本篇内容概览
在第一部分中,我们将重点讨论以下内容:
- 数据工程和机器学习中的 Kubernetes 应用
- Kubernetes 应用配置的基础资源:
- 命名空间(Namespaces)
- 配置映射(ConfigMaps)
- 密钥(Secrets)
- 应用部署相关资源:
- 容器组(Pods)
- 部署(Deployments)
- 服务(Services)
虽然本文仅介绍了 Kubernetes 的基础部分,但掌握这些概念后,你已具备构建实用应用程序的能力。
下一部分的链接如下,欢迎继续阅读:
Kubernetes 指南(第二部分):部署应用的不同方式
数据工程和机器学习中的 Kubernetes 应用
让我们从宏观视角了解 Kubernetes。简单来说,Kubernetes 是一个用于调度、运行和恢复容器化应用的容器编排工具。它支持水平扩展和自我修复功能。虽然本文常用 Docker 图标代表容器,但需要注意的是,K8s 几乎可以编排任何类型的容器。
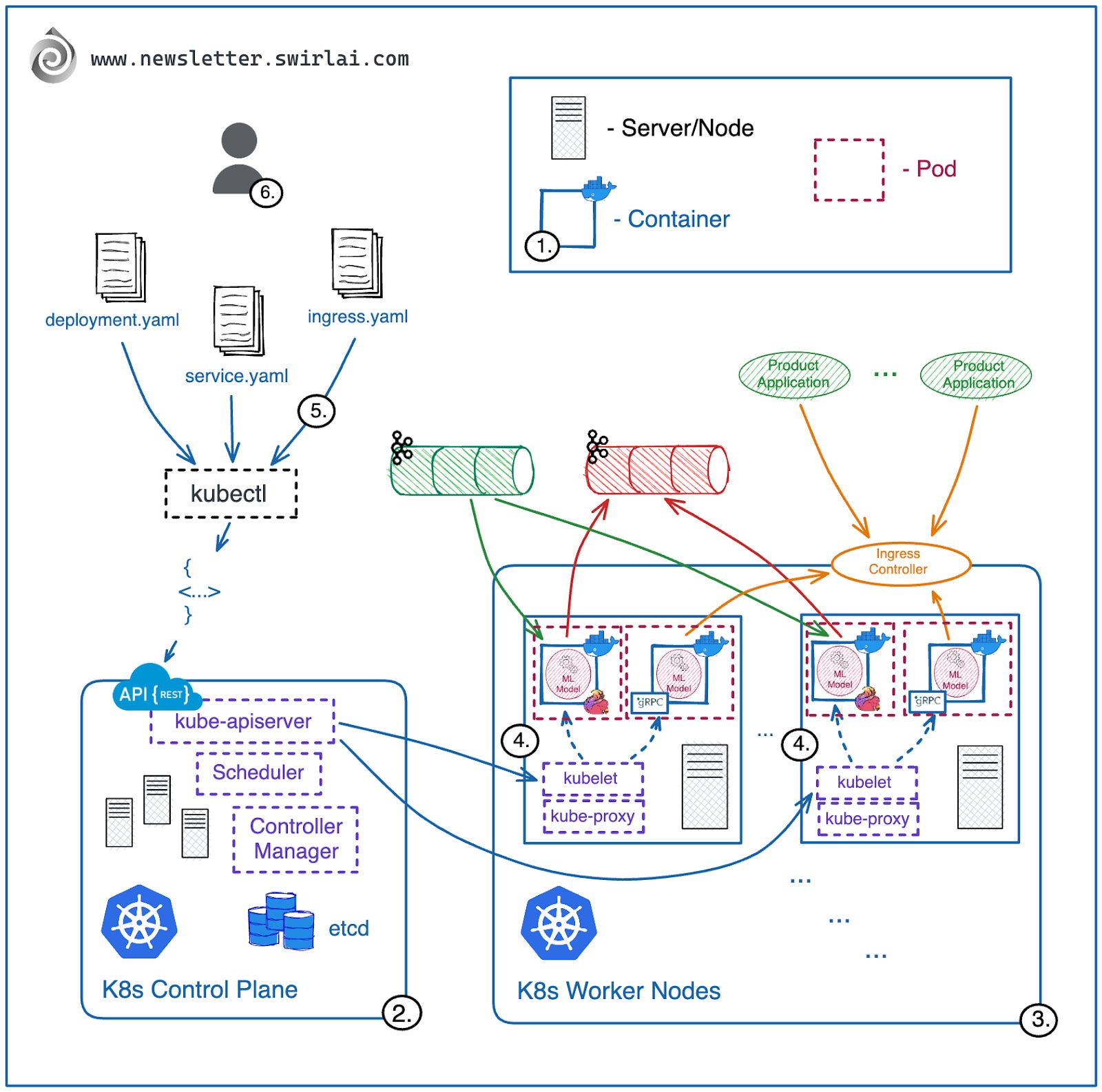
Kubernetes 的架构
Kubernetes 集群的逻辑架构主要分为两部分:
1. 控制平面(Control Plane)
这是 Kubernetes 系统的核心进程所在,也是集群的大脑,负责调度用户定义的工作负载并确保系统健康运行。作为应用开发者,你几乎无需直接接触控制平面,尤其是使用云托管的 Kubernetes 服务时,服务商会代为管理。我们将在后续系列中详细探讨控制平面。
2. 工作节点(Worker Nodes)
这是容器实际调度和运行的场所。作为开发者,你将频繁与工作节点打交道,关注的内容包括节点的资源分配、应用在同一节点上的共存、持久化存储需求等。
{kind=link}
Kubernetes 的核心优势
1. 无与伦比的水平扩展能力
一个 Kubernetes 集群可以包含数千个节点(通常只需几十个),每个节点可托管多个容器组(Pods)。根据需求,节点可以动态添加或移除,轻松实现扩展。例如,某公司通过 Kubernetes 实现了从 10 个节点扩展到 1000 个节点的需求,极大地提升了系统的灵活性和可扩展性。
2. 简洁的声明式接口
Kubernetes 提供了一个易用的声明式接口。你只需用 YAML 文件描述应用的部署定义,提交到集群后,系统会自动确保应用始终处于期望状态。这种统一的方式还能规范团队内部的沟通和架构描述。
3. 用户自主与管理员控制的平衡
Kubernetes 允许用户在集群管理员预设的边界内自主设计应用架构。管理员可以通过隔离用户或团队、设置资源配额等方式,确保资源使用的安全性和合理性。
对数据工程师和机器学习工程师的价值
作为数据工程师、机器学习或 MLOps 工程师,Kubernetes 能为你带来哪些具体好处?让我们来看看:
- 统一集群部署多种应用
你可以在单个集群中部署多种类型的机器学习应用,而无需关心具体服务器分配,Kubernetes 配置会自动处理:
- 实时服务:运行模型及其多个版本。
- 流式应用:处理实时数据流。
- 批处理任务:调度和运行批处理作业。
- ETL 框架:例如在 Kubernetes 上部署 Airflow,并为每个任务分配独立的容器组,安装不同的依赖。
- 配置简单易学
Kubernetes 的配置方式直观,学习曲线较为平缓。
- 按需分配资源
你可以为每个应用申请不同数量的专用机器资源。
- 高可用性保障
如果应用宕机,Kubernetes 会自动确保预设的副本数量始终在线。
- 多种升级策略
你可以采用多种策略平滑发布新版本应用,Kubernetes 会安全地完成更新。
- 服务暴露便捷
通过简单的资源定义,你可以将机器学习服务暴露给其他产品应用使用。
几点注意事项
- 虽然 Kubernetes 使用起来非常便利,但其集群运维却可能令人望而却步。这是一个复杂的系统。
- 控制平面本身会产生一定的开销,即使你只想部署一个小型应用,也需要它。
前置准备
本教程假设你已具备以下条件:
1. Kubernetes 集群:你已拥有远程 Kubernetes 集群的访问权限,或通过多种方式部署了本地集群。
2. kubectl 客户端:已安装并配置好 kubectl,用于访问 Kubernetes 集群。
3. Docker 基础知识:本教程假设读者对 Docker 有基本了解。后续我将发布 Docker 教程系列,敬请期待。
我个人使用 Mac,并在 Docker Desktop 上运行本地 Kubernetes 集群。你可以在这里找到 Windows 和 Mac 的设置方法。如果使用 Linux,推荐使用 Minikube,设置指南请参考这里。当然,Minikube 也支持 Mac 和 Windows。
值得一提的是,我们在本地操作的几乎所有内容都可以不加修改地迁移到任何 Kubernetes 集群,这是 Kubernetes 的强大之处之一。
Kubernetes 基础资源
了解了 Kubernetes 对数据专业人士的诸多益处后,我们接下来聚焦于应用开发者需要掌握的虚拟资源。这些资源是你通过 Kubernetes API 定义并提交的对象,集群会根据你的定义确保其状态始终符合预期。
我们从最基础的资源——命名空间(Namespaces)开始。
命名空间(Namespaces)
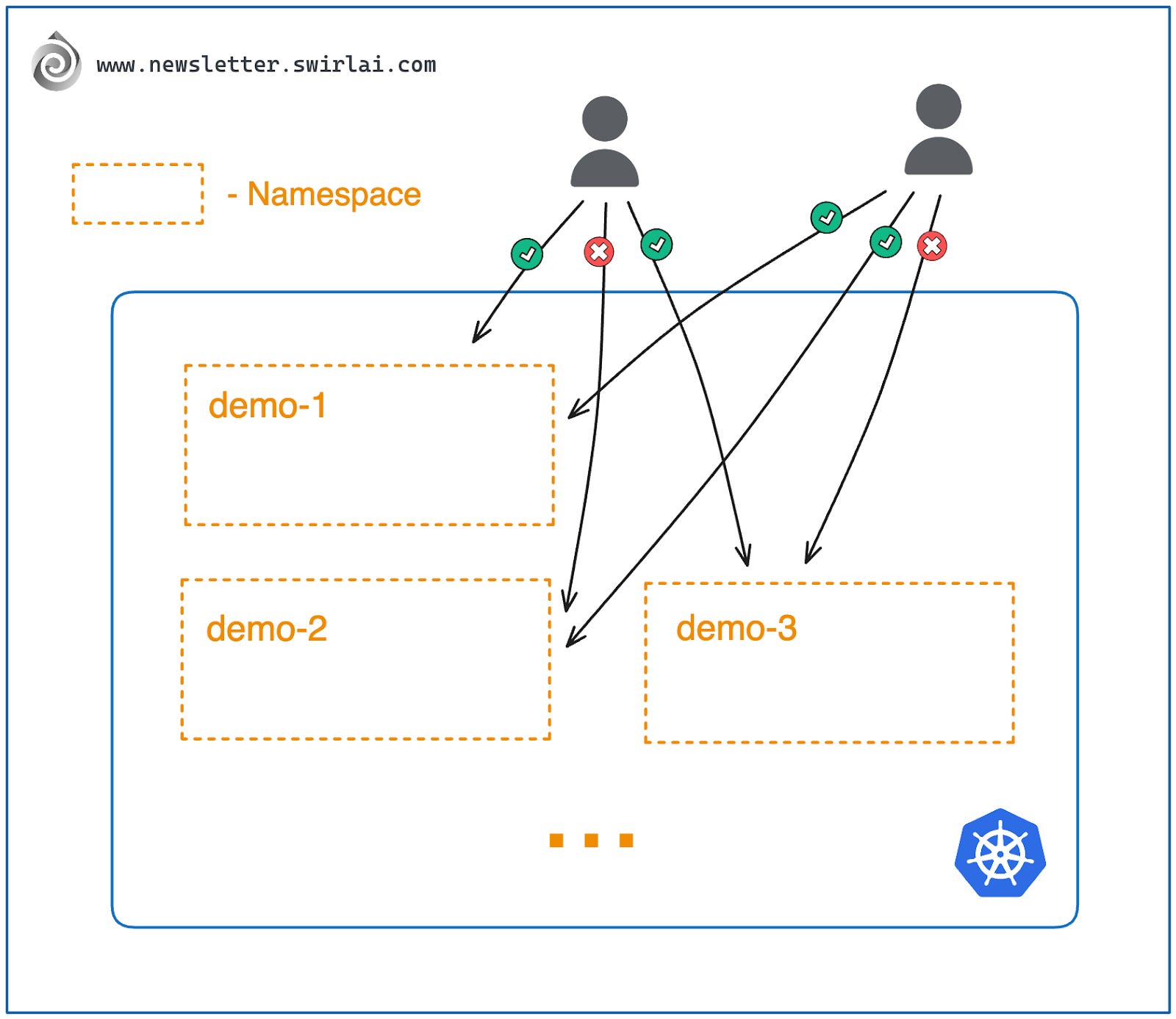
命名空间是 Kubernetes 中用于逻辑分组其他资源的工具。通常,你会在某个命名空间中创建资源,只有少数全局资源不绑定特定命名空间。
Kubernetes 集群默认会预创建几个命名空间,你也可以创建或被分配新的命名空间来部署应用资源。命名空间的重要性在于,它为用户和管理员提供了以下便利:
- 权限隔离:命名空间常作为基于角色的访问控制(RBAC)的隔离层。你可以为不同命名空间设置不同权限,控制哪些用户可以访问或操作哪些资源。
{kind=link}
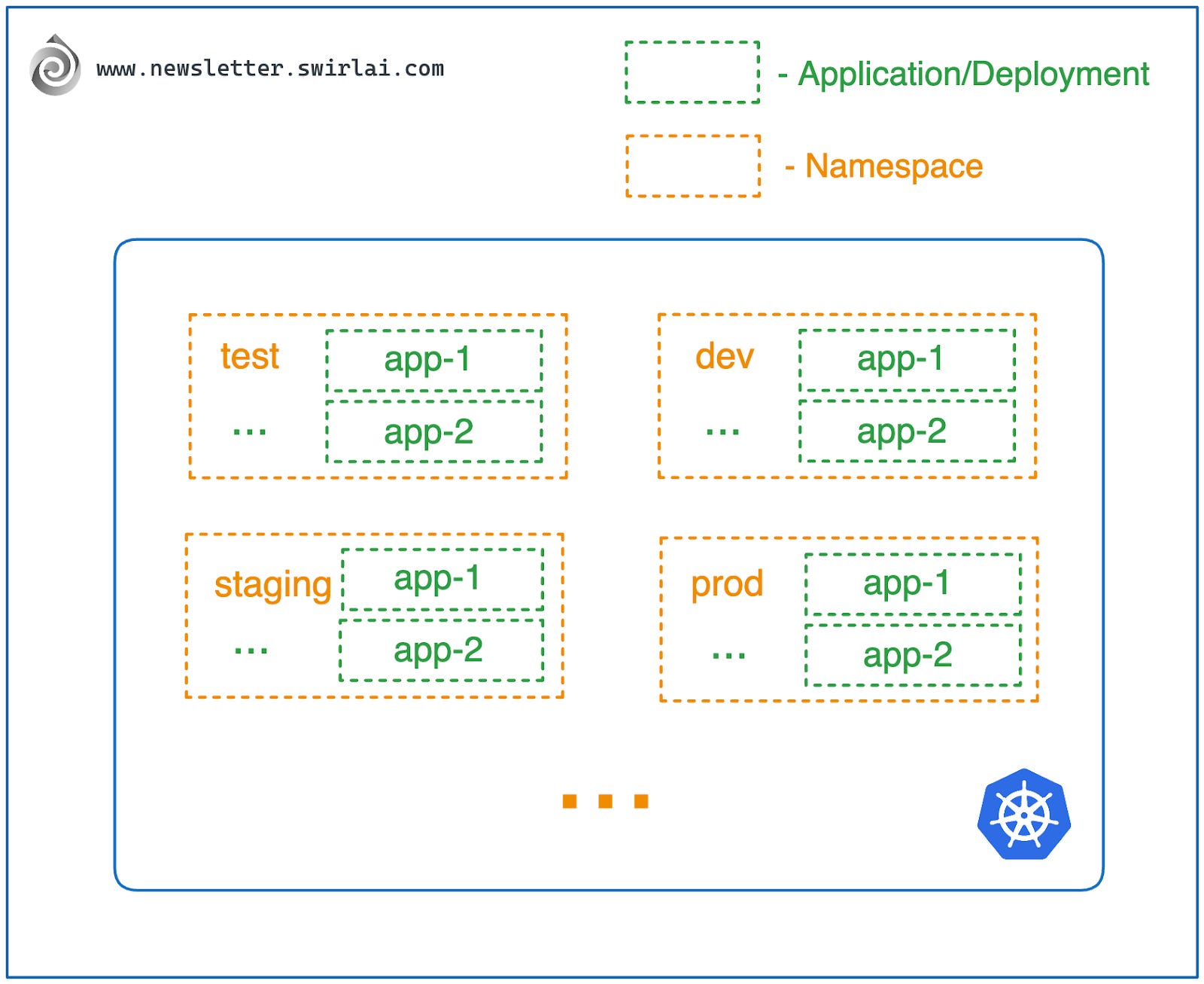
- 应用隔离:每个命名空间有独立的资源命名空间。例如,你可以在 demo 命名空间中创建名为 swirl-ai-app 的应用,同时在 demo-2 命名空间中创建同名应用,而不会冲突。这简化了跨命名空间的应用命名规范。假设你在一个公司工作,公司有不同部门,每个部门都有自己的项目和资源,这就是命名空间的作用。
{kind=link}
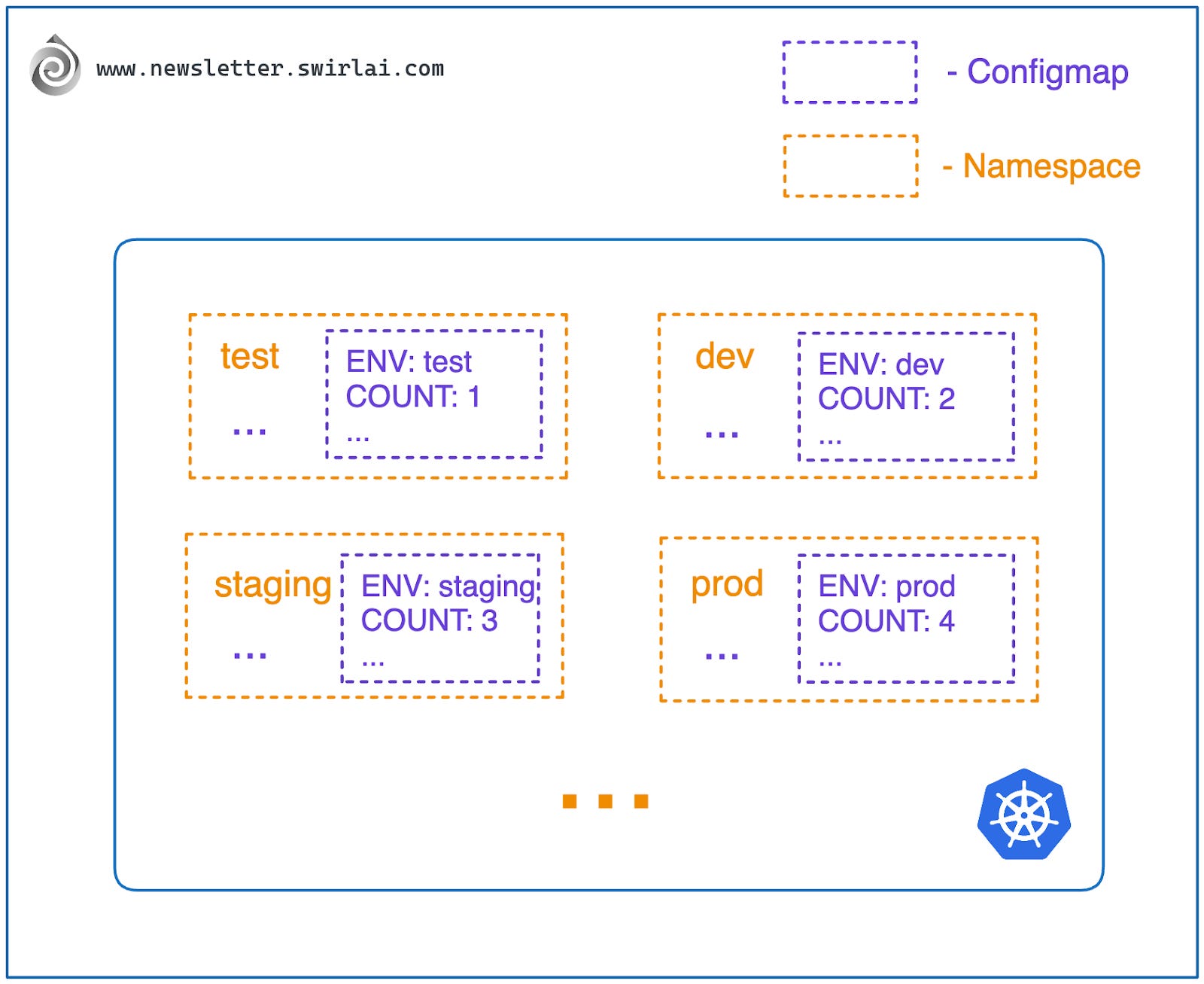
- 变量与密钥隔离:每个命名空间可以有独特的变量和密钥集,只有被授权访问该命名空间的用户才能使用其中的资源。这不仅便于管理 Kubernetes 内部资源访问,还能简化外部凭据管理。
{kind=link}
#### 创建命名空间
通过以下 YAML 文件,你可以创建名为 swirlai 的命名空间,并将其保存为 namespace.yaml:
apiVersion: v1
kind: Namespace
metadata:
name: swirlai
然后执行以下命令应用配置:
kubectl apply -f namespace.yaml
检查创建结果:
kubectl get namespaces
你将看到类似以下的输出:
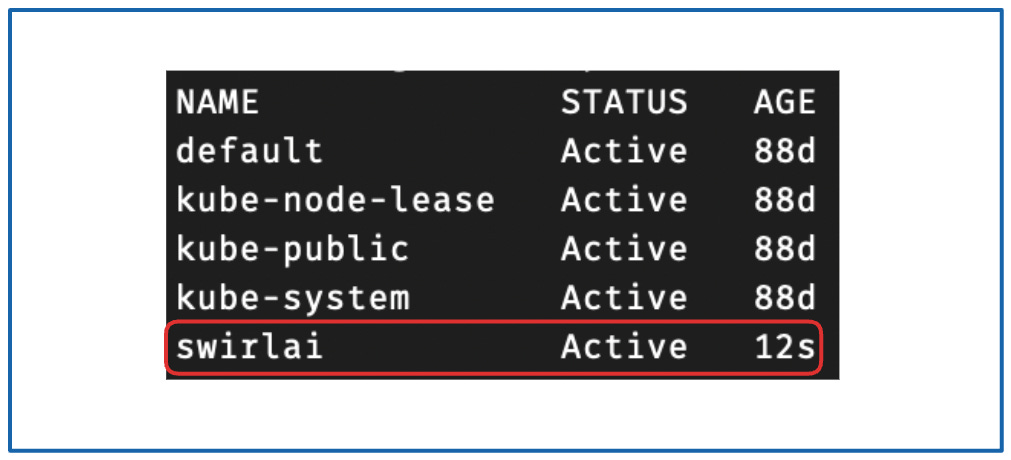{kind=link}
配置映射(ConfigMaps)
配置映射(ConfigMaps)是 Kubernetes 中存储配置的一种方式,供同一命名空间内的应用使用。ConfigMaps 主要有两种使用方式:
1. 存储键值对:将配置以键值对形式存储,并在运行时注入应用,通常通过设置环境变量实现。
2. 存储文件内容:将文件内容以字符串形式存储为 ConfigMap 的值,并在运行时挂载为文件供应用读取。这在运行如 Airflow 等框架时非常有用,你可以通过 ConfigMap 挂载完整的 airflow.cfg 文件,而无需直接修改应用代码。
ConfigMap 的应用场景非常广泛,其中一个典型例子是为不同环境配置应用:
- 假设你有三个命名空间:dev(开发)、staging(预发布)和 prod(生产)。
- 你的应用需要在三个环境中迁移部署。
- 为了减少代码中的硬编码,你将行为参数化,例如连接的数据库、限流配置等。
- 通过 ConfigMap 注入参数,无需修改应用代码即可在不同命名空间部署,唯一需要调整的是每个命名空间的 Kubernetes 参数。
#### 创建配置映射
在 swirlai 命名空间中创建一个名为 config 的 ConfigMap,并将其保存为 configmap.yaml:
apiVersion: v1
kind: ConfigMap
metadata:
name: config
namespace: swirlai
data:
environment: dev # 键值对
db-host: localhost # 键值对
airflow.cfg: | # 键值对,文件内容形式
[core]
# The folder where your airflow pipelines live, most likely a
# subfolder in a code repository. This path must be absolute.
dags_folder = /usr/local/airflow/dags
# The folder where airflow should store its log files
# This path must be absolute
base_log_folder = /usr/local/airflow/logs
...
应用配置:
kubectl apply -f configmap.yaml
检查创建结果:
kubectl get configmaps -n swirlai
你将看到类似以下的输出:
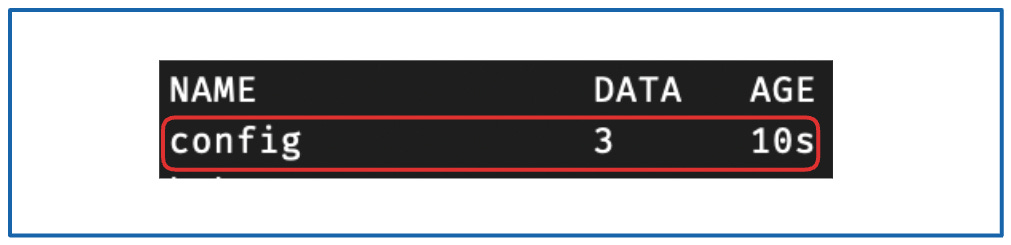{kind=link}
密钥(Secrets)
密钥(Secrets)是 Kubernetes 中另一种配置共享机制,专门用于存储敏感信息,如密码或其他凭据。需要注意的是,Secrets 并非绝对安全,其数据仅以 base64 编码存储。如果用户有权限从 Kubernetes 服务器获取数据,就能轻松解码。因此,现代且更安全的做法是将敏感信息存储在第三方密钥库中,并在运行时直接注入应用。
如果你的集群未连接密钥库,仍需使用原生 Secrets 管理敏感信息。使用时务必限制访问权限,确保只有授权人员可以查看或获取。
#### 创建密钥
首先,需要将要保护的字符串进行 base64 编码。例如,保护字符串 super-secret,其 base64 编码为 c3VwZXItc2VjcmV0。在 Mac 上,你可以通过以下命令获取:
echo -n 'super-secret' | base64
在 swirlai 命名空间中创建一个名为 secret 的密钥,保存为 secret.yaml:
apiVersion: v1
kind: Secret
metadata:
name: secret
namespace: swirlai
data:
secret-data: c3VwZXItc2VjcmV0
应用配置:
kubectl apply -f secret.yaml
检查创建结果:
kubectl get secrets -n swirlai
你将看到类似以下的输出:
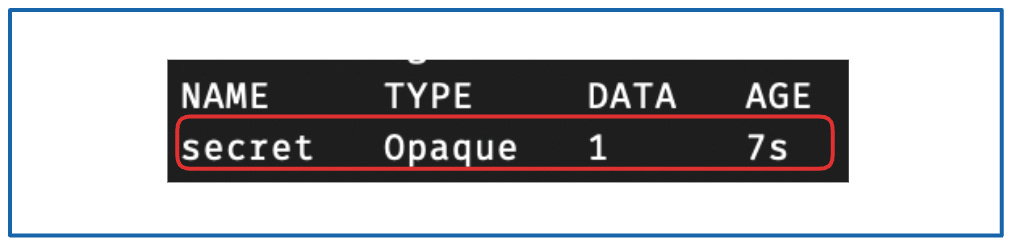{kind=link}
应用部署概述
了解了如何创建命名空间及配置资源后,我们进入最有趣的部分:如何将应用部署到 Kubernetes 集群。与 ConfigMaps 和 Secrets 类似,应用部署通常也在特定命名空间中进行。
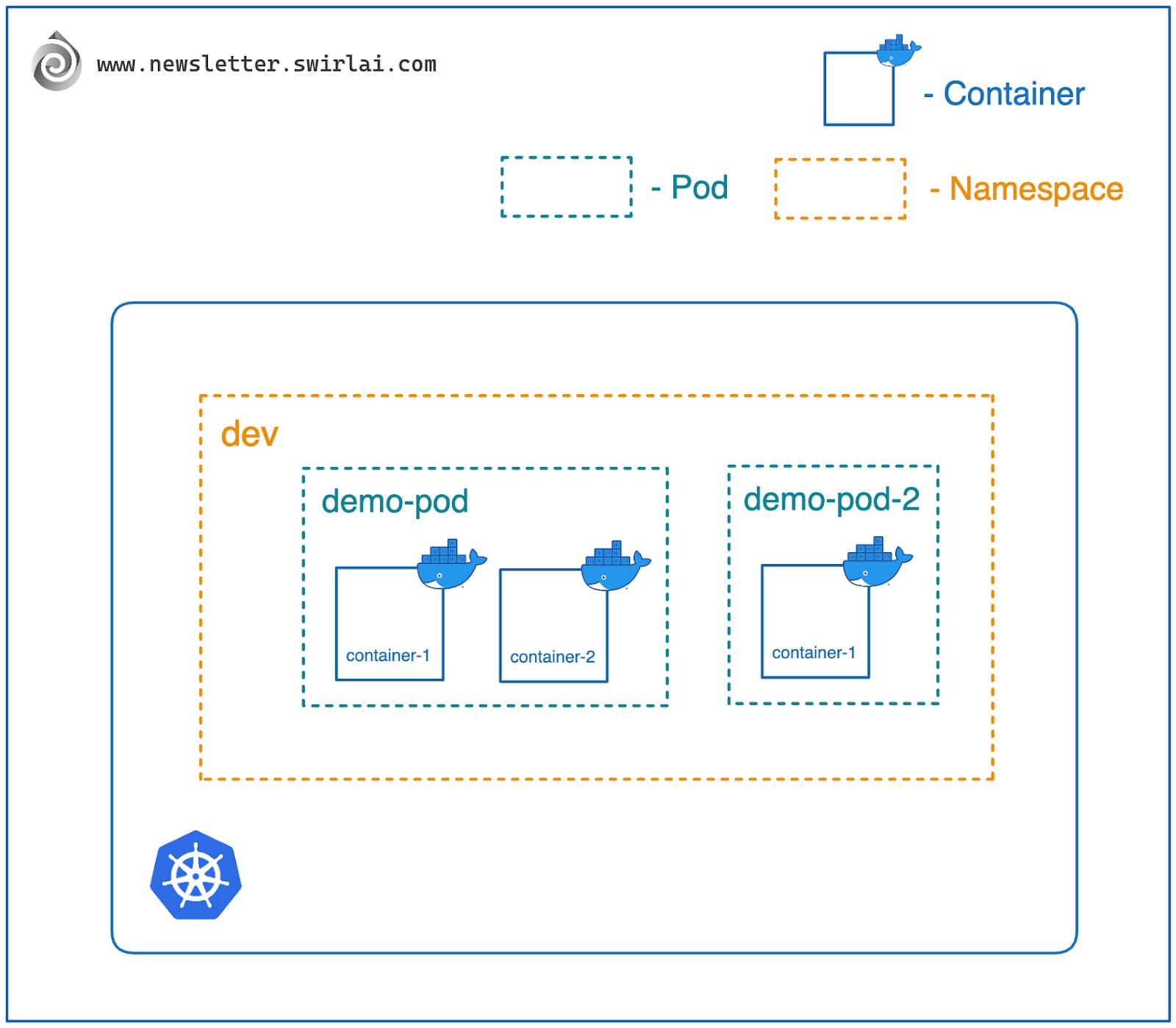
容器组(Pods)
如前文所述,Kubernetes 是一个容器编排工具,负责管理已容器化的应用生命周期。Kubernetes 中最小的资源单位不是容器,而是容器组(Pod)。
一个 Pod 是 Kubernetes 的资源单位,可以封装一个或多个容器,并为它们提供共享的网络和存储空间的运行时配置环境。一旦 Pod 的配置被应用,Kubernetes 集群会启动请求的容器并保持其运行。
{kind=link}
需要注意的是,Kubernetes 中所有资源都有名称。
#### 创建 Pod
在 swirlai 命名空间中创建一个名为 swirlai-pod 的 Pod。该 Pod 运行来自 Docker Hub 的 nginx:latest 容器,并使用之前定义的 ConfigMap 和 Secret 作为环境变量。保存为 pod.yaml:
apiVersion: v1
kind: Pod
metadata:
name: swirlai-pod
namespace: swirlai
spec:
containers:
- name: swirlai-container
image: nginx:latest
ports:
- containerPort: 80
env:
- name: DIRECT
value: Some String
- name: ENVIRONMENT
valueFrom:
configMapKeyRef:
name: config
key: environment
- name: SECRET_DATA
valueFrom:
secretKeyRef:
name: secret
key: secret-data
应用配置:
kubectl apply -f pod.yaml
检查创建结果:
kubectl get pods -n swirlai
你将看到类似以下的输出:
{kind=link}
注意 Ready: 1/1 列,表示 Pod 中容器已就绪(后续系列将深入探讨“就绪”的含义)。在 Pod 资源定义文件中,containers 字段是一个列表,我们只定义了一个容器,但可以定义多个。
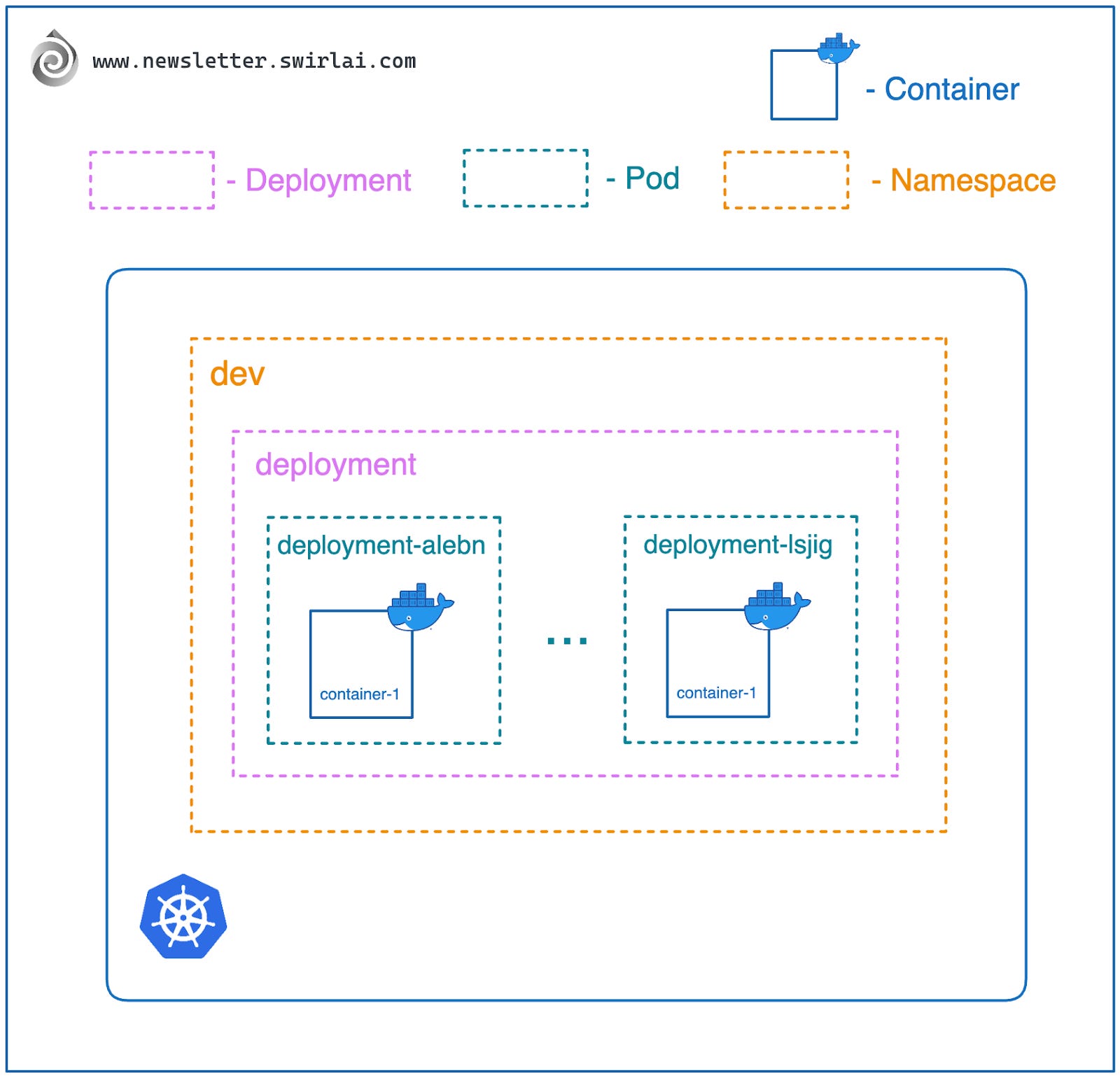
部署(Deployments)
Pod 几乎从不单独使用,因为单独管理 Pod 难以实现扩展,就像直接管理原始容器一样复杂。你需要定义多个 Pod 并确保它们始终运行。因此,Kubernetes 提供了多种工作负载资源,帮助你自动部署和扩展 Pod 集合,只需定义相关规则即可。Deployment 是一种用于管理多个相同 Pod 副本的资源,也是其中最常用的一种,特别适合微服务应用的扩展。本文仅讨论 Deployment,其他工作负载管理方式将在后续系列中介绍。
#### 什么是 Deployment?
Deployment 是一种管理多个相同 Pod 副本的资源。在微服务和水平扩展的世界中,应用通常是无状态的,可以通过增加副本数量来扩展,并通过负载均衡器或消费者组(如流式应用)分发流量。
{kind=link}
#### 在数据领域中 Deployment 的典型应用
Deployment 是扩展实时机器学习 API 的天然选择。这些应用通常无状态,模型加载到内存中按需进行推理,推理所需数据存储在外部(如特征存储)或随请求传入。
#### Deployment 的其他功能
- 副本管理:你定义希望运行的 Pod 副本数量,Deployment 确保始终有这么多 Pod 在运行。
- 唯一命名:每个 Pod 会被分配唯一名称,以 Deployment 名称为前缀,附加随机值。
- 版本发布:当 Pod 定义发生变化时,Deployment 按你定义的规则平滑发布新版本(后续系列将深入探讨)。
- 版本回滚:Deployment 支持平滑回滚到之前的应用版本。
需要注意的是,Deployment 通过底层的 ReplicaSet(副本集)管理 Pod 集合,定义 Pod 的期望状态。通常开发者无需直接接触 ReplicaSet,除非遇到需要调试的问题。
#### 创建 Deployment
在 swirlai 命名空间中创建一个名为 swirlai-deployment 的 Deployment。该 Deployment 管理 3 个之前定义的 swirlai-pod 副本。保存为 deployment.yaml:
apiVersion: apps/v1
kind: Deployment
metadata:
name: swirlai-deployment
namespace: swirlai
spec:
replicas: 3
selector:
matchLabels:
app: swirlai
template:
metadata:
labels:
app: swirlai
spec:
containers:
- name: swirlai-container
image: nginx:latest
ports:
- containerPort: 80
env:
- name: DEFINED_DIRECTLY
value: Some String
- name: ENVIRONMENT
valueFrom:
configMapKeyRef:
name: config
key: environment
- name: SECRET_DATA
valueFrom:
secretKeyRef:
name: secret
key: secret-data
应用配置:
kubectl apply -f deployment.yaml
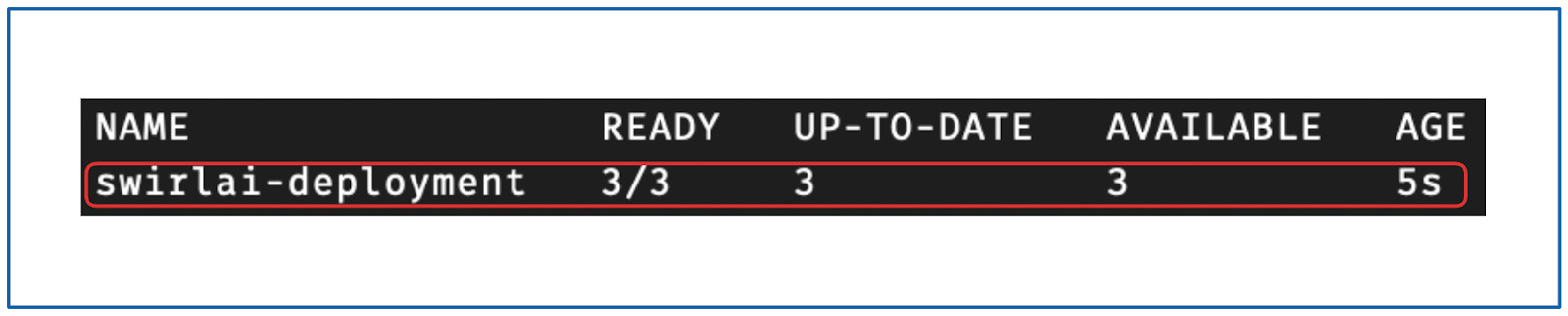
检查创建结果:
kubectl get deployments -n swirlai
你将看到类似以下的输出:
{kind=link}
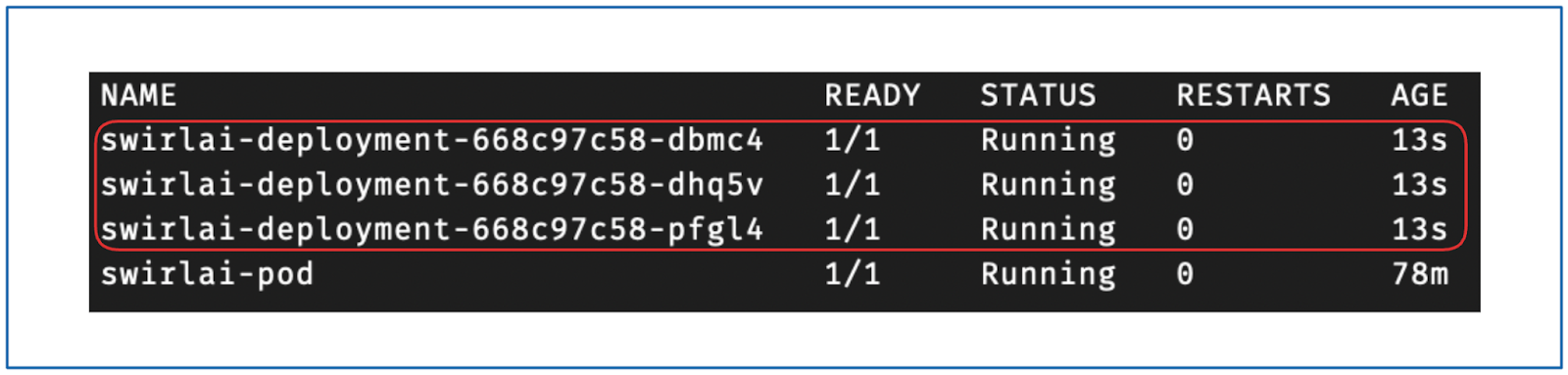
你还可以检查 Deployment 创建的 Pod:
kubectl get pods -n swirlai
你将看到类似以下的输出:
{kind=link}
服务(Services)
有时 Deployment 本身就能满足需求,例如流式应用。但更常见的情况是,Deployment 用于部署实时服务(如实时机器学习服务),其他应用需要通过 REST API 等方式访问这些服务。为了实现对 Deployment 管理的应用集合的访问,并平衡流量,你需要为应用集合配置负载均衡器。在 Kubernetes 中,这一角色由 Service 资源承担,充当集群内部的简单负载均衡器。
Service 需绑定到共享相同标签集的 Pod 组上,因此注意不要在同一命名空间内的多个 Deployment 上重复使用相同标签集。
#### 创建 Service
在 swirlai 命名空间中创建一个名为 swirlai-service 的 Service。该 Service 为之前创建的 swirlai-deployment 管理的 Pod 平衡流量。保存为 service.yaml:
apiVersion: v1
kind: Service
metadata:
name: swirlai-service
namespace: swirlai
spec:
selector:
app: swirlai
ports:
- protocol: TCP
port: 80
targetPort: 80
应用配置:
kubectl apply -f service.yaml
检查创建结果:
kubectl get services -n swirlai
你将看到类似以下的输出:
{kind=link}
注意:此 Service 仅在 Kubernetes 集群内部可访问,主要用于与其他集群内服务通信。如果需要直接访问,可以在集群内创建跳板 Pod,通过 SSH 进入后使用命令行工具访问。也可以将 Service 暴露到集群外部,后续系列将详细介绍。
结语
本期内容就到这里。通过掌握本文介绍的 Kubernetes 资源,我们已经能够实现 SwirlAI 项目实践系列中的大多数应用架构。
来源链接:https://www.newsletter.swirlai.com/p/a-guide-to-kubernetes-part-1