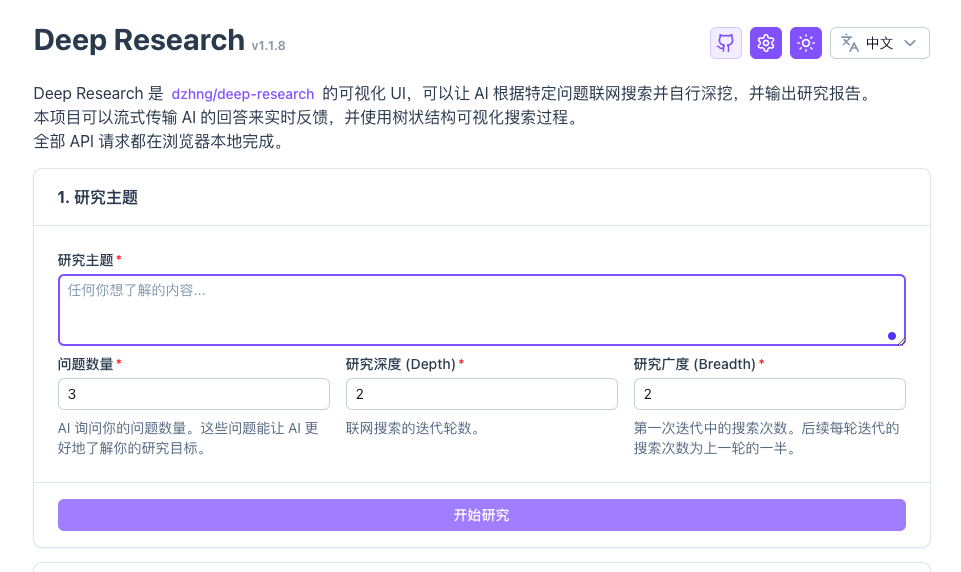
接下来,我将通过以下几个步骤来介绍如何打造本地化研究助手。
本地部署Deep Research Web UI
这个工具是https://github.com/dzhng/deep-research 的可视化版本,主要包含以下特色:
* 隐私安全:所有配置和 API 请求均在浏览器端完成
* 实时反馈:流式传输 AI 响应并在界面实时展示
* 搜索可视化:使用树状结构展示研究过程,支持使用英文搜索词
* 支持导出 PDF:将最终研究报告导出为 Markdown 和 PDF 格式
* 多模型支持:底层使用纯提示词而非结构化输出等新特性,兼容更多大模型供应商
使用本地部署的一个好处就是隐私安全,Deep Research Web UI本地部署支持docker和pnpm两种方式,这里以docker部署来做演示:
第一步,从github克隆deep-research-web-ui项目的源代码;
git clone https://github.com/AnotiaWang/deep-research-web-ui
第二步,进入deep-research-web-ui目录,build docker镜像;
cd deep-research-web-ui
docker build -t deep-research-web .
第三步,运行docker容器镜像,打开浏览器输入localhost:3000即可访问deep-research页面
docker run -p 3000:3000 --name deep-research-web -d deep-research-web
配置大语言模型
这里我使用的是无问芯穹AI平台(网址:https://cloud.infini-ai.com)的DeepSeek R1版本,目前免费使用。
* 进入首页完成注册之后,点击模型广场,选择deepseek r1
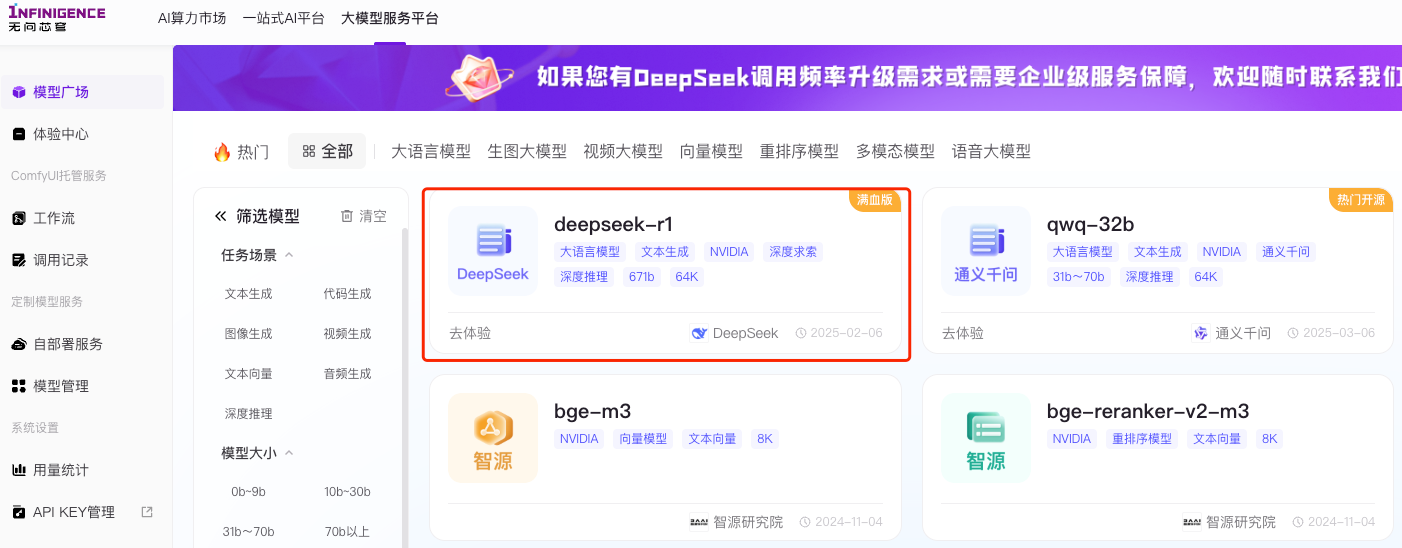
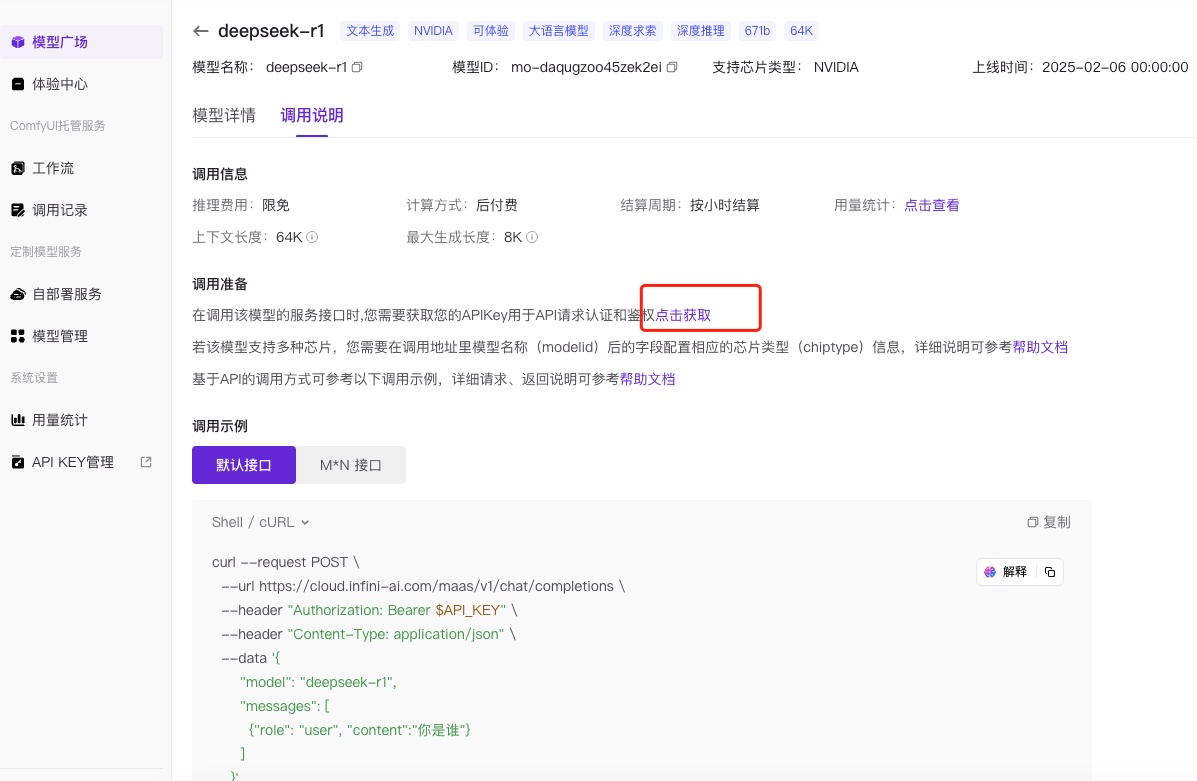
* 接下来点击进入详细页,申请api key
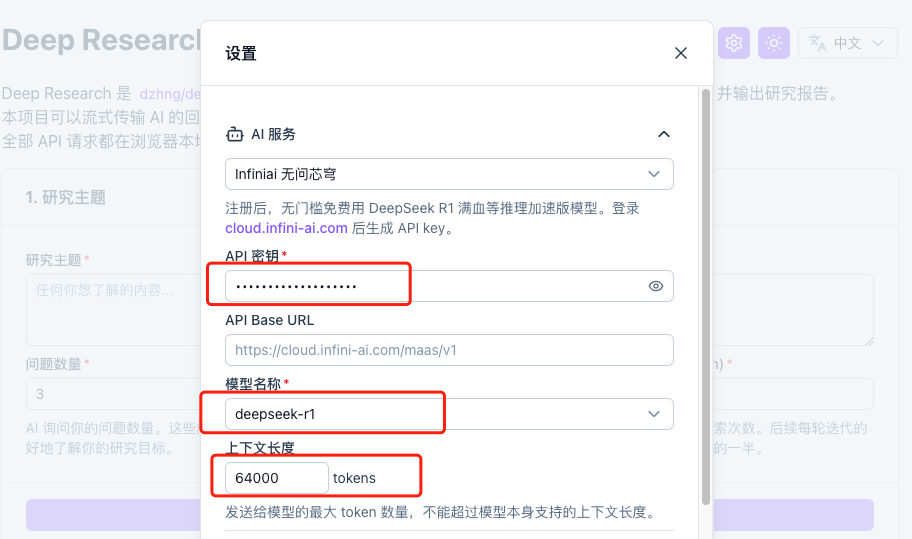
* 然后访问localhost:3000,点击右上角的设置按钮进行API配置,填入api key,模型上下文长度输入64000(注:无问芯穹deepseek r1版本支持的最大上下文长度为64k)
配置搜索工具
首先去Tavily官网https://app.tavily.com申请一个免费的API密钥。
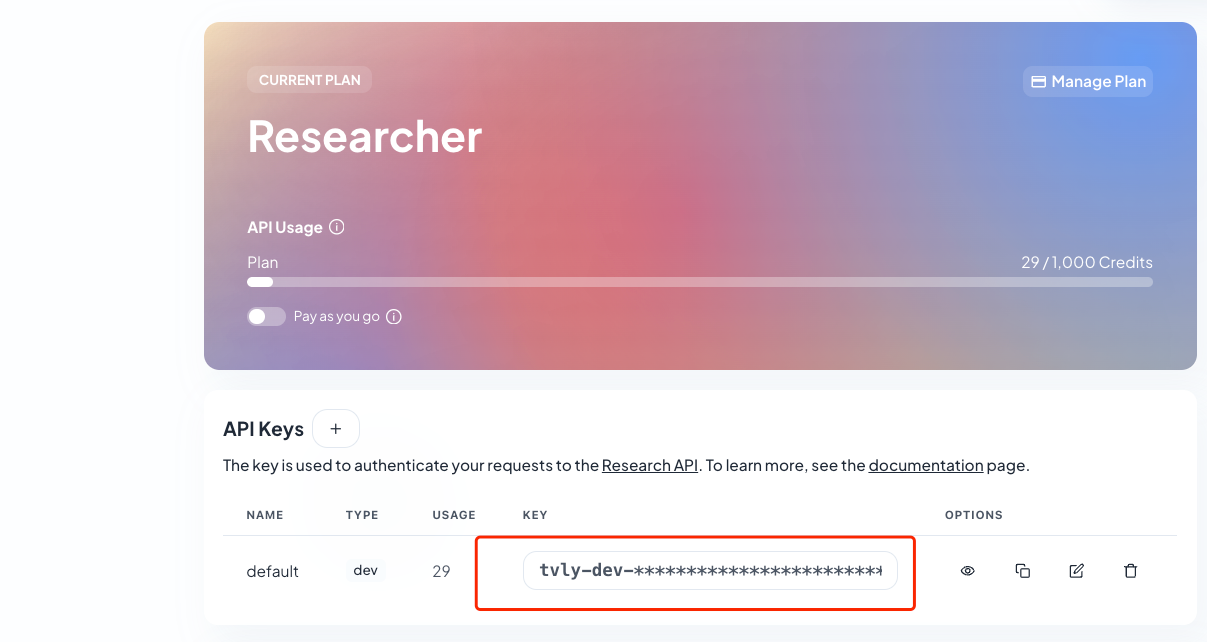
这一步回到localhost:3000,点击右上角的设置,将上面获取到的Tavily API KEY设置到联网搜索服务中。
这样,所有的相关配置就已经完成了,下面通过一个具体案例展示一下研究效果
开始深度研究
* 首先我们打开localhost:3000,输入你想研究的问题。 比如,这里输入“小米汽车”,并点击开始研究:
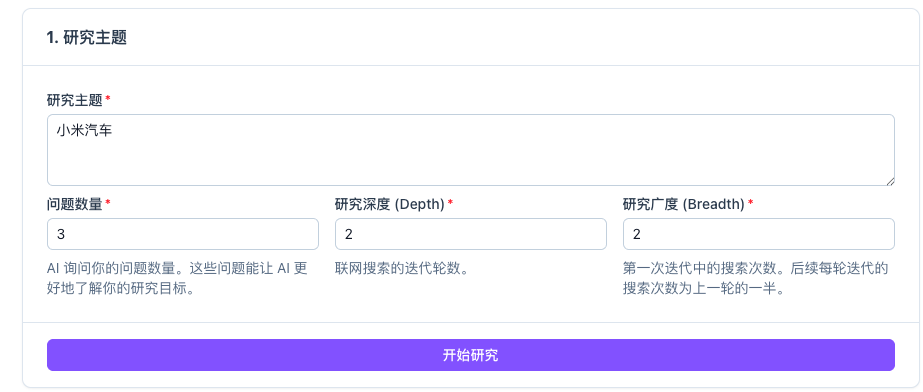
注意: 这里有三个参数,其中问题数量是指下一步【模型反馈】中AI进一步和你确认与研究主题相关的细节;研究广度(建议:3-10,这里设置为4);研究深度(建议:1-5,默认值:2);研究广度和研究深度的值不宜设置的过大,否则会超过大语言模型支持的最大上下文长度64k,从而导致报错。
* 系统会自动把研究主题拆解成多个小问题进行分析,来帮助明确研究方向。
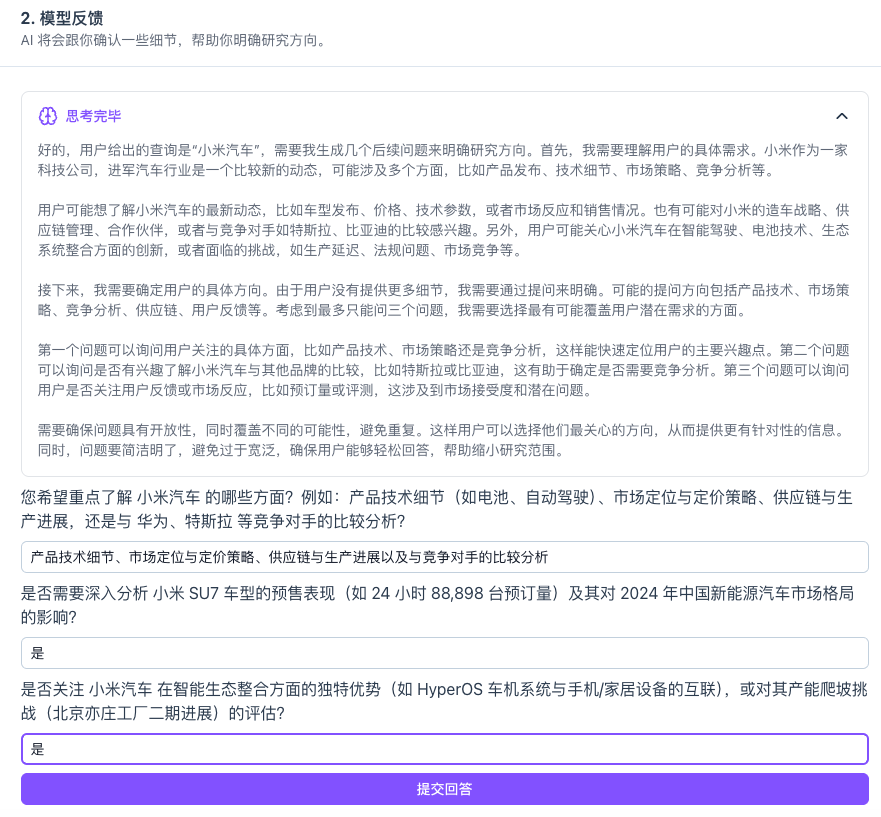
这里,我们可以看到模型基于研究主题进行思考的过程,点击提交回答,模型将会根据上述信息联网搜索并自动迭代。
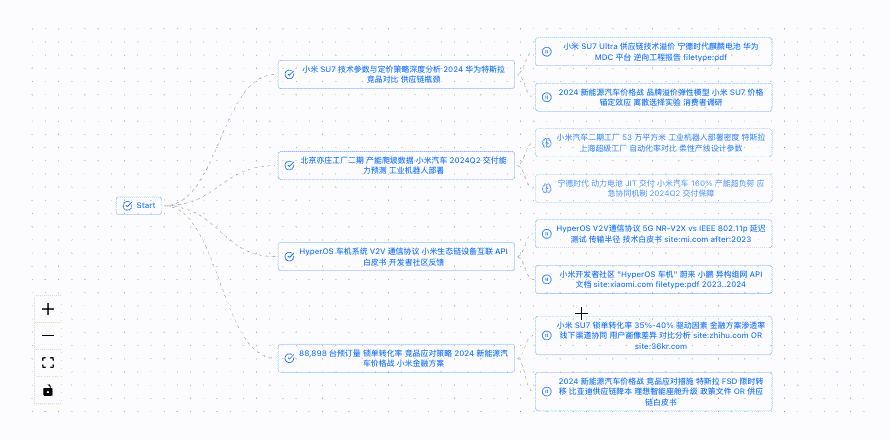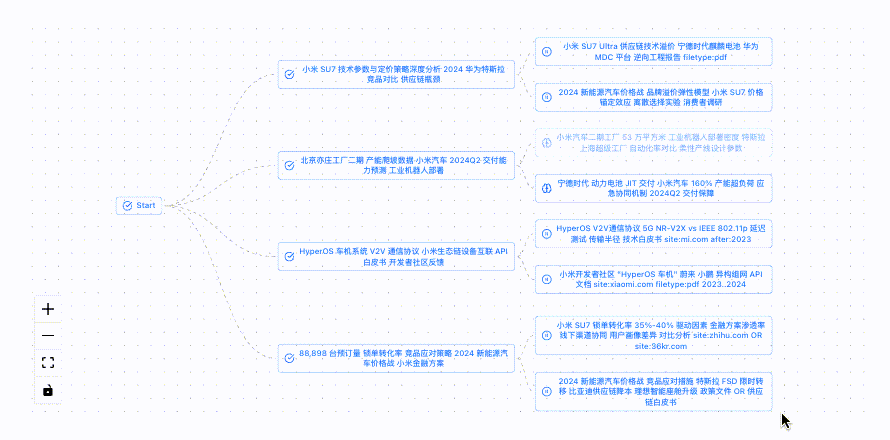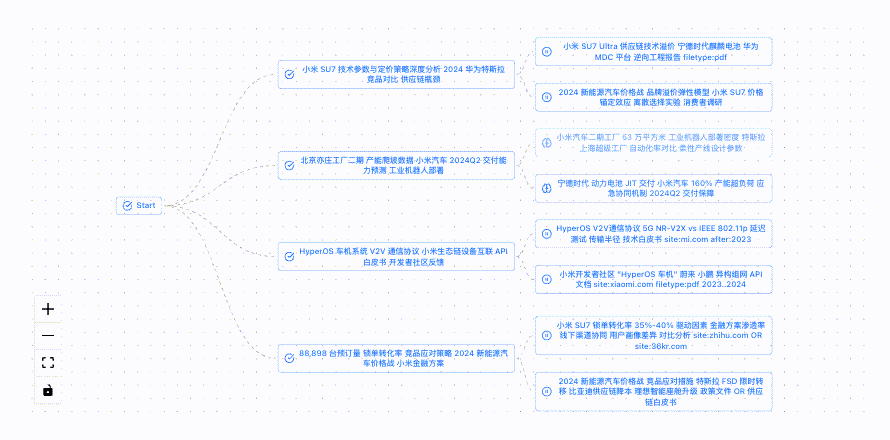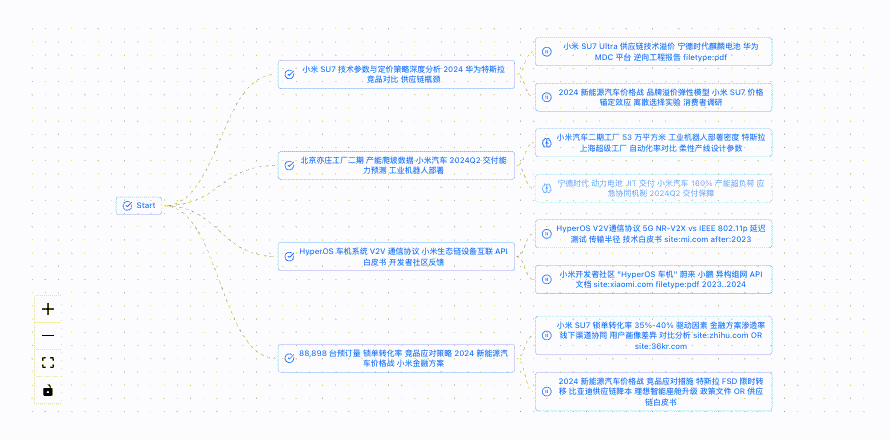
最终,模型会结合搜索到的相关信息生成包含调查结果和来源的详细研究报告,并支持markdown和pdf两种格式下载。(研究过程中可以随时暂停和调整)

这里,我用mermaid把整个deep research的过程画了一下,如图所示:
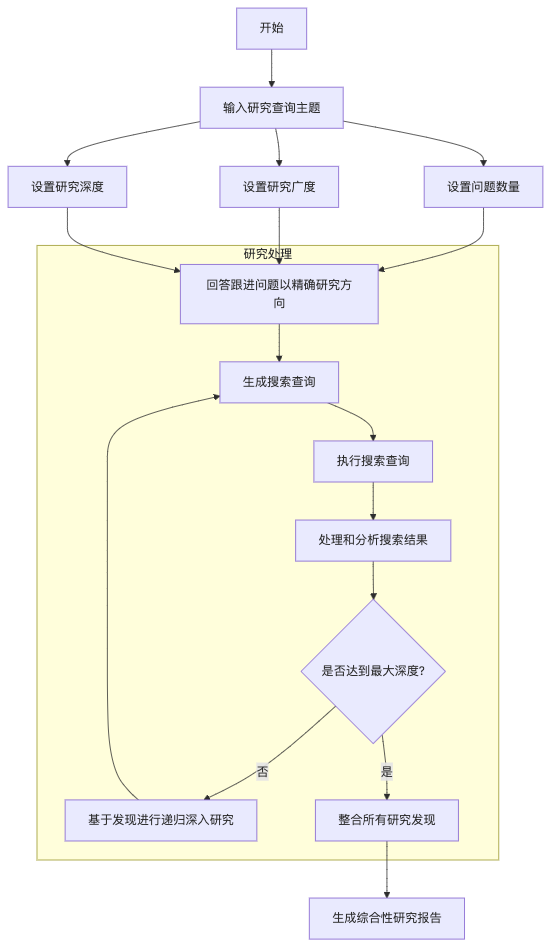
通过上面这个案例演示可以看到,基于开源大模型deepseek r1+搜索工具Tavily的组合展现了专业的研究能力,简化了我们平台在日常工具中繁琐的信息收集与分析流程,极大的提高了效率。
感兴趣的小伙伴可以试一试这个研究助手,欢迎点赞、转发,今天的分享就这么多啦。