缓存是开发者需要掌握的基本概念之一。其核心目标是:提升系统性能,减轻主数据存储(如数据库)的负担。缓存能显著加快数据访问速度,并保护后端免受重复请求的冲击。
五大缓存策略详解
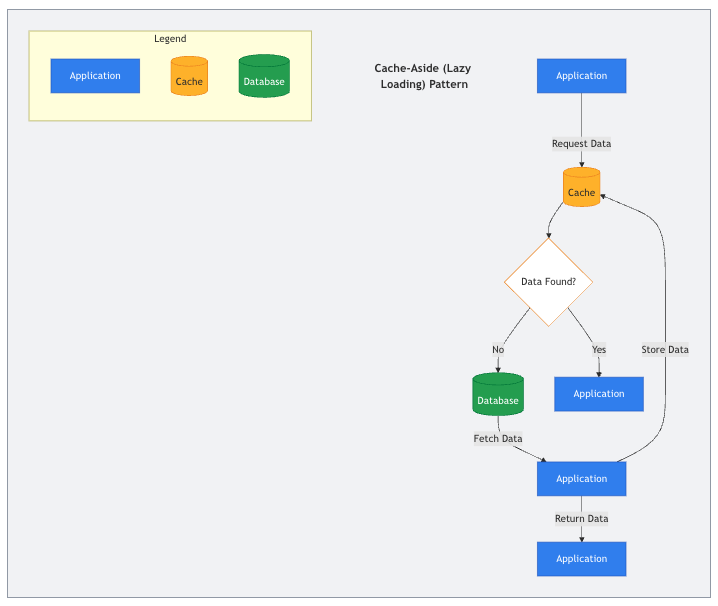
1. 缓存旁路(Cache-Aside,也称按需加载)
缓存旁路(Cache-Aside)是最常见的缓存策略之一。在这种模式下,应用程序代码负责管理缓存。读取数据时,应用首先检查缓存中是否存在目标数据。如果命中缓存(cache hit),数据会立即返回;如果未命中(cache miss),应用则从主数据源(如数据库)获取数据,存入缓存以备下次使用,然后返回数据。
举个例子,假设要获取用户ID为123的个人资料页面:应用先检查缓存中的user:123。如果未找到,就查询数据库,将结果存入缓存的user:123位置,再返回数据。
适用场景:
- 读操作占主导的场景。
- 偶尔的数据过期可以接受(即数据库更新后缓存未及时失效)。
- 希望缓存交互逻辑简单,易于在应用中实现。
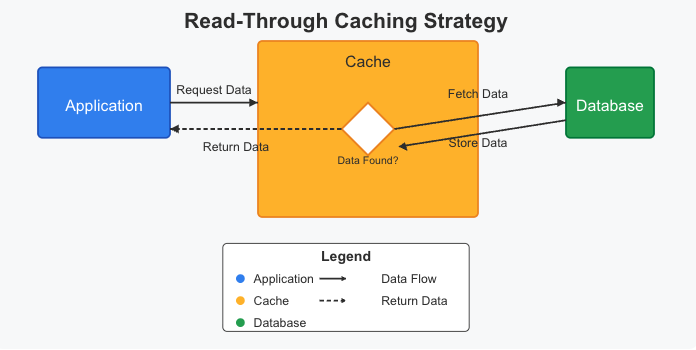
2. 读穿透(Read-Through)
在读穿透策略中,应用读取数据时仅与缓存交互,将缓存视为主要数据源。关键在于:如果缓存中没有所需数据(即未命中),缓存会自动从数据库获取数据,存储后返回给应用。这大大简化了应用代码,因为读取时无需直接处理数据库逻辑。
想象一个商品目录服务,使用配置了CacheLoader的缓存库。应用只需调用cache.get("product:xyz"),缓存系统会在未命中时自动处理数据库交互。
适用场景:
- 读操作频繁的场景。
- 希望将数据获取逻辑从主应用流程中抽象出来。
- 使用的缓存工具或服务(如某些库或托管服务)支持自动数据加载功能。
3. 写穿透(Write-Through)
写穿透策略的核心是数据一致性。应用在写入或更新数据时,同时更新缓存和数据库。只有当两者都成功确认写入后,操作才算完成。这确保了缓存与数据库始终保持一致,降低了返回过期数据的风险。
例如,用户更改邮箱地址这种关键更新就很适合此策略。应用会确保新邮箱同时保存到缓存和数据库。写入延迟可能较高,因为要等待两次操作完成。
适用场景:
- 数据一致性至关重要,缓存与数据库之间不能有差异。
- 可以接受写入性能略微下降的折衷。

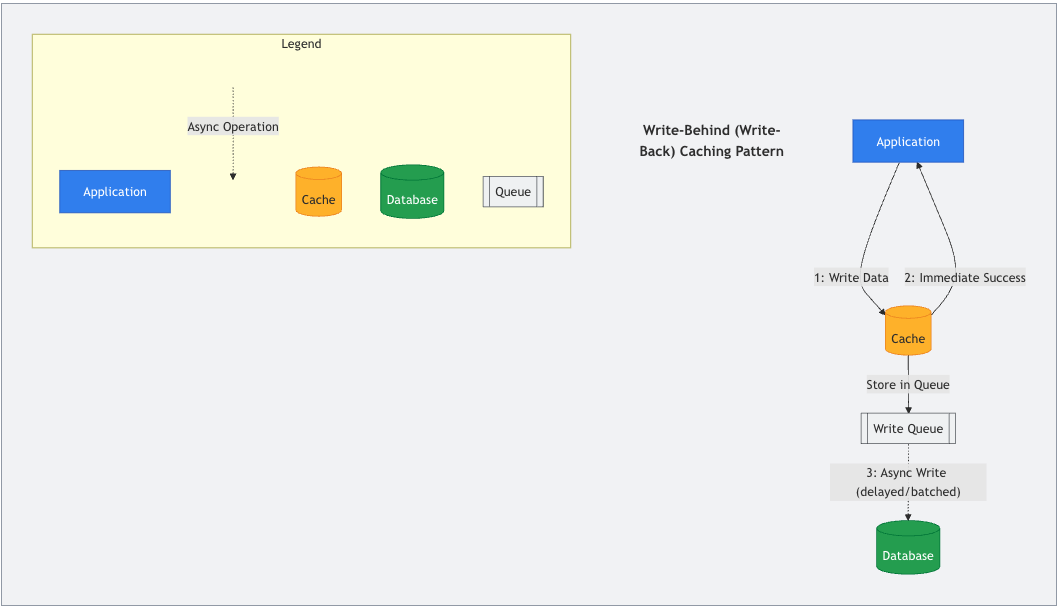
4. 写后(Write-Behind,也称Write-Back)
当追求极致的写入速度时,写后策略可能是最佳选择。在这种模式下,应用只写入缓存,缓存会几乎立即确认写入成功。随后,缓存会异步地将数据写入数据库,通常会有短暂延迟或批量处理多个写入操作。这从应用的角度显著提升了写入性能。
这种策略非常适合高频更新的场景,比如浏览计数、社交媒体点赞或实时游戏分数,速度是关键。然而,风险在于:如果缓存在数据持久化到数据库之前发生故障,数据可能会丢失。
适用场景:
- 写入性能是首要考量。
- 应用会产生大量突发写入。
- 可以接受缓存故障时少量数据丢失的风险。
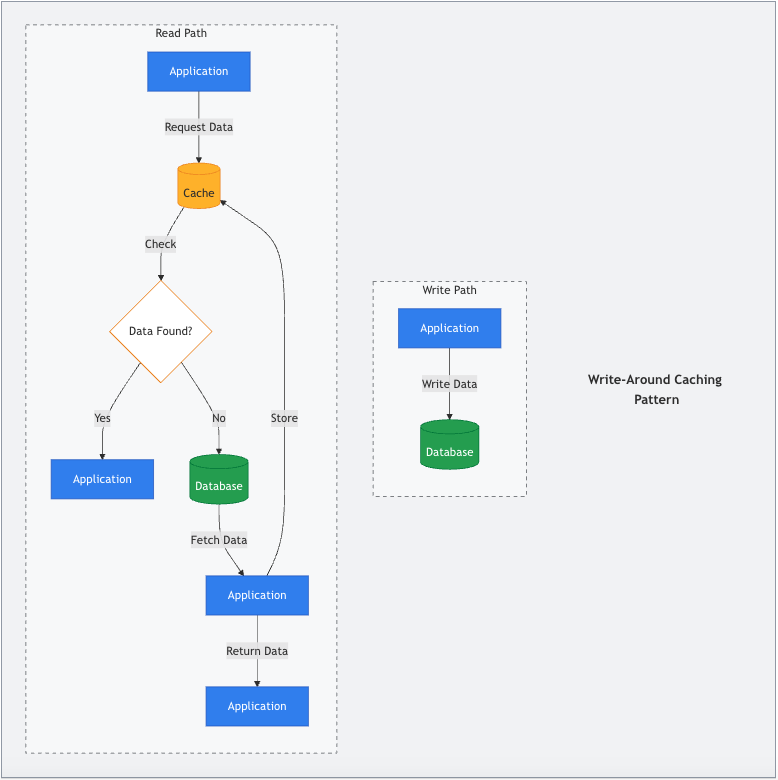
5. 写绕过(Write-Around)
在某些情况下,写入时涉及缓存可能毫无必要甚至有害。写绕过策略通过让应用直接写入数据库,完全绕过缓存来解决这一问题。数据只有在后续读取时才会进入缓存(通常结合缓存旁路模式进行读取)。
例如,批量数据导入或密集日志记录。直接写入数据库可以避免缓存被不常访问或不紧急的数据淹没,让缓存专注于存储更热门、更相关的数据。
适用场景:
- 写入操作频繁,但写入后短期内不太可能读取。
- 希望避免缓存被“冷数据”污染。
如何选择合适的策略?
没有一种策略适用于所有情况。选择缓存策略需根据应用的具体需求进行权衡:
| 策略 | 读取速度 | 写入速度 | 一致性 | 缓存复杂度 |
|---------------|----------|----------|----------|------------|
| 缓存旁路 | 快 | 一般 | 中等 | 手动管理 |
| 读穿透 | 快 | 一般 | 中等 | 抽象化 |
| 写穿透 | 快 | 较慢 | 高 | 较高 |
| 写后 | 快 | 快 | 低-中等 | 较高 |
| 写绕过 | 一般 | 快 | 中等 | 简单 |
🧠 小测试:实时排行榜服务设计
请仔细阅读以下场景,并选择最合适的缓存策略。答案和解释在下方。
假设正在为一个移动游戏设计实时排行榜服务,每天有数百万活跃用户。每当玩家完成比赛后,系统会更新他们的分数。更新操作非常频繁,而且必须快速,以便玩家能立即看到自己的排名变化。偶尔可能会丢失分数更新(例如玩家在更新中途关闭应用),但系统不能因为这些极少数异常情况而变慢。最终,所有分数都需要持久化到数据库中,用于长期分析。
针对分数更新逻辑,以下哪种缓存策略最合适?
A) 缓存旁路 – 应用直接读写数据库,并手动更新缓存。
B) 写穿透 – 应用写入缓存,缓存立即写入数据库后再返回成功。
C) 写后(Write-Behind) – 应用写入缓存,缓存异步将更新排队写入数据库。
D) 写绕过 – 应用直接写入数据库,完全绕过缓存,仅在读取时填充缓存。
答案:C) 写后(Write-Behind)
原因: 写后策略最适合此场景,因为:
- 性能至关重要。 玩家需要即时反馈,写后策略通过仅更新缓存实现近乎即时的“写入成功”。
- 高写入量。 系统每天处理数百万次更新,异步批量写入数据库比实时逐个写入效率更高。
- 最终一致性可以接受。 如果分数短暂不同步,甚至在极少数情况下丢失(例如缓存崩溃未写入数据库),对游戏逻辑和排行榜影响不大,速度优先。
- 降低数据库负载。 写后策略避免高峰期数据库成为瓶颈。
其他选项为何不合适?
- D) 写绕过 在写入时忽略缓存,导致读取时缓存为空,排行榜更新延迟。
- A) 缓存旁路 要求应用手动管理读写,对高频写入无性能优势。
- B) 写穿透 保证一致性,但每次写入都会增加延迟,对实时更新来说太慢。