这是 Kubernetes 系列文章的第二部分。
在第一部分中,我们提到容器组(Pods)几乎从不单独使用,因为单独管理 Pods 的扩展性较差,类似于直接管理原始容器——你需要定义多个 Pods,并确保它们始终运行。因此,Kubernetes 提供了多种专门的工作负载资源,帮助你自动管理和扩展 Pods 集合,只需定义相应的规则即可。
在今天的文章中,我们将深入探讨在 Kubernetes 集群中部署 Pods 集合的不同方式。上一篇文章已经介绍了一种方式——部署(Deployment)。本期我们将回顾 Deployment,并介绍另外两种方式:任务(Job)和定时任务(CronJob),它们弥补了 Deployment 的一些不足。完整的四种方式包括:
- 部署(Deployment)
- 任务(Job)和定时任务(CronJob)
- 守护进程集(DaemonSet)
- 有状态集(StatefulSet)
本期将重点讲解:
- 部署(Deployment)
- 任务(Job)和定时任务(CronJob)
同时,我会为每种方式提供:
- 应用场景
- 示例 Kubernetes 资源定义文件,方便你在本地或远程 Kubernetes 集群中创建这些资源
阅读前提: 本指南假设你已完成第一部分中的所有设置要求,因为这些是跟进本教程的基础。此外,建议完整阅读第一部分内容,因为本文会直接使用其中的术语,不再赘述。
为什么需要了解 Kubernetes 中所有应用部署方式?
假设你已经开发了一个应用,将其容器化,并以容器组(Pods)的形式部署到 Kubernetes 中。这是部署单个软件系统实例的方式。然而,你的系统很可能由多个应用组成,你需要在集群中运行多组应用。它们执行不同类型的工作,并以不同方式相互通信。为了扩展整个应用流程,你需要针对系统的不同部分采用水平扩展(增加实例数量)和垂直扩展(提升实例性能)的方式。
这就是管理容器组(Pods)集合的不同方式发挥作用的地方。如果你已经在实际工作中接触过 Kubernetes,或者即将开始使用,你很快会发现,仅使用部署(Deployment)来管理所有类型的应用在某些特定功能上会有所不足。
让我们从基础开始,逐步分析每种应用部署方式的功能局限性。我们先从部署(Deployment)讲起。
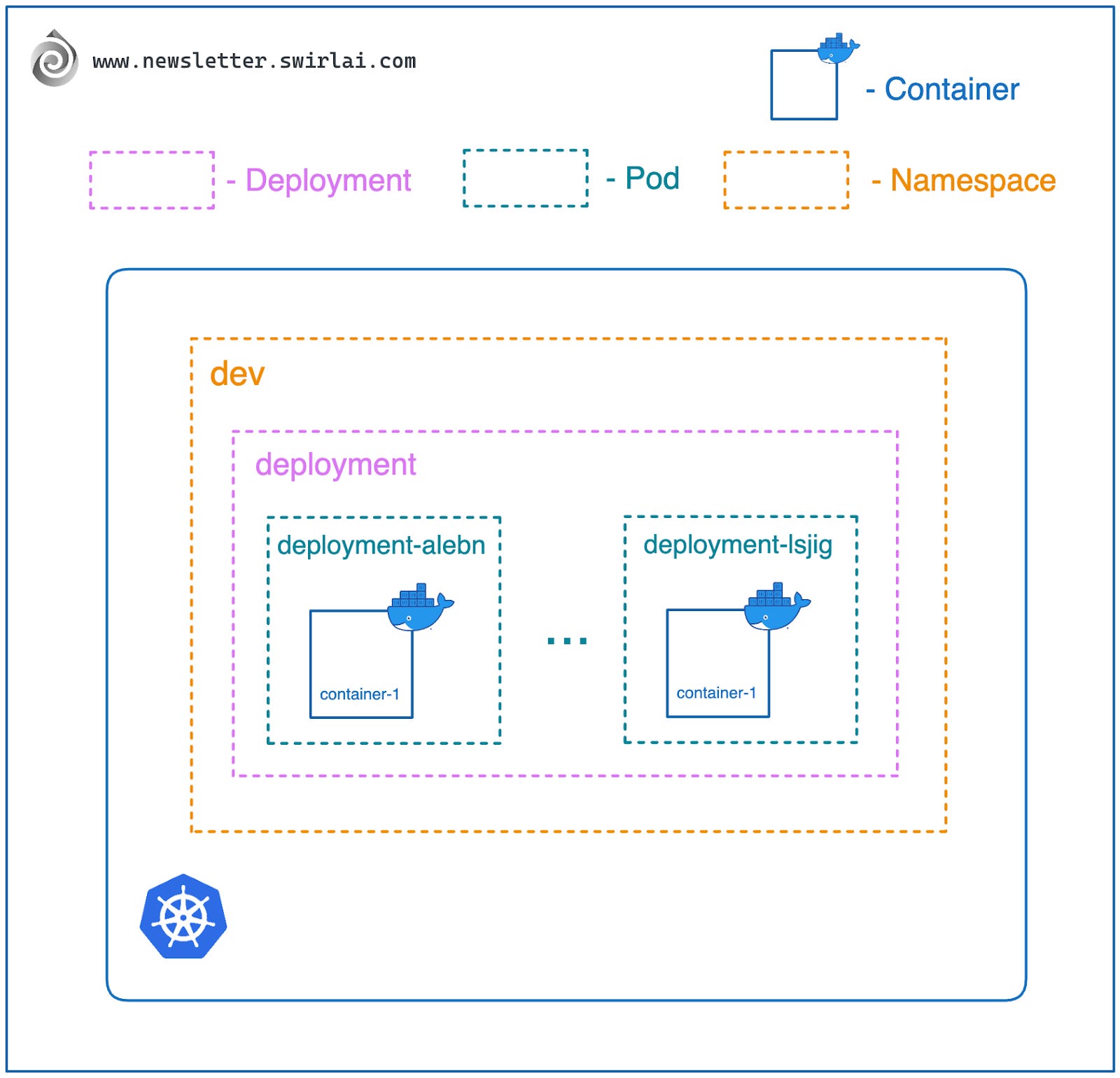
部署(Deployment)
部署(Deployment)是 Kubernetes 中用于管理无状态应用的关键资源。它是一种管理多个相同容器组(Pod)副本的方式,主要用于处理不需要状态保存的应用。让我们详细了解 Deployment 的具体功能和使用方法。
- 你可以定义希望在 Kubernetes 集群中运行的 Pod 副本数量,Deployment 会确保始终有指定数量的 Pod 在运行。
- Deployment 会为每个 Pod 分配唯一的名称,名称通常以 Deployment 的名称为前缀,后缀为随机值,如 deployment-name-。
- Deployment 负责发布 Pod 的新版本。当你更新 Pod 定义时,Deployment 会根据你设定的规则逐步发布新版本。它通过创建新的副本集(ReplicaSet,用于管理 Pod 副本)来管理 Pod 集合,同时逐步关闭旧版本。
- Deployment 还支持将应用回滚到之前的版本,回滚过程与发布新版本类似。
{kind=link}
创建一个部署(Deployment)
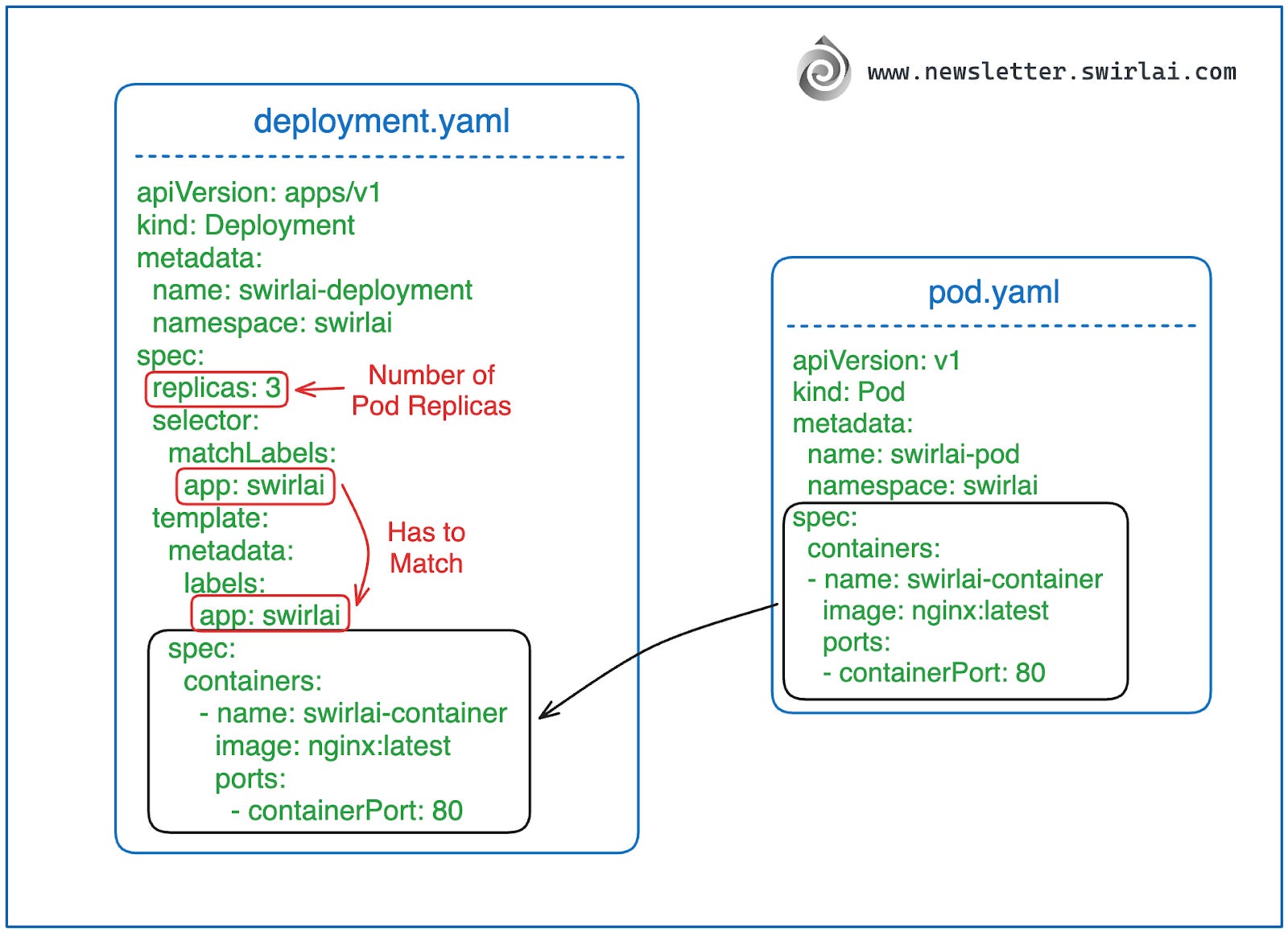
接下来,我们回顾如何创建 Deployment。与第一部分类似,本指南将使用 YAML 格式的 Kubernetes 资源定义文件来创建资源。
首先,如果你还没有用于部署应用的命名空间,可以通过以下命令创建一个:
kubectl create namespace swirlai
与之前的教程一样,我们将应用部署到 swirlai 命名空间中。请将以下内容保存到一个名为 deployment.yaml 的文件中:
apiVersion: apps/v1
kind: Deployment
metadata:
name: swirlai-deployment
namespace: swirlai
spec:
replicas: 3
selector:
matchLabels:
app: swirlai
template:
metadata:
labels:
app: swirlai
spec:
containers:
- name: swirlai-container
image: nginx:latest
ports:
- containerPort: 80
为了简化示例,我们在每个 Pod 中部署一个 Nginx 容器。如果你对更复杂的部署感兴趣,可以参考 SwirlAI 数据工程项目主模板实现的第一部分(链接),其中我们编写并部署了一个完整的 FastAPI 服务,并将其作为 Deployment 部署到集群中,与其他应用进行通信。
保存文件后,运行以下命令:
kubectl apply -f deployment.yaml
通过以下命令检查是否正确执行:
kubectl get deployments -n swirlai
{kind=link}
可以看到,3 个 Pod 已成功启动并正常运行。
Deployment 资源的定义很容易从原始 Pod 资源定义中推导出来。Deployment 有一些独特的属性,但 .spec.template.spec 下的内容与 Pod 资源定义文件中的 .spec 完全一致。
{kind=link}
如果删除 Deployment 管理的其中一个 Pod 会怎样?
让我们来尝试一下:
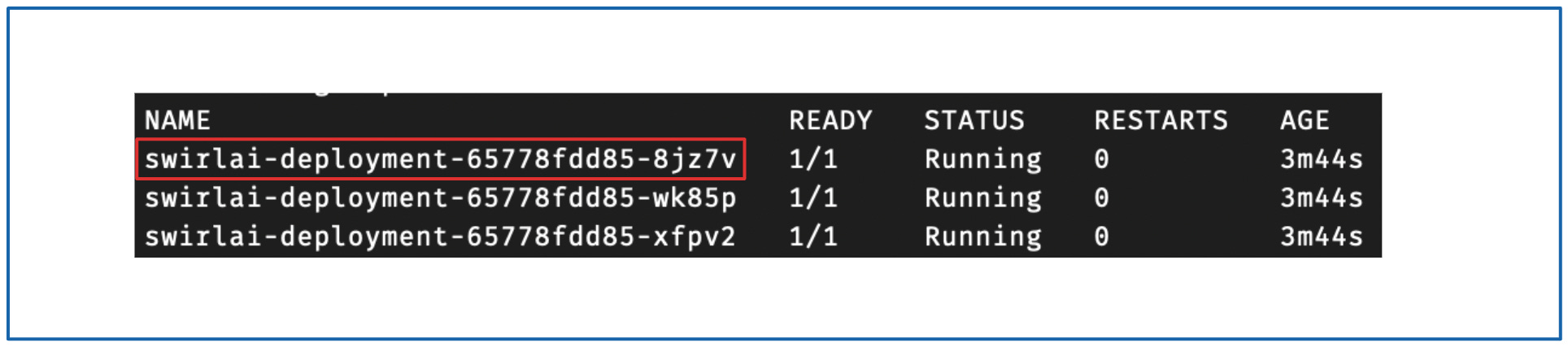
kubectl get pods -n swirlai
{kind=link}
记下其中一个 Pod 的名称并删除它:
kubectl delete pod swirlai-deployment-65778fdd85-8jz7v -n swirlai
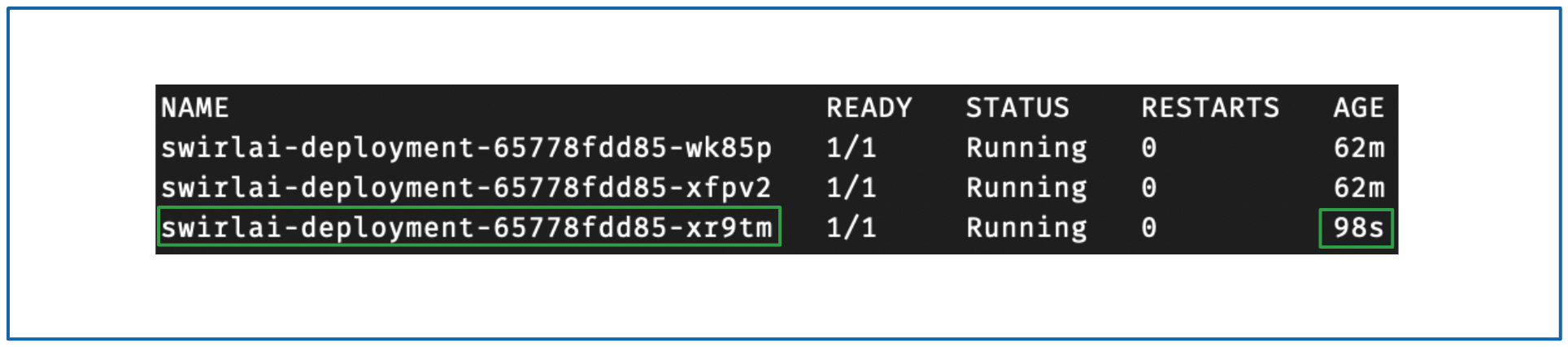
删除后查看结果:
kubectl get pods -n swirlai
{kind=link}
不出所料,被删除的 Pod 会被 Kubernetes 控制器重新创建,并分配一个新的 Pod 名称。
部署(Deployment)的应用场景
- 无状态微服务:常规的 Web 应用几乎总是以 Deployment 形式部署,因为它们设计为持续运行,并从其他应用接收工作指令。
- 流式应用:当应用 ID 由所使用的流式框架自动管理时,也常使用 Deployment。
总结: Deployment 就像一个自动化工厂,确保始终有指定数量的工人(Pod)在工作,适合管理需要长期运行的无状态应用。
为什么 Deployment 不够用?
尽管 Deployment 在管理持续运行的应用方面表现出色,但它也有局限性。你可能已经注意到,Deployment 适用于管理持续运行的应用。如果应用发生故障,或者你删除了 Deployment 管理的某个 Pod,系统会尝试重启 Pod,以恢复到你通过 Deployment 资源定义的期望状态。那么,如何管理那些执行有限工作量、完成后需要停止或退出的应用呢?这就是任务(Job)和定时任务(CronJob)的适用场景。
任务(Job)和定时任务(CronJob)
任务(Job)的设计弥补了 Deployment 无法运行有限工作的缺陷。一个典型例子是数据提取任务:你下载所需数据,将其推送到下游数据系统,然后终止应用。虽然有一些专门针对数据工程师的框架,如 Airflow,但 Kubernetes 原生支持通过 Job 和 CronJob 实现这一功能。
- 你可以定义 Pod 需要以成功状态退出的次数。
- 你可以定义并行度(parallelism),即同时启动多少个 Pod 执行工作。每次成功退出都会计入所需的成功次数。
- Job 会不断启动新的 Pod,确保运行中的 Pod 数量等于定义的并行度,直到达到成功次数目标。
- 你可以定义 Pod 失败时的重试次数上限。
- 与 Deployment 类似,Job 会为每个 Pod 分配唯一名称,名称以 Job 名称为前缀,后缀为随机值。
在继续之前,请先清理我们的命名空间:
kubectl delete deployments -n swirlai --all
为什么先讲任务(Job)?
在 SwirlAI 数据工程项目主模板实现的第一部分(链接)中,我们将数据生产者部分实现为 Deployment。但在现实场景中,这种应用通常会通过类似 Airflow 的框架调度,或者直接在 Kubernetes 上以 Job 或 CronJob 形式部署,具体取决于是按计划持续提取数据还是一次性提取。在下一期的 SwirlAI 数据工程项目主模板系列中,我们会将该应用改写为 Job 形式。
创建一个成功的任务(Job)
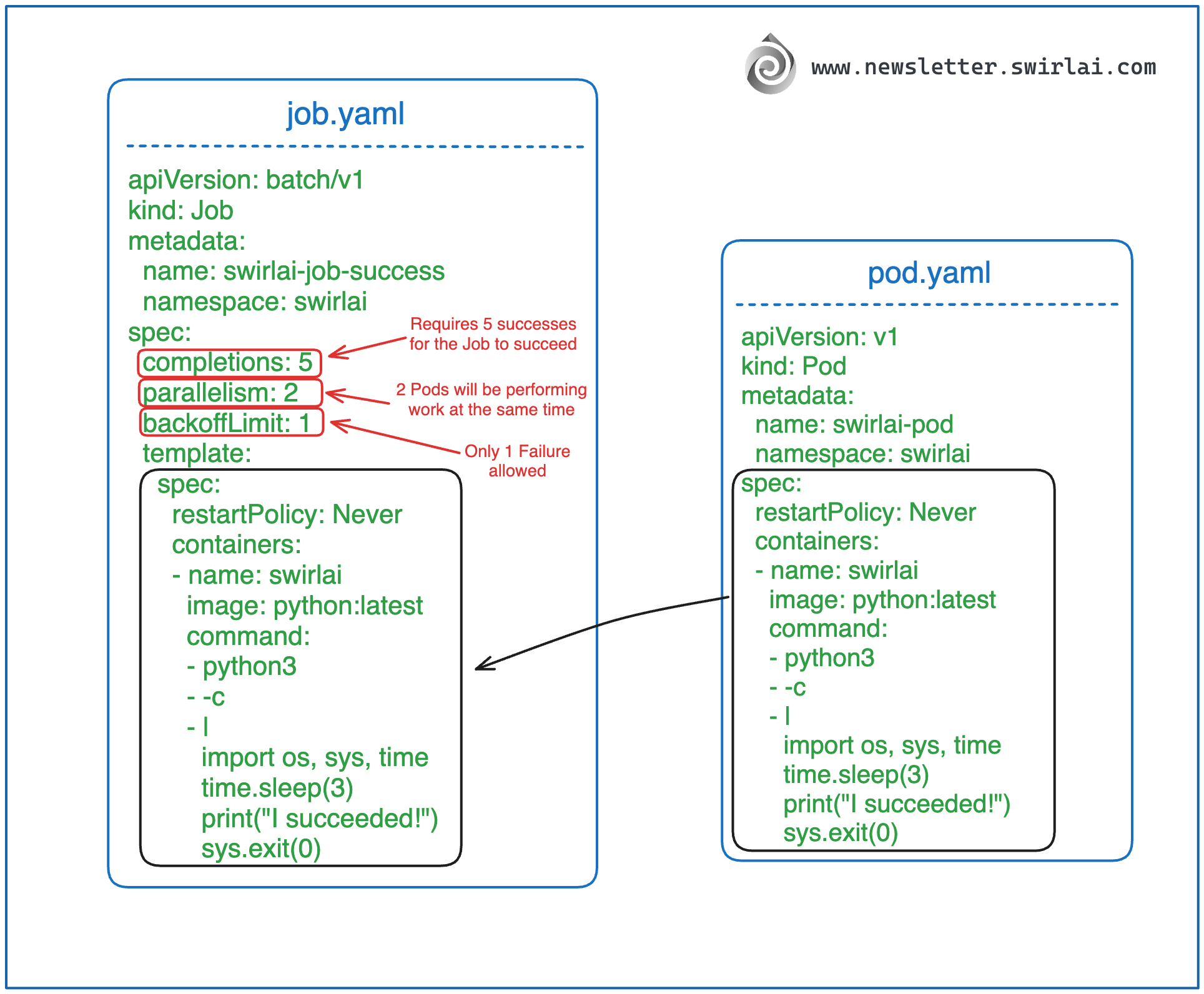
将以下代码保存到名为 job.yaml 的文件中:
apiVersion: batch/v1
kind: Job
metadata:
name: swirlai-job-success
namespace: swirlai
spec:
completions: 5
parallelism: 2
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: swirlai
image: python:latest
command:
- python3
- -c
- |
import os, sys, time
time.sleep(3)
print("I succeeded!")
sys.exit(0)
以下是一些定义的说明:
- 我们仍在 swirlai 命名空间中创建 Job。
- Job 命名为 swirlai-job-success,因为我们期望它成功完成。
- 根据 .spec.completions 的设置,我们期望有 5 个 Pod 以成功状态完成任务。
- 根据 .spec.parallelism,系统会同时保持 2 个 Pod 运行,直到完成所需的 5 次成功。
- 根据 .spec.backoffLimit,我们只允许 1 次失败。
{kind=link}
与 Deployment 类似,Job 只需要在 .spec.template.spec 下插入 Pod 定义。在本例中,我们使用 Python 容器并在其中执行以下 Python 代码:
import os, sys, time
time.sleep(3)
print("I succeeded!")
sys.exit(0)
这段代码非常简单:休眠 3 秒,打印“I succeeded!”,然后以状态码 0 退出,表示脚本成功执行。
创建 Job:
kubectl apply -f job.yaml
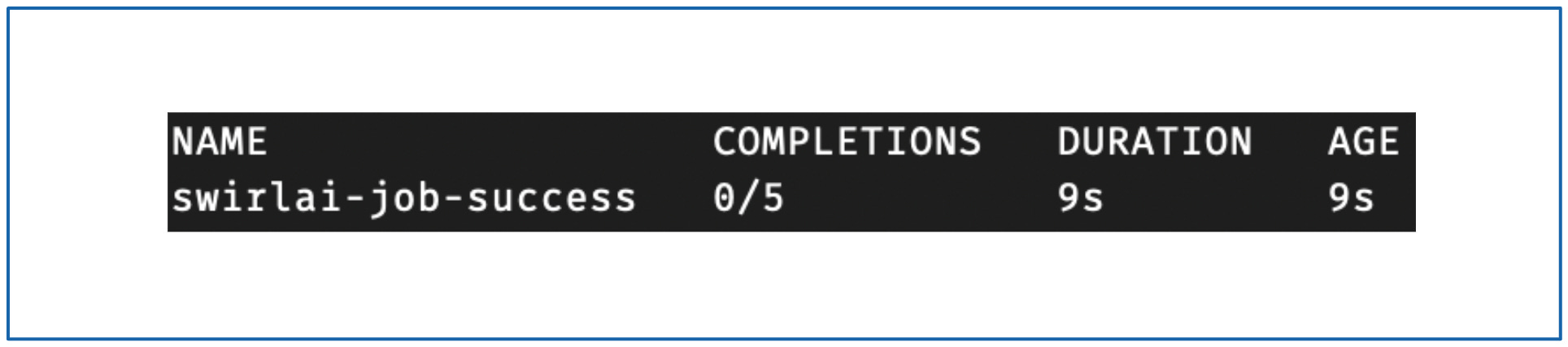
通过以下命令检查状态:
kubectl get jobs -n swirlai
最初你可能会看到类似以下内容:
{kind=link}
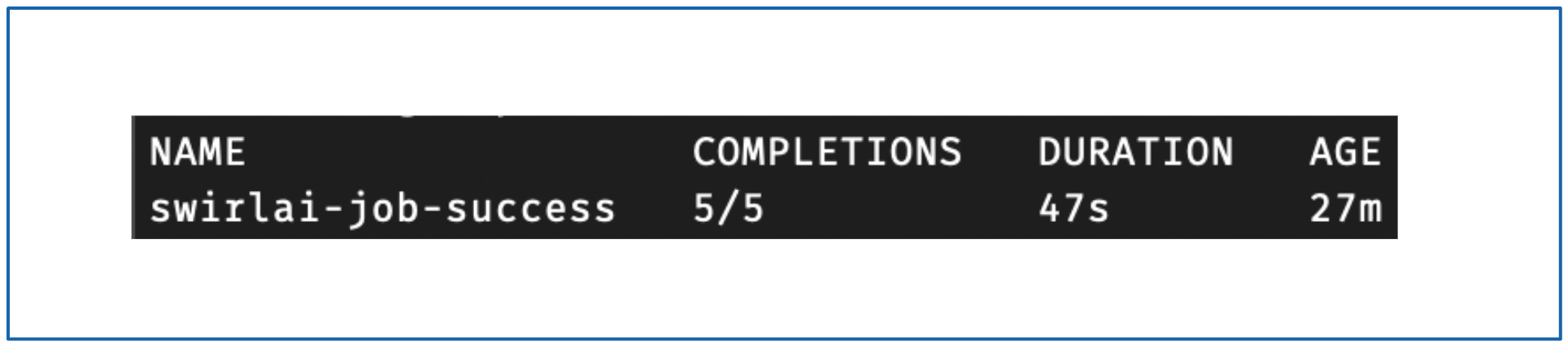
大约一分钟后,运行相同命令,你应该会看到:
{kind=link}
这表示 Job 已成功完成。如果你运行:
kubectl get pods -n swirlai
你会看到类似以下内容:
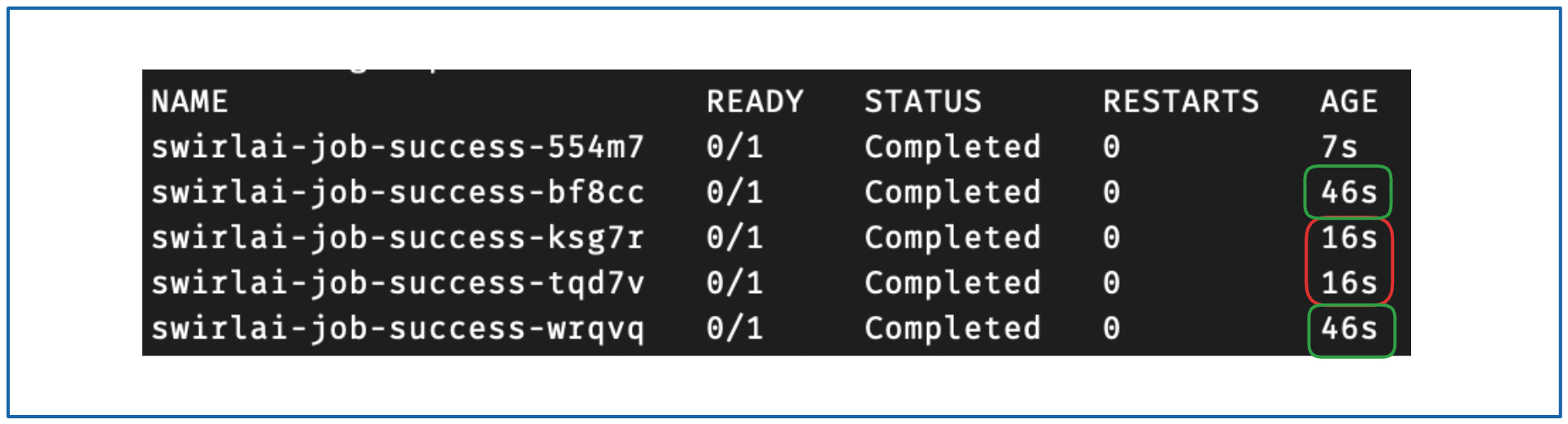{kind=link}
这显示了由 Job 管理的 5 个成功执行的 Pod。从年龄(Age)列可以看出,Pod 是以 2 个一组执行的,最后一个单独完成。以下图片展示了 Job 成功完成的过程:
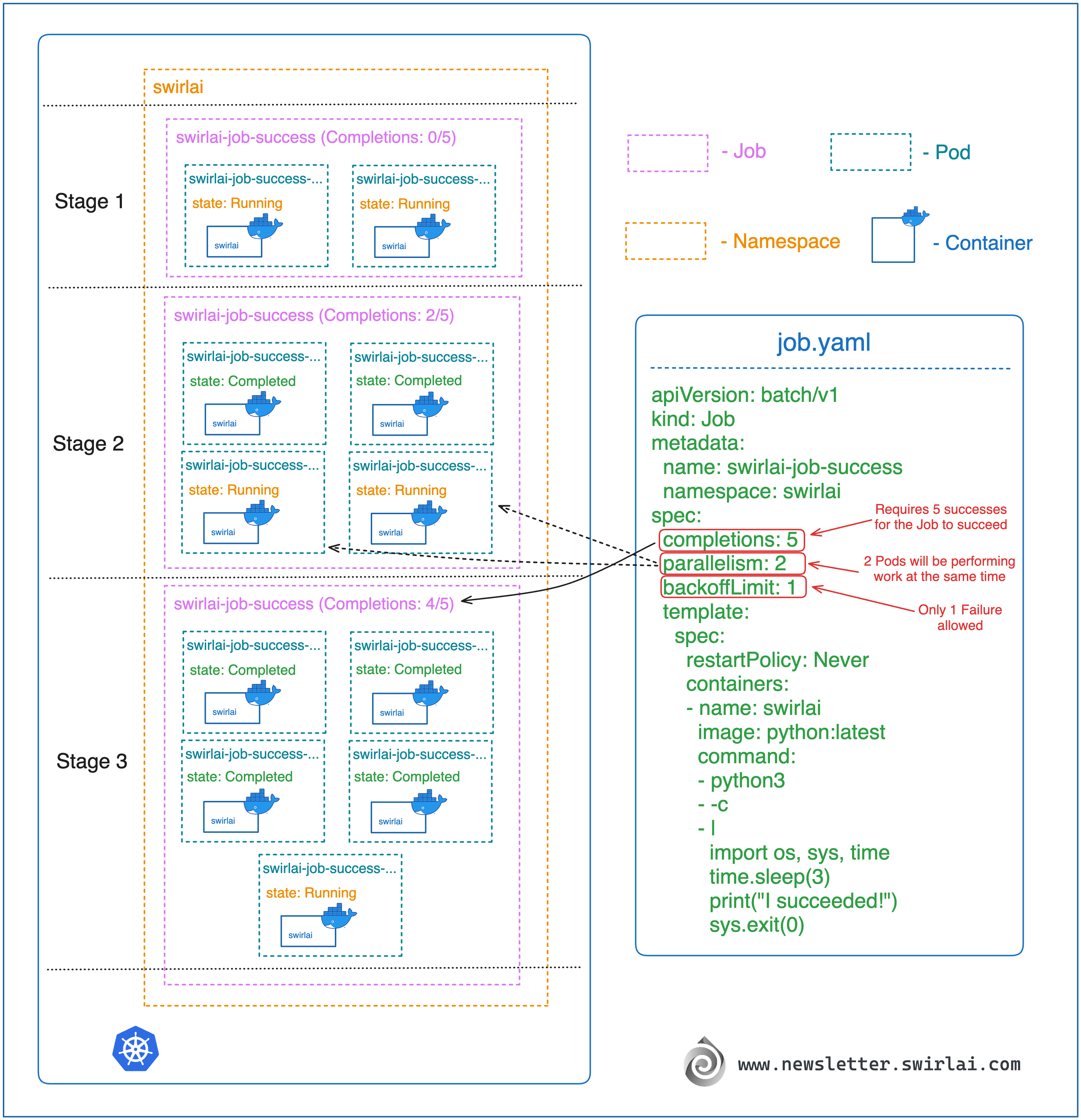{kind=link}
创建一个失败的任务(Job)
让我们对容器内执行的脚本进行一个小修改:
import os, sys, time
time.sleep(3)
print("I Failed :(")
sys.exit(1)
将以下内容保存到名为 job-fail.yaml 的文件中:
apiVersion: batch/v1
kind: Job
metadata:
name: swirlai-job-failure
namespace: swirlai
spec:
completions: 5
parallelism: 2
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: swirlai
image: python:latest
command:
- python3
- -c
- |
import os, sys, time
time.sleep(3)
print("I Failed :(")
sys.exit(1)
现在,代码将以状态码 1 失败退出。让我们看看 Job 会发生什么:
kubectl apply -f job-fail.yaml
通过以下命令检查结果:
kubectl get jobs -n swirlai
{kind=link}
Job 的状态不会再有变化——它已经失败。你可以通过以下命令检查 Pod:
kubectl get pods -n swirlai
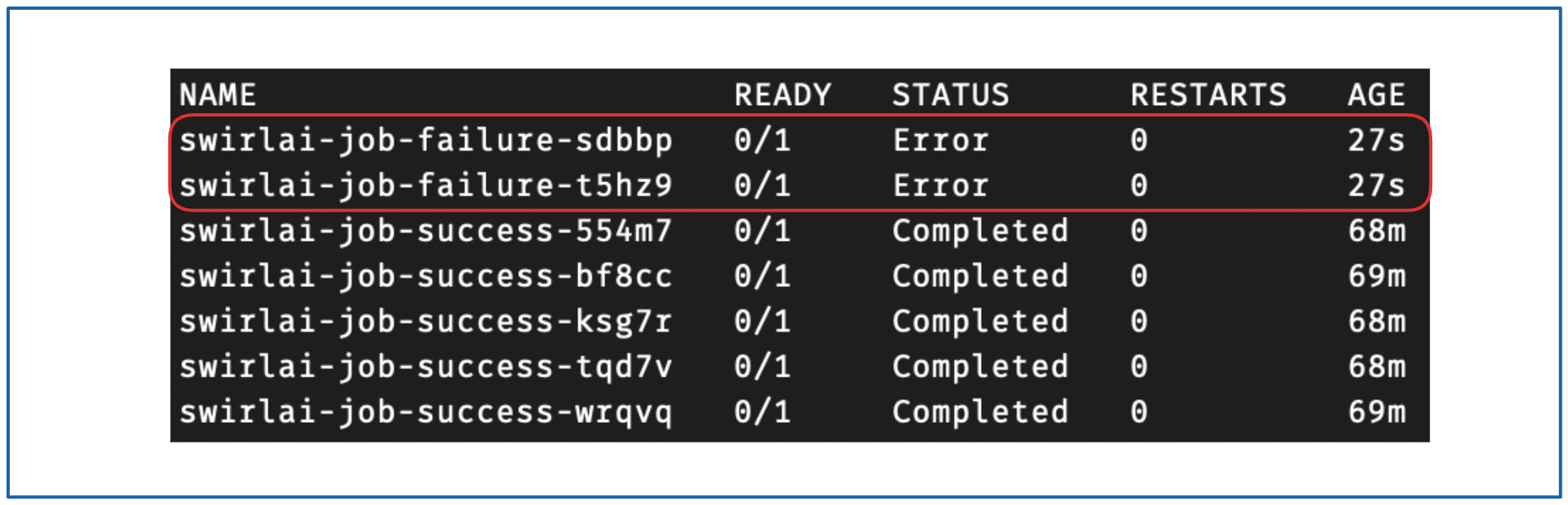{kind=link}
正如预期,根据 .spec.parallelism,我们启动了 2 个 Pod。第一次失败后,Job 控制器判定任务失败,没有尝试启动新的 Pod 以达到所需的成功次数。以下图片描述了 Job 经历的阶段:
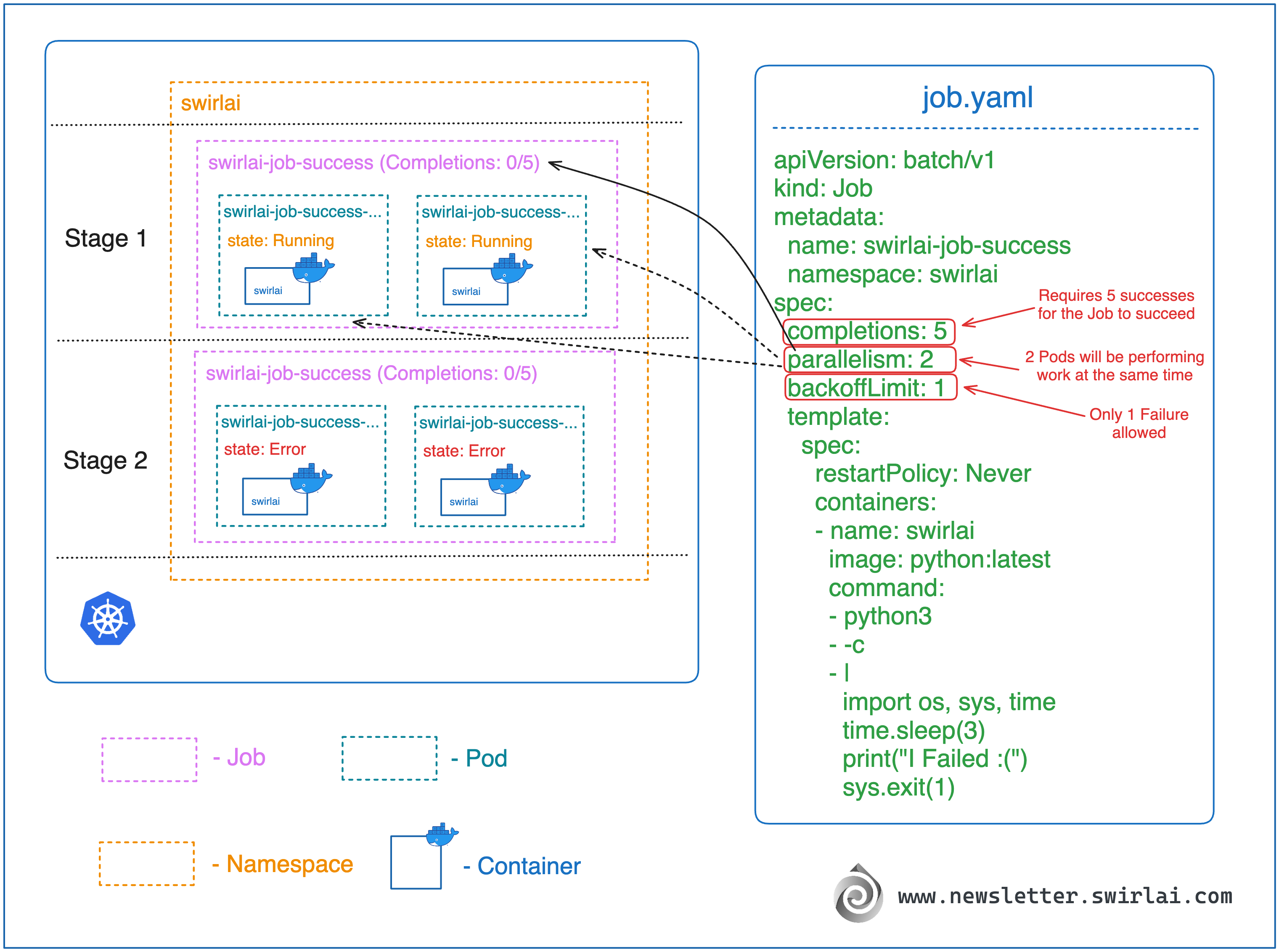{kind=link}
虽然 Job 解决了运行有限工作量应用的需求,但如果你希望按计划定期执行这些工作,手动操作仍然很繁琐。这就是定时任务(CronJob)的用武之地。
定时任务(CronJob)
定时任务(CronJob)的名称非常直观,它的作用正是按 Cron 计划创建 Job。例如,我们创建一个 CronJob,每分钟创建之前定义的成功 Job。
将以下代码保存到名为 cronjob.yaml 的文件中:
apiVersion: batch/v1
kind: CronJob
metadata:
name: swirlai-cronjob-success
namespace: swirlai
spec:
schedule: " *"
jobTemplate:
spec:
completions: 5
parallelism: 2
backoffLimit: 1
template:
spec:
restartPolicy: Never
containers:
- name: swirlai
image: python:latest
command:
- python3
- -c
- |
import os, sys, time
time.sleep(3)
print("I succeeded!")
sys.exit(0)
与 Job 资源定义相比,CronJob 的语法非常直观,二者关系如下图所示:
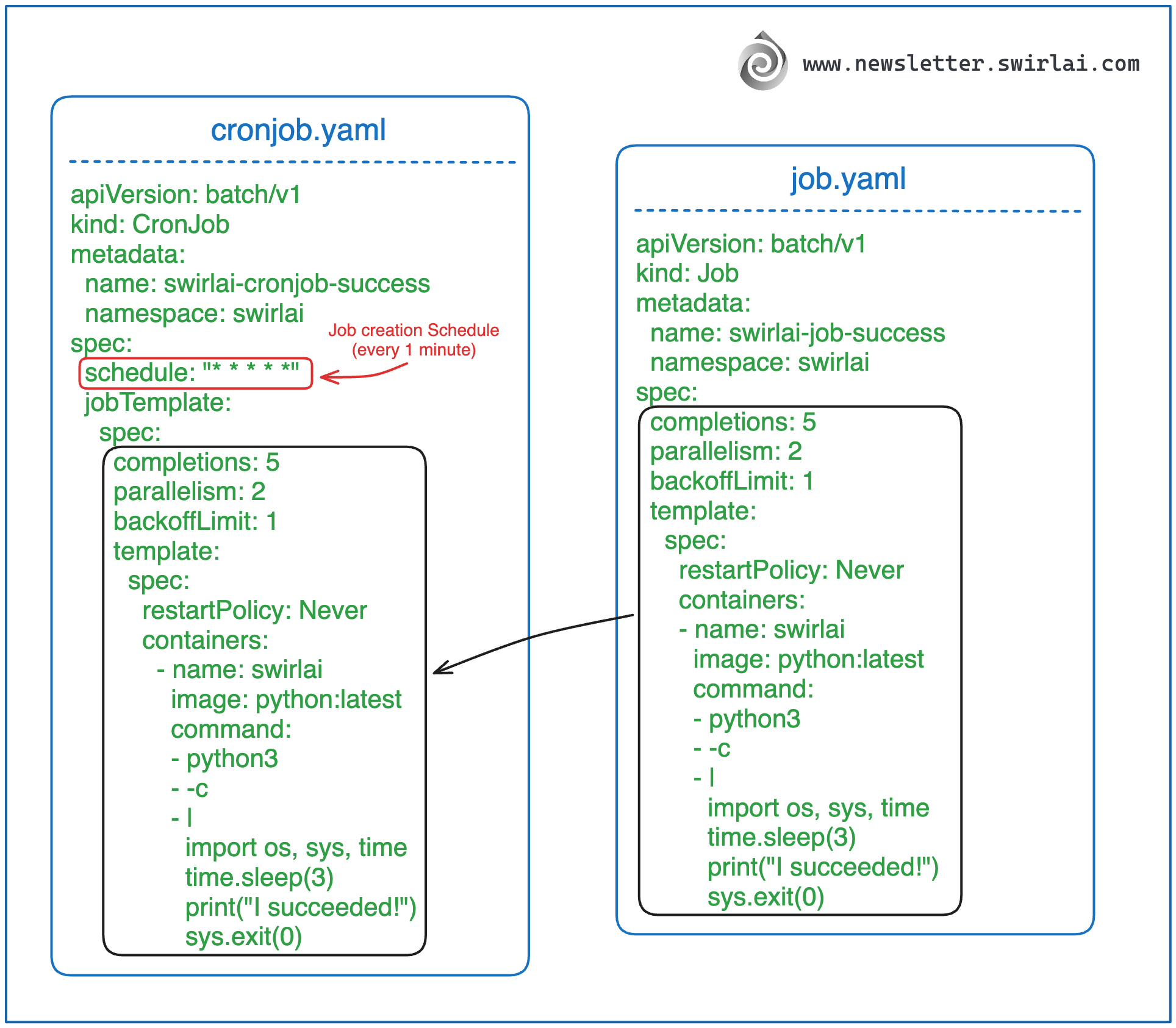{kind=link}
创建 CronJob:
kubectl apply -f cronjob.yaml
让 Kubernetes 运行几分钟,然后执行:
kubectl get jobs -n swirlai
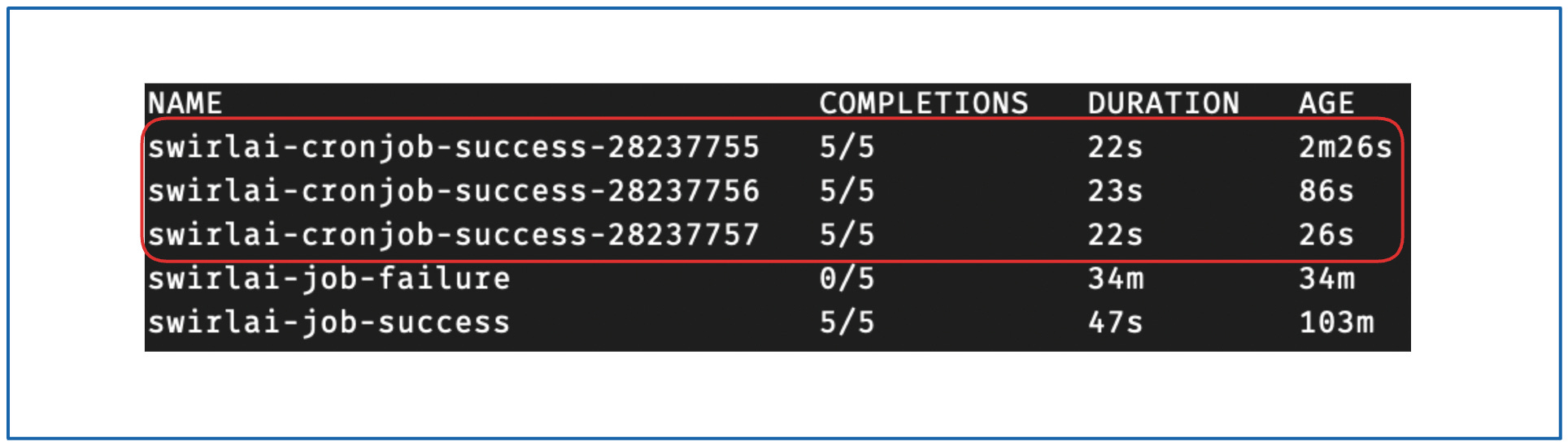{kind=link}
3 分钟后,可以看到 CronJob 已创建了 3 个新的 Job,且均以成功状态完成。
任务(Job)和定时任务(CronJob)的应用场景
- ETL 任务:如果你在 ETL(提取、转换、加载)流程中执行数据提取或转换任务,这些任务通常以最终状态为目标。更常见的是,它们会被安排定期运行,比如每天运行一次。当然,你可能会使用 Airflow 这样的框架来满足数据工程需求,但直接在 Kubernetes 上运行也是一种选择。
- 数据库模式更新:对正在运行的数据库模式进行更新。
- 文件系统或数据库准备:为依赖这些资源的其他应用准备文件系统或数据库。虽然可以手动完成,但在 Kubernetes 上部署完整生产系统时,通常会将数据库准备任务作为资源定义的一部分。Job 经常与 Deployment 配合使用,尽管 Deployment 本身是无状态的,但它们往往依赖于远程数据库的状态。
- 清理任务:可以是一次性任务,也可以是定时任务,用于清理文件系统以释放空间,确保应用正常运行。
总结: Job 适合执行一次性任务,如数据导入和清理,确保任务完成后自动停止。而 CronJob 则像一个定时器,定期触发这些任务。