了解如何为您的业务选择最合适的 RAG 架构。
基于 RAG(Retrieval-Augmented Generation,检索增强生成)的系统,过去是、并且未来仍将是企业应用 LLM(大型语言模型)最实用的方式之一。在本文中,我们将探讨 RAG 从基础 RAG (Naive RAG) 到代理式 RAG (Agentic RAG) 的演变历程。读完本文,您将理解每次架构迭代分别解决了哪些挑战。
基础 RAG 的起源
基础 RAG (Naive RAG) 几乎与 LLM 在 2022 年底随 ChatGPT 引发热潮同时出现。检索增强生成技术的诞生,是为了解决原生 LLM 所面临的一些固有问题,主要包括:
* 幻觉 (即模型生成不实信息)
* 有限的上下文窗口大小
* 无法访问非公开数据
* 模型的参数化知识仅限于其训练数据的截止日期
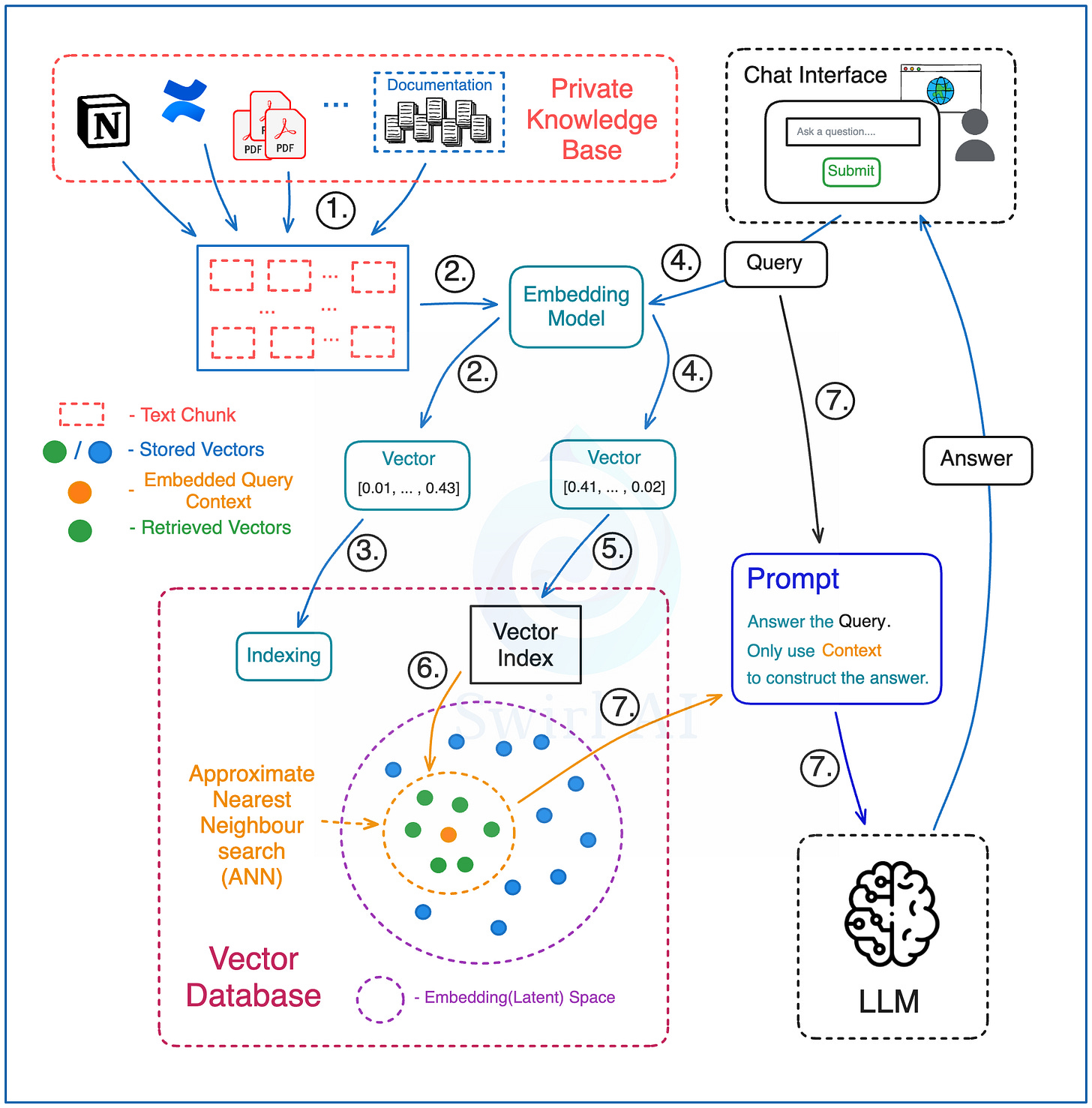
基础 RAG 的最简实现可以概括为以下步骤:
{kind=link}
数据预处理阶段 (Indexing):
1. 数据加载与分割 (Load & Chunk): 将知识库(可能来自 Confluence 文档、PDF 报告等多个来源)的文本语料库分割成较小的文本块 (chunks) -- 每个块代表一个可供检索的上下文单元。
2. 向量化 (Embed): 使用嵌入模型 (Embedding Model) 将每个文本块转换为向量嵌入 (Vector Embedding) 。
3. 存储 (Store): 将所有向量嵌入存储到向量数据库 (Vector Database) 中。同时保存每个嵌入对应的原始文本及其元数据(例如来源信息)。
检索与生成阶段 (Retrieval & Generation):
4. 查询向量化: 使用与步骤 2 中相同的嵌入模型,将用户的问题或查询转换为向量嵌入。
5. 向量检索: 使用查询向量在向量数据库中执行相似性搜索 (通常是近似最近邻 ANN 搜索)。确定需要检索的向量数量(即 Top-K),这决定了最终用于回答问题的上下文信息量。
6. 上下文获取: 向量数据库返回 K 个最相似的向量嵌入,根据这些嵌入找到对应的原始文本块。
7. 答案生成: 将原始问题和检索到的 K 个文本块组合成一个提示 (prompt) ,并将其发送给 LLM。在提示中指示 LLM 仅根据提供的上下文来回答问题。(注意:这并不意味着可以忽略提示工程 (Prompt Engineering)。您仍需精心设计提示,以确保 LLM 的回答符合预期,例如,在上下文中找不到答案时不应编造信息。)
基础 RAG 系统的关键组件
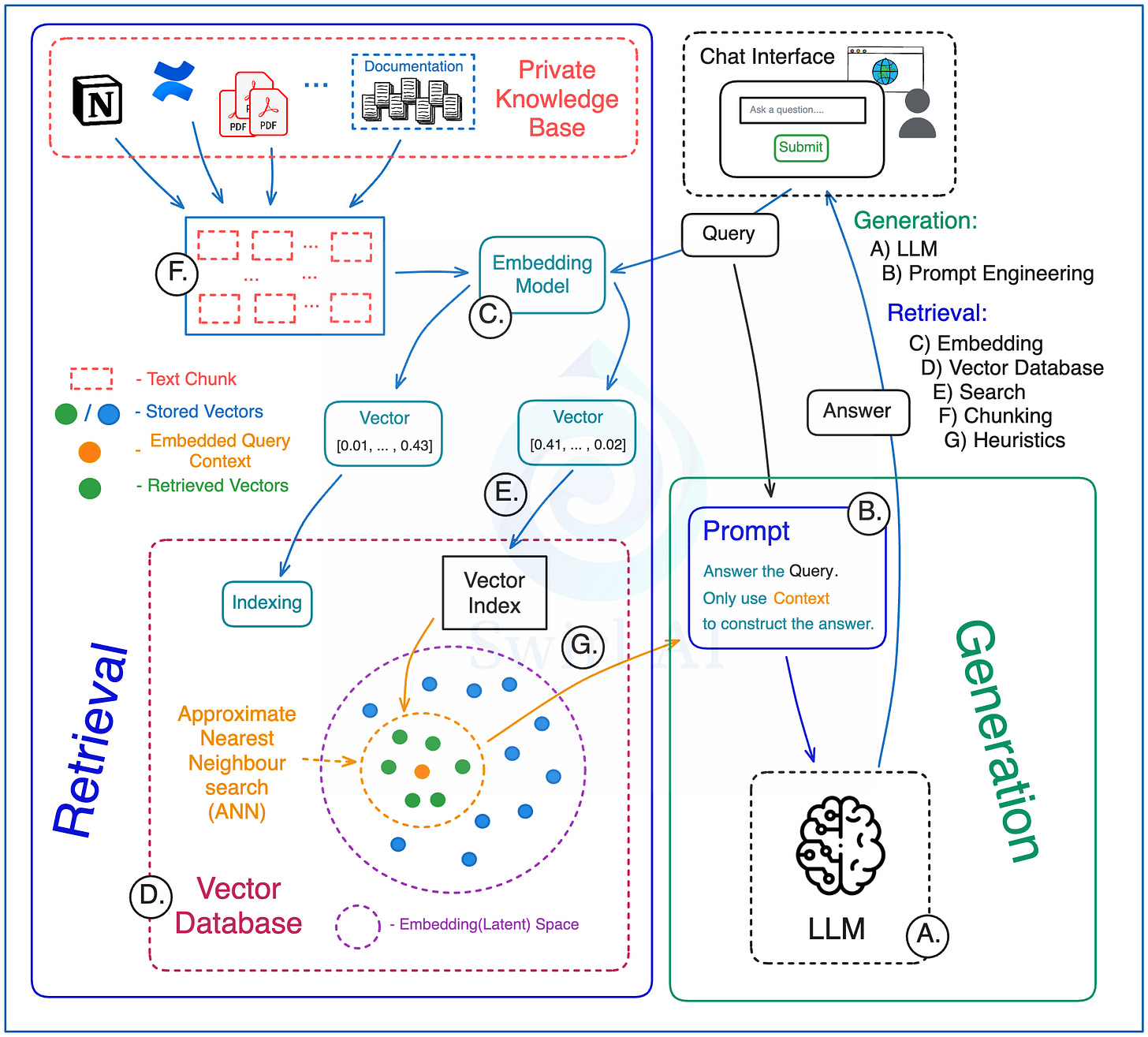
即使是基础 RAG,在构建生产级系统时也涉及许多需要仔细考虑的环节:
{kind=link}
检索阶段 (Retrieval):
* F) 分块策略 (Chunking): 如何分割外部知识源?
* 块的大小(小块 vs. 大块)
* 分块时是否使用重叠窗口 (Overlapping Windows)
* 检索后是否关联父文档或相邻块,还是仅使用原始块
* C) 嵌入模型 (Embedding Model): 选择合适的模型将文本和查询向量化。考虑模型的领域适应性。
* D) 向量数据库 (Vector Database):
* 选择哪种数据库?
* 部署在哪里?
* 存储哪些元数据?(用于预过滤和后过滤)
* 索引策略?
* E) 向量搜索 (Vector Search):
* 选择哪种相似性度量?
* 查询执行路径(元数据过滤优先 vs. ANN 优先)
* 是否使用混合搜索 (Hybrid Search)?
* G) 检索策略/规则 (Heuristics/Rules): 应用于检索过程的业务逻辑或优化规则。
* 时效性考量
* 上下文去重 / 多样性排序 (Diversity Ranking)
* 来源追踪 / 偏好
* 条件性文档预处理
生成阶段 (Generation):
* A) 大型语言模型 (LLM): 选择能满足应用需求的 LLM。
* B) 提示工程 (Prompt Engineering): 即使有上下文,精细调整提示仍然至关重要。需要优化提示以获得期望的输出格式、风格,并防止提示注入或越狱 (jailbreaking) 攻击。
完成以上所有配置,我们就拥有了一个功能性的 RAG 系统。
然而,残酷的现实是 —— 仅凭基础 RAG 往往不足以解决复杂的实际业务问题。这类系统的准确性可能因多种原因而受限。
高级 RAG 技术:提升基础 RAG 性能
以下是一些已被证明能有效提升基础 RAG 系统准确性的先进技术:
* 查询转换 (Query Transformation): 可以使用多种技巧:
* 查询重写 (Query Rewriting): 利用 LLM 重写原始查询,使其更适合检索。例如,修正语法错误,或将复杂问题分解为更简洁的子查询。
* 查询扩展 (Query Expansion): 利用 LLM 生成原始查询的多个变体。然后对每个变体都执行检索,以获取更广泛的潜在相关上下文。查询转换有助于更好地捕捉用户意图,提升检索准确率。
* 重新排序 (Re-ranking): 使用计算成本更高但更精确的模型(通常是 Cross-Encoder)对初步检索到的一批文档(数量通常比最终需要的 K 值更大,比如 Top-N, N > K)进行重新排序,选出最终的 Top-K。这对于查询扩展(因其返回更多候选文档)尤其有效。这个过程与推荐系统中的两阶段排序相似。
* 嵌入模型微调 (Fine-tuning Embedding Models): 对于特定领域(如医疗、法律),通用嵌入模型可能效果不佳。在这种情况下,微调一个针对特定领域语料库的嵌入模型能显著提高检索相关性。
接下来,我们探讨另外几种高级 RAG 技术和架构。
#### 上下文检索 (Contextual Retrieval)
上下文检索的概念由 Anthropic 团队在去年提出,旨在提高 RAG 系统中检索信息的准确性和相关性。
我个人很欣赏上下文检索的直观性和简洁性,实践证明它效果不错。
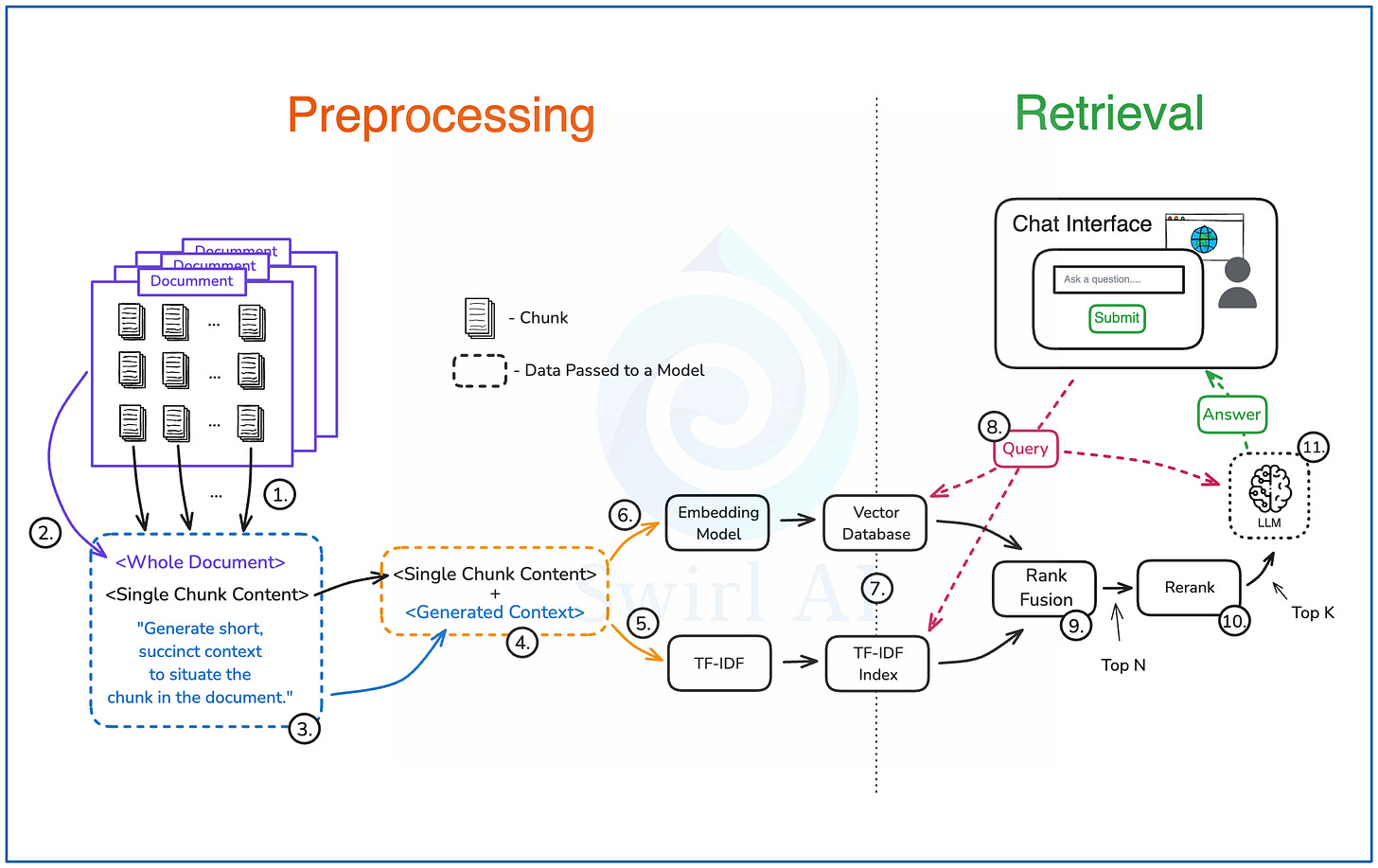
以下是其实现步骤:
{kind=link}
预处理阶段:
1. 按选定的策略将每个文档分割成块。
2. 对于每个块,将其与包含该块的整个文档一起组合成一个提示。
3. 提示中包含指令,要求 LLM 定位该块在文档中的位置,并为其生成一段简短的上下文摘要。将此提示传递给选定的 LLM。
4. 将上一步生成的上下文摘要与原始块合并。
5. 使用 TF-IDF 对合并后的文本进行处理(生成稀疏向量)。
6. 使用基于 LLM 的嵌入模型对合并后的文本进行处理(生成密集向量)。
7. 将步骤 5 和 6 生成的稀疏和密集向量存储在支持混合搜索的数据库中。
检索阶段:
8. 使用用户查询同时进行语义搜索(基于密集向量的 ANN 搜索)和关键词搜索(基于稀疏向量的 TF-IDF 搜索)。
9. 使用排名融合 (Rank Fusion) 技术(如 RRF)合并两种搜索结果,去除重复项,选出 Top-N 结果。
10. 对 Top-N 结果进行重新排序 (Re-ranking) ,筛选出最终的 Top-K 结果。
11. 将 Top-K 结果(通常是原始文本块,而非摘要)与用户查询组合,输入 LLM 生成最终答案。
一些思考:
步骤 3* 听起来可能成本高昂,确实如此。但可以通过提示缓存 (Prompt Caching) 技术显著降低重复计算的成本。
* 提示缓存无论对于闭源 API 模型还是自托管的开源模型都是可以实现的。
缓存增强生成 (CAG) 简介
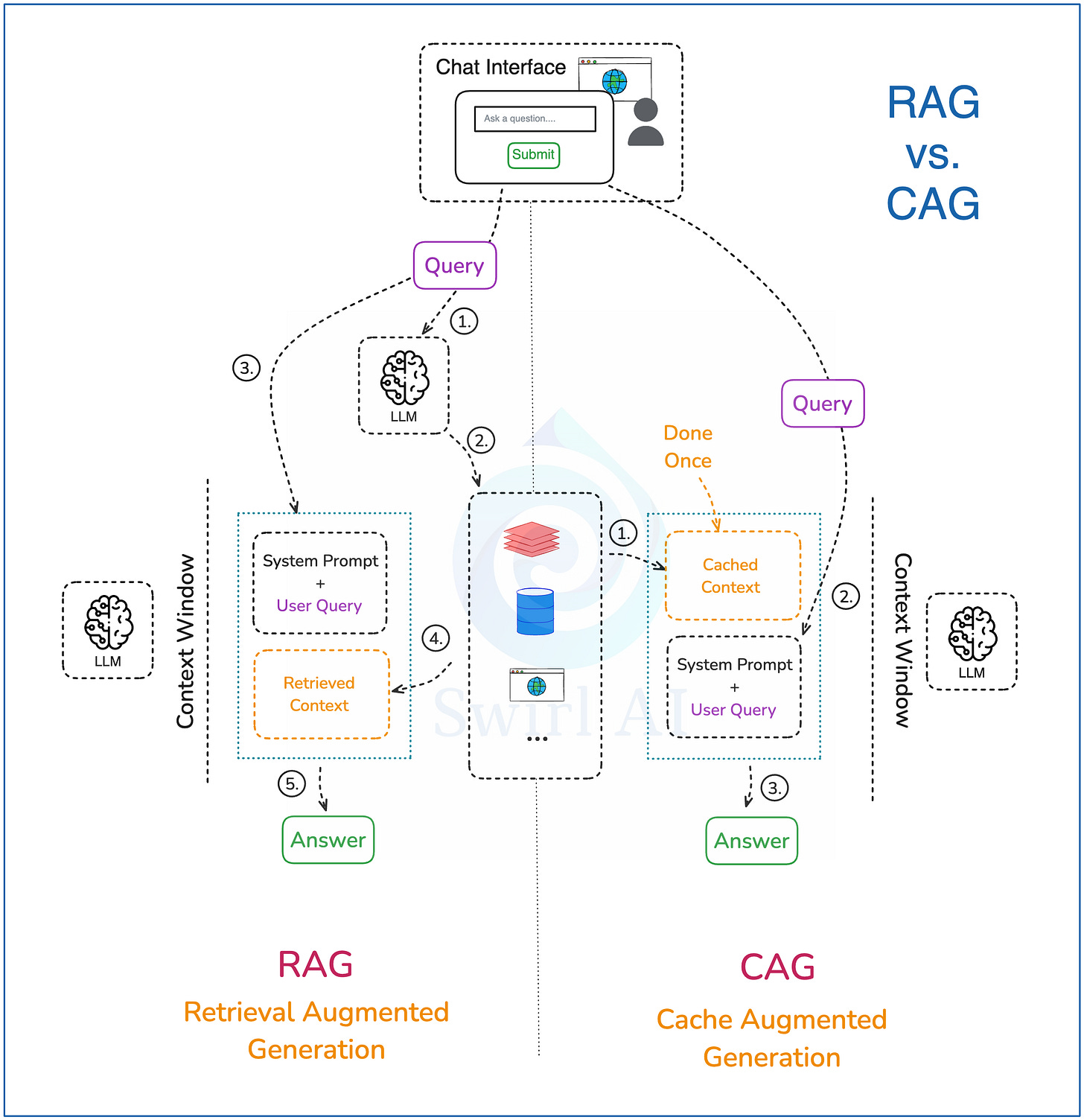
近段时间,一篇关于缓存增强生成 (Cache-Augmented Generation, CAG) 的论文在社交媒体上引起了短暂的关注,号称是 RAG 的革新技术。我们已经了解了标准 RAG 的工作方式,下面是 CAG 的简要说明:
{kind=link}
1. 预加载上下文: 将所有外部上下文预先计算并加载到 LLM 的 KV 缓存中。这个过程通常只需执行一次。
2. 生成: 将用户查询与系统提示(包含如何使用缓存上下文的指令)一起传递给 LLM。
3. 返回与重置: 将生成的答案返回给用户。之后,清除缓存中的生成内容,仅保留初始加载的上下文,为下一次生成请求做准备。
CAG 试图通过将全部上下文置于 LLM 的“眼前”(KV 缓存)来提高准确性,而不是像 RAG 那样每次只检索部分上下文。但现实情况是:
* CAG 无法解决超长上下文(即使在缓存中)导致的“大海捞针”和准确性下降问题。
* 在数据安全和权限管理方面存在挑战。
* 对于大型组织的整个内部知识库,一次性加载到缓存中几乎不可行。
* 缓存是静态的,更新数据(增量索引)会很麻烦。
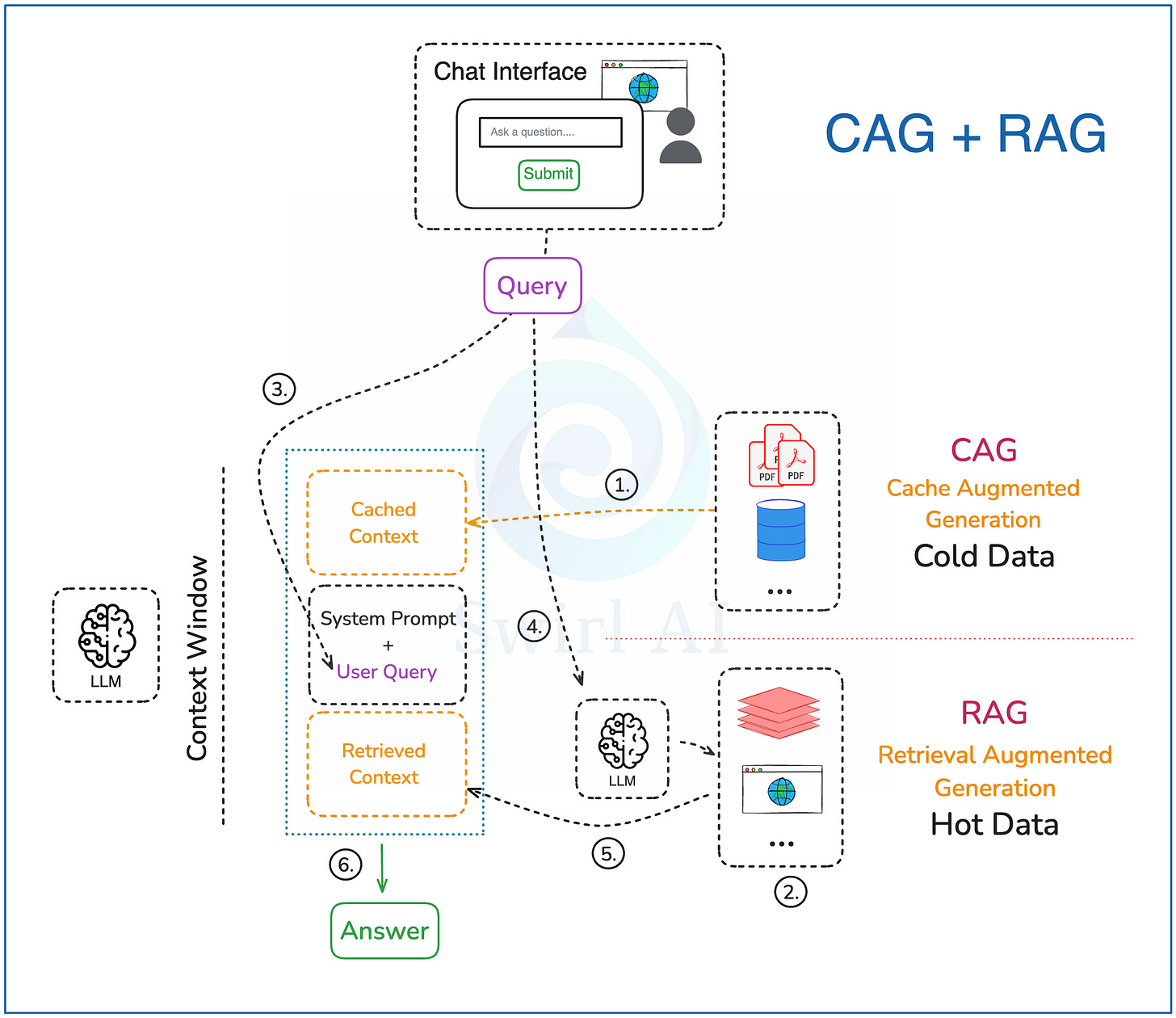
实际上,随着主流 LLM 提供商(如 OpenAI, Anthropic)引入提示缓存 (Prompt Caching) 功能,我们已经在某种程度上使用了 CAG 的变体或思想。这种更实用的方法可以看作是 CAG 和 RAG 的融合:
{kind=link}
数据预处理:
1. 选择性缓存: 选择那些不经常变动且经常被查询命中的数据源。将这些选定的数据预加载到 LLM 的 KV 缓存中(如果 LLM 服务支持)。
2. 常规 RAG 索引: 对其他数据源(经常变动或不适合缓存的数据)进行常规 RAG 索引处理(如计算向量嵌入并存入向量数据库,或准备其他可查询的数据格式)。
查询路径:
3. 构建基础提示: 准备包含用户查询和系统指令(说明如何结合缓存信息和后续检索的信息)的提示。
4. 执行 RAG 检索: (如果需要) 根据用户查询,从向量数据库或其他数据源(如实时数据库、Web API)检索相关数据。
5. 组合最终提示: 将步骤 4 中检索到的外部上下文添加到步骤 3 的提示中。
6. 生成答案: 将最终组合的提示发送给 LLM,生成答案并返回给用户。
接下来,我们看看最新的进展——代理式 RAG (Agentic RAG)。
代理式 RAG (Agentic RAG)
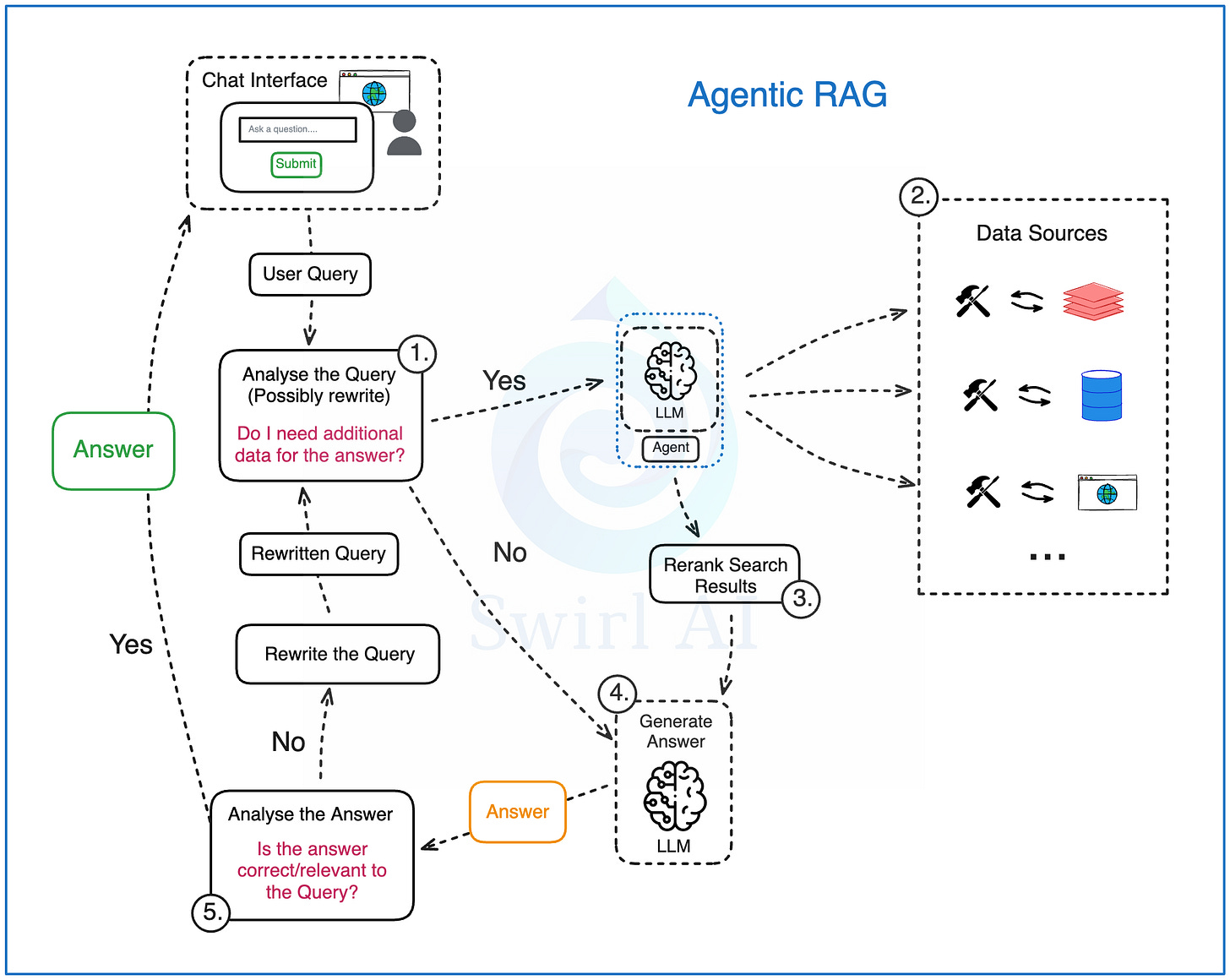
代理式 RAG 旨在通过引入代理 (Agent) 的概念来处理更复杂的查询,减少不准确和不一致性。它通常包含两个核心增强:
* 数据源路由 (Data Source Routing)
* 反思/修正 (Reflection)
我们来详细了解其工作流程:
{kind=link}
1. 查询分析 (Query Analysis): 首先,将用户原始查询交由一个基于 LLM 的代理 (Agent) 进行分析。代理可能会:
* 重写或分解原始查询,生成一个或多个更适合后续处理的子查询。
* 判断是否需要额外的外部信息来回答查询,体现了代理的初步规划能力 (planning) 。
2. 数据源路由与检索 (Data Source Routing & Retrieval): 如果代理判断需要外部信息,则触发检索。此时,数据源路由组件生效:
* 系统可以配置多个不同的数据源(例如:实时用户数据库、内部文档库、Web 搜索接口等)。
* 代理根据查询内容和自身的规划,自主选择一个或多个最合适的数据源进行查询和信息检索。这体现了代理的工具使用能力 (tool use) 。
3. 重新排序 (Re-ranking): 从一个或多个数据源检索到信息后,对其进行重新排序(类似于高级 RAG)。这一步允许整合来自不同存储技术(如向量库、SQL 数据库、API)的数据源。各种检索过程的复杂性可以封装为代理可调用的工具 (Tools) 。
4. 生成初步答案/执行动作 (Initial Generation / Action): 代理利用分析后的查询和检索到的信息,尝试通过 LLM 生成初步答案,或者根据任务规划执行某个动作(例如调用另一个 API)。
5. 反思/修正 (Reflection): 这是代理式 RAG 的关键区别之一。代理会对生成的初步答案(或动作结果)进行评估,判断其正确性、相关性和完整性:
* 如果答案符合要求,则将其返回给用户。
* 如果答案不满意,代理会启动修正循环:可能重新分析查询、调整检索策略(例如选择不同的工具或参数)、或要求 LLM 重新生成答案,直到满足预设的标准或达到最大尝试次数。
总结
我们一起回顾了现代 RAG 架构从基础到高级,再到代理式的演变路径。RAG 技术远未消亡,并且在可预见的未来仍将是 LLM 应用的关键组成部分。
我相信 RAG 架构将持续演进,学习这些不同的模式并理解它们的适用场景,对于希望利用 LLM 解决实际问题的开发者和企业来说,是一项非常有价值的投入。
总的来说,在满足需求的前提下,应尽可能追求简洁有效的设计。因为系统越复杂,通常也意味着面临更多挑战,例如:
* 端到端系统评估更加困难
* 多次 LLM 调用导致延迟增加
* 运营成本(计算资源、API 调用费用)上升
* 维护和调试更复杂
参考链接: https://www.newsletter.swirlai.com/p/the-evolution-of-modern-rag-architectures