这篇LLM pretraining的内容主要是基于Sebastian Raschka, PhD在youtube上发布的Building LLMs from the Ground Up: A 3-hour Coding Workshop,并结合自己的理解进行整理。
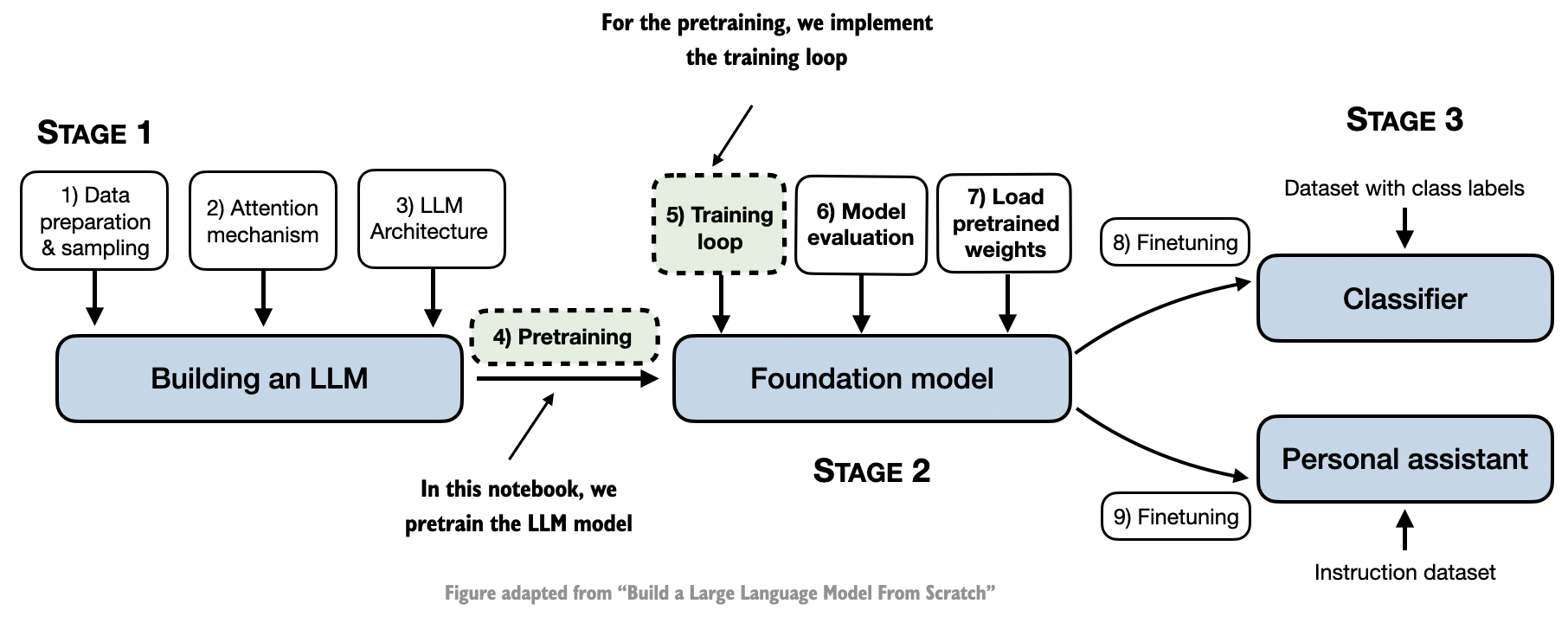
目录
- 目录
- 1. 简介
- 预训练与微调的关系
- 2. 环境配置
- 2.1 硬件要求
- 2.2 必要依赖包
- 2.3 不同操作系统配置
- 2.4 虚拟环境设置
- 2.5 检查环境
- 3. 模型架构
- 3.1 Transformer基本结构
- 3.2 模型配置参数
- 3.3 位置编码详解
- 3.4 多头注意力机制
- 3.5 前馈网络与激活函数
- 3.6 不同规模模型对比
- 4. 数据准备
- 4.1 数据预处理
- 4.2 加载原始文本
- 文本统计
- 数据分割
- 创建数据加载器
- 数据加载器说明
- 5. 训练流程
- 5.1 初始化
- 5.2 训练循环
- 5.3 优化器选择
- 5.4 学习率调度
- 5.5 分布式训练
- 5.6 训练加速技术
- 5.7 训练稳定性
- 执行训练
- 6. 损失计算
- 6.1 交叉熵损失详解
- 6.2 其他损失函数
- 6.3 损失计算实现
- 7. 评估与可视化
- 7.1 损失曲线绘制
- 7.2 评估指标详解
- 7.3 任务特定评估
- 7.4 早停策略
- 7.5 高级可视化技术
- 8. 文本生成
- 8.1 解码策略详解
- 8.2 温度参数调节
- 8.3 长文本生成
- 8.4 辅助函数
- 8.5 生成样例
- 9. 模型保存与加载
- 9.1 保存模型
- 9.2 加载模型
- 9.3 模型量化技术
- 9.4 模型导出格式
- 9.5 模型部署最佳实践
- 10. 常见问题
- 10.1 过拟合问题
- 10.2 计算资源限制
- 10.3 生成质量问题
- 10.4 多语言训练考量
- 10.5 伦理与安全问题
- 11. 参考资源
- 学习资料
- 工具与库
- 社区与论坛
- 12. 练习部分
- 练习1:使用预训练LLM生成文本
- 练习2:在新会话中加载预训练模型
- 练习3(可选):使用自己喜欢的文本训练LLM
1. 简介
大型语言模型(LLM)预训练是通过使模型预测文本序列中的下一个词元(token)来学习语言模式的过程。本文档基于GPT风格架构,详细介绍了LLM预训练的全流程,包括数据处理、模型配置、训练循环、评估方法以及文本生成。
尽管实际大型LLM预训练需要大量计算资源(如Llama 2 7B需要在A100 GPU上耗费184,320小时训练2万亿个词元),本指南使用小型数据集作为教学示例,让您可以在个人计算机上快速理解整个流程。
预训练与微调的关系
预训练是让模型在大规模语料上学习语言知识的过程,而微调则是在预训练基础上针对特定任务进行调整。两者关系如下:
- 预训练:在大规模、多样化文本上进行,目标是学习通用语言表示
- 微调:在特定领域/任务数据上进行,目标是适应特定应用场景
- 零样本/少样本学习:预训练足够好的模型可以直接应用到新任务,无需或仅需少量样本
2. 环境配置
2.1 硬件要求
根据不同规模模型的训练需求,硬件配置要求各不相同:
| 模型规模 | GPU内存 | 系统内存 | 推荐GPU | 训练时间估计 |
|---------|--------|---------|--------|------------|
| 小型(124M) | 8GB+ | 16GB+ | RTX 3060 12GB+ | 数小时至数天 |
| 中型(1-3B) | 24GB+ | 64GB+ | RTX 3090/4090, A100 | 数天至数周 |
| 大型(7B+) | 40GB+ | 128GB+ | A100 40/80GB, H100 | 数周至数月 |
| 超大型(70B+) | 分布式 | 1TB+ | 多A100/H100集群 | 数月 |
对于本教程的小型模型:
- 最低配置:8GB显存GPU或16GB内存CPU
- 推荐配置:NVIDIA GPU (RTX 2060 6GB+),16GB系统内存
- 存储空间:至少10GB可用空间
2.2 必要依赖包
在虚拟环境中安装
pip install torch==2.0.1 tiktoken==0.5.1 matplotlib==3.7.2 numpy==1.24.3 scikit-learn==1.2.2 nltk==3.8.1
如需使用fasttext进行语言检测,添加
pip install fasttext==0.9.2
如需创建Web服务,添加
pip install flask==2.3.2
对于GPU加速,确保安装匹配的CUDA版本:
对于CUDA 11.8
pip install torch==2.0.1+cu118 -f https://download.pytorch.org/whl/torch_stable.html
2.3 不同操作系统配置
Linux (Ubuntu/Debian):
安装系统依赖
sudo apt-get update
sudo apt-get install -y build-essential python3-dev python3-pip
macOS:
使用Homebrew安装依赖
brew install python cmake
对于Apple Silicon (M1/M2)
pip install torch torchvision torchaudio
Windows:
安装Visual C++ Build Tools
下载并安装:https://visualstudio.microsoft.com/visual-cpp-build-tools/
2.4 虚拟环境设置
创建虚拟环境
python -m venv llm_venv激活虚拟环境
Linux/macOS
source llm_venv/bin/activate
Windows
llm_venv\Scripts\activate升级pip
pip install --upgrade pip
2.5 检查环境
from importlib.metadata import version
import torch检查包版本
pkgs = ["matplotlib", "numpy", "tiktoken", "torch"]
for p in pkgs:
print(f"{p} version: {version(p)}")检查CUDA可用性
print(f"CUDA available: {torch.cuda.is_available()}")
if torch.cuda.is_available():
print(f"CUDA version: {torch.version.cuda}")
print(f"GPU device: {torch.cuda.get_device_name(0)}")
print(f"GPU memory: {torch.cuda.get_device_properties(0).total_memory / 1e9:.2f} GB")
3. 模型架构
3.1 Transformer基本结构
GPT使用Transformer架构的解码器部分,整体结构如下:
输入词元序列
↓
嵌入层 (Embedding)
↓
位置编码 (Positional Encoding)
↓
N层Transformer块:
↓
├── 多头自注意力机制 (Masked Multi-Head Attention)
| ↓
├── Layer Normalization
| ↓
├── 前馈神经网络 (Feed Forward Network)
| ↓
└── Layer Normalization
↓
线性层 + Softmax
↓
输出词元概率
每个Transformer块包含两个主要子层:多头自注意力机制和前馈神经网络,每个子层后都有一个残差连接和层归一化。
3.2 模型配置参数
我们使用GPT架构,配置一个参数规模约为1.24亿的模型:
import torch
from supplementary import GPTModelGPT_CONFIG_124M = {
"vocab_size": 50257, # 词汇表大小
"context_length": 256, # 上下文长度(原始GPT-2为1024)
"emb_dim": 768, # 嵌入维度
"n_heads": 12, # 注意力头数量
"n_layers": 12, # Transformer层数
"drop_rate": 0.1, # Dropout率
"qkv_bias": False # 查询-键-值偏置
}
model = GPTModel(GPT_CONFIG_124M)
model.eval() # 推理模式,禁用dropout
参数详解:
- vocab_size: 模型词汇表大小,影响嵌入层参数量和输出层大小
- context_length: 模型处理的最大序列长度,影响位置编码和内存消耗
- emb_dim: 词嵌入和隐藏层维度,直接影响模型容量和计算量
- n_heads: 多头注意力的头数,通常为emb_dim的因数,更多的头能捕捉不同方面的关系
- n_layers: Transformer块的数量,增加层数提高模型容量但增加训练难度
- drop_rate: Dropout比率,控制正则化强度,防止过拟合
- qkv_bias: 是否在注意力计算中使用偏置向量,现代LLM趋向于不使用
3.3 位置编码详解
位置编码是Transformer架构中至关重要的一部分,因为自注意力机制本身不包含位置信息:
1. 正弦余弦位置编码(最初的Transformer方法):
import numpy as np
import torch
def get_sinusoid_encoding_table(n_position, d_hid):
def cal_angle(position, hid_idx):
return position / np.power(10000, 2 * (hid_idx // 2) / d_hid)
def get_posi_angle_vec(position):
return [cal_angle(position, hid_j) for hid_j in range(d_hid)]
sinusoid_table = np.array([get_posi_angle_vec(pos_i) for pos_i in range(n_position)])
sinusoid_table[:, 0::2] = np.sin(sinusoid_table[:, 0::2]) # 偶数维度使用sin
sinusoid_table[:, 1::2] = np.cos(sinusoid_table[:, 1::2]) # 奇数维度使用cos
return torch.FloatTensor(sinusoid_table)
2. 可学习位置编码(如GPT-2使用):
初始化可学习的位置嵌入
self.position_embeddings = nn.Parameter(torch.zeros(1, context_length, emb_dim))
位置编码的核心思想是为序列中不同位置的词元提供区分性的表示,确保模型能够感知词元的相对或绝对位置。
3.4 多头注意力机制
多头注意力机制允许模型在不同子空间学习不同的表示:
import torch
import torch.nn as nn
import torch.nn.functional as F
import math
class MultiHeadAttention(nn.Module):
def __init__(self, emb_dim, n_heads, qkv_bias=False, dropout=0.0):
super().__init__()
self.emb_dim = emb_dim
self.n_heads = n_heads
self.head_dim = emb_dim // n_heads # 每个头的维度
# 创建查询、键、值的线性层
self.q_proj = nn.Linear(emb_dim, emb_dim, bias=qkv_bias)
self.k_proj = nn.Linear(emb_dim, emb_dim, bias=qkv_bias)
self.v_proj = nn.Linear(emb_dim, emb_dim, bias=qkv_bias)
self.out_proj = nn.Linear(emb_dim, emb_dim)
self.dropout = nn.Dropout(dropout)
def forward(self, x, mask=None):
batch_size = x.size(0)
# 线性变换
q = self.q_proj(x)
k = self.k_proj(x)
v = self.v_proj(x)
# 拆分为多头
q = q.view(batch_size, -1, self.n_heads, self.head_dim).transpose(1, 2)
k = k.view(batch_size, -1, self.n_heads, self.head_dim).transpose(1, 2)
v = v.view(batch_size, -1, self.n_heads, self.head_dim).transpose(1, 2)
# 注意力计算
scores = torch.matmul(q, k.transpose(-2, -1)) / math.sqrt(self.head_dim)
# 应用掩码(用于因果注意力)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
# 应用softmax获取注意力权重
attn_weights = F.softmax(scores, dim=-1)
attn_weights = self.dropout(attn_weights)
# 加权求和
context = torch.matmul(attn_weights, v)
# 合并多头
context = context.transpose(1, 2).contiguous().view(batch_size, -1, self.emb_dim)
# 最终线性投影
output = self.out_proj(context)
return output
注意力机制的核心是计算查询(Q)与键(K)的相似度,然后使用这个相似度来加权对应的值(V):
1. 将输入拆分为多个头
2. 为每个头计算注意力权重:attention = softmax(QK^T / sqrt(head_dim))
3. 使用注意力权重加权值:output = attention * V
4. 合并多头输出
3.5 前馈网络与激活函数
Transformer的前馈网络通常是两个线性层,中间有激活函数:
class FeedForward(nn.Module):
def __init__(self, emb_dim, dropout=0.0):
super().__init__()
self.fc1 = nn.Linear(emb_dim, 4 * emb_dim)
self.fc2 = nn.Linear(4 * emb_dim, emb_dim)
self.activation = nn.GELU() # GELU比ReLU在LLM中表现更好
self.dropout = nn.Dropout(dropout)
激活函数对比:
- ReLU: 简单且高效,但存在"死亡ReLU"问题
- GELU: 现代LLM普遍使用,接近ReLU但更平滑
- SwiGLU: 在PaLM和其他新型模型中使用,性能更好但计算成本更高
3.6 不同规模模型对比
GPT系列不同规模模型参数对比:
| 参数 | GPT-2小型(124M) | GPT-2中型(355M) | GPT-2大型(774M) | GPT-2超大型(1.5B) |
|------|----------------|----------------|----------------|------------------|
| 层数 | 12 | 24 | 36 | 48 |
| 注意力头 | 12 | 16 | 20 | 25 |
| 嵌入维度 | 768 | 1024 | 1280 | 1600 |
| 上下文长度 | 1024 | 1024 | 1024 | 1024 |
| 参数计算 | 12×((768×768×3)+(768×768×2))... | ... | ... | ... |
模型参数量计算:
- 嵌入层:vocab_size × emb_dim
- 注意力层:每层3个矩阵(Q,K,V),每个emb_dim × emb_dim
- 前馈网络:每层2个矩阵,emb_dim × (4×emb_dim)和(4×emb_dim) × emb_dim
- 层归一化:每层4个参数向量,每个长度为emb_dim
- 输出层:emb_dim × vocab_size
4. 数据准备
4.1 数据预处理
高质量训练数据对于LLM性能至关重要,预处理步骤包括:
1. 文本清洗:
import re
def clean_text(text):
# 移除HTML标签
text = re.sub(r'<.*?>', '', text)
# 标准化空白字符
text = re.sub(r'\s+', ' ', text)
# 移除URL
text = re.sub(r'https?://\S+|www\.\S+', '', text)
# 移除重复标点
text = re.sub(r'([.,!?])\1+', r'\1', text)
return text.strip()
2. 去重:移除完全相同或高度相似的文本片段
from hashlib import md5
def dedup_texts(texts):
seen_hashes = set()
unique_texts = []
for text in texts:
text_hash = md5(text.encode()).hexdigest()
if text_hash not in seen_hashes:
seen_hashes.add(text_hash)
unique_texts.append(text)
return unique_texts
3. 语言过滤:只保留特定语言的文本
# 注意:需要先安装 fasttext
# pip install fasttext
import fasttext
# 预先下载语言检测模型
# 可从 https://fasttext.cc/docs/en/language-identification.html 获取
model = fasttext.load_model('lid.176.bin')
def filter_by_language(texts, target_lang='en'):
filtered_texts = []
for text in texts:
predictions = model.predict(text)
lang = predictions[0][0].replace('__label__', '')
if lang == target_lang:
filtered_texts.append(text)
return filtered_texts
4. 质量过滤:移除低质量内容
4.2 加载原始文本
with open("the-verdict.txt", "r", encoding="utf-8") as file:
text_data = file.read()
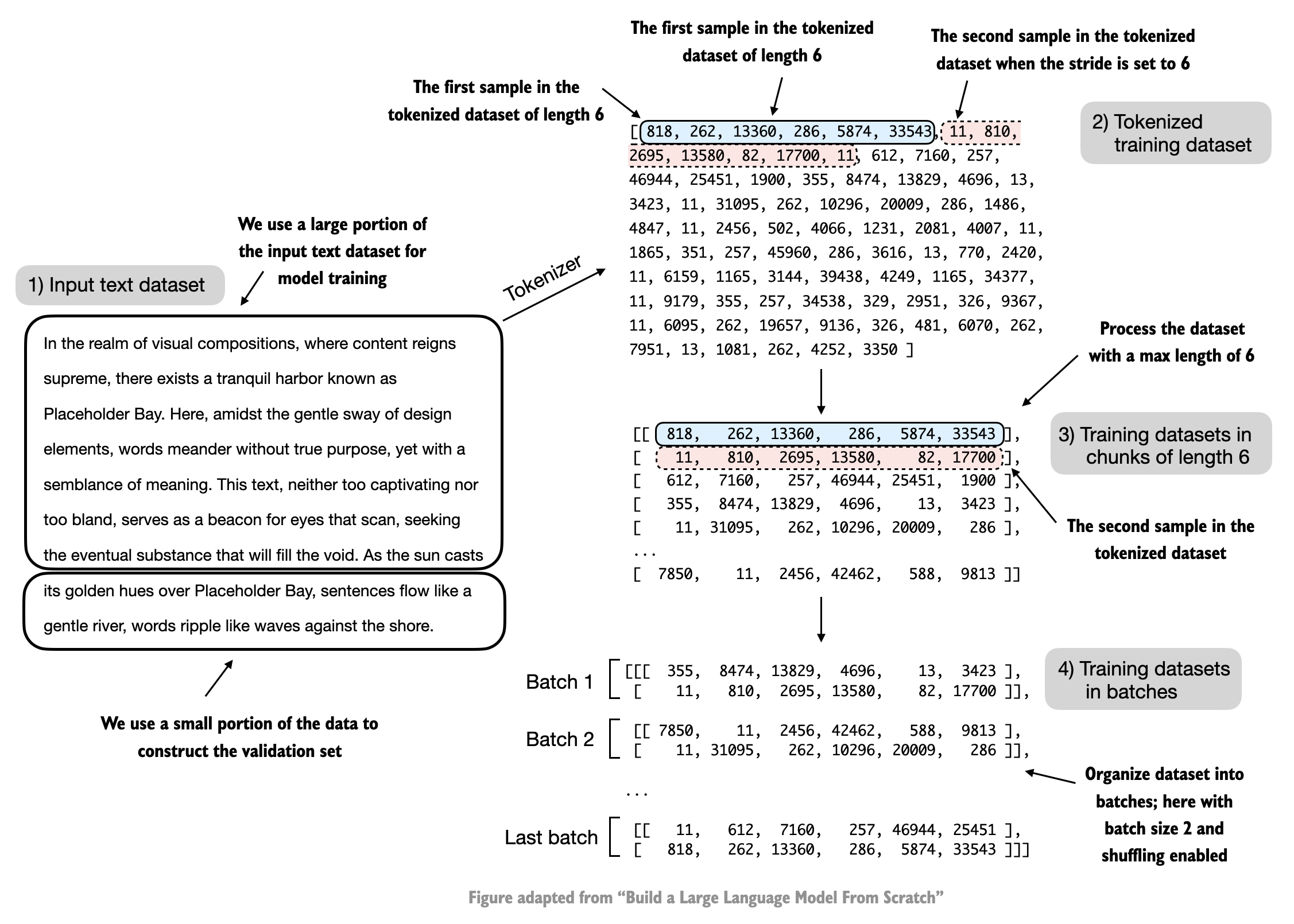{kind=link}
该图展示了数据加载与处理的完整流程:
- 使用滑动窗口对文本进行分块
- 每个窗口提取context_length长度的文本片段
- 目标序列比输入序列向右偏移一个位置
- 显示了批量大小为2的情况
文本统计
total_characters = len(text_data)
total_tokens = len(tokenizer.encode(text_data))
print(f"字符数: {total_characters}")
print(f"词元数: {total_tokens}")
数据分割
训练/验证比例
train_ratio = 0.90
split_idx = int(train_ratio * len(text_data))
train_data = text_data[:split_idx]
val_data = text_data[split_idx:]
创建数据加载器
以下是DataLoader创建的参考实现
import torch
from torch.utils.data import Dataset, DataLoader
import tiktokenclass TextDataset(Dataset):
def __init__(self, text, tokenizer, max_length, stride):
self.text = text
self.tokenizer = tokenizer
self.max_length = max_length
self.stride = stride
self.tokens = tokenizer.encode(text)
def __len__(self):
return (len(self.tokens) - self.max_length) // self.stride + 1
def __getitem__(self, idx):
start_idx = idx * self.stride
end_idx = start_idx + self.max_length
# 输入序列
input_ids = torch.tensor(self.tokens[start_idx:end_idx], dtype=torch.long)
# 目标序列(向右偏移一个位置)
target_ids = torch.tensor(self.tokens[start_idx+1:end_idx+1], dtype=torch.long)
return input_ids, target_ids
def create_dataloader_v1(text, batch_size, max_length, stride, drop_last=True, shuffle=True, num_workers=0):
tokenizer = tiktoken.get_encoding("gpt2")
dataset = TextDataset(text, tokenizer, max_length, stride)
return DataLoader(
dataset,
batch_size=batch_size,
shuffle=shuffle,
drop_last=drop_last,
num_workers=num_workers
)
数据加载器说明
- 滑动窗口:使用stride等于max_length确保输入序列之间无重叠
- 目标偏移:目标序列始终比输入序列向右偏移一个位置
- 小批量大小:使用较小的批量大小(2)以减少计算资源需求
- 批量丢弃:训练时丢弃不完整批次,验证时保留所有数据
5. 训练流程
5.1 初始化
torch.manual_seed(123) # 设置随机种子确保可重现性
model = GPTModel(GPT_CONFIG_124M)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device) # 移动模型到GPU(如果可用)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)
5.2 训练循环
import torch
import torch.nn.functional as Fdef train_model_simple(model, train_loader, val_loader, optimizer, device, num_epochs,
eval_freq, eval_iter, start_context, tokenizer):
# 初始化跟踪数据
train_losses, val_losses, track_tokens_seen = [], [], []
tokens_seen, global_step = 0, -1
# 定义评估函数
def evaluate_model(model, train_loader, val_loader, device, max_batches=None):
model.eval()
# 计算训练集损失
train_loss = calc_loss_loader(train_loader, model, device, max_batches)
# 计算验证集损失
val_loss = calc_loss_loader(val_loader, model, device, max_batches)
model.train()
return train_loss, val_loss
# 定义生成示例函数
def generate_and_print_sample(model, tokenizer, device, start_text, max_new_tokens=20):
model.eval()
input_ids = torch.tensor(tokenizer.encode(start_text)).unsqueeze(0).to(device)
with torch.no_grad():
# 简单贪婪解码
for _ in range(max_new_tokens):
# 获取模型预测
outputs = model(input_ids)
next_token_logits = outputs[:, -1, :]
next_token = torch.argmax(next_token_logits, dim=-1).unsqueeze(-1)
input_ids = torch.cat([input_ids, next_token], dim=1)
generated_text = tokenizer.decode(input_ids[0].tolist())
print(f"生成示例: {generated_text}")
model.train()
return generated_text
# 主训练循环
for epoch in range(num_epochs):
model.train() # 设置为训练模式
for input_batch, target_batch in train_loader:
optimizer.zero_grad() # 重置梯度
loss = calc_loss_batch(input_batch, target_batch, model, device)
loss.backward() # 计算梯度
optimizer.step() # 更新模型权重
tokens_seen += input_batch.numel()
global_step += 1
# 定期评估
if global_step % eval_freq == 0:
train_loss, val_loss = evaluate_model(
model, train_loader, val_loader, device, eval_iter)
train_losses.append(train_loss)
val_losses.append(val_loss)
track_tokens_seen.append(tokens_seen)
print(f"轮次 {epoch+1} (步骤 {global_step:06d}): "
f"训练损失 {train_loss:.3f}, 验证损失 {val_loss:.3f}")
# 每轮后生成样本文本
generate_and_print_sample(
model, tokenizer, device, start_context
)
return train_losses, val_losses, track_tokens_seen
计算批次损失
def calc_loss_batch(input_ids, target_ids, model, device):
"""计算单个批次的损失"""
input_ids = input_ids.to(device)
target_ids = target_ids.to(device)
# 前向传播获取logits
logits = model(input_ids)
# 计算损失(使用PyTorch内置的交叉熵损失)
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)),
target_ids.view(-1),
ignore_index=-1
)
return loss计算数据加载器上的损失
def calc_loss_loader(data_loader, model, device, max_batches=None):
"""计算数据加载器中所有批次的平均损失"""
model.eval() # 设置为评估模式
total_loss = 0
batch_count = 0
with torch.no_grad(): # 不需要计算梯度
for input_batch, target_batch in data_loader:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
batch_count += 1
if max_batches is not None and batch_count >= max_batches:
break
return total_loss / batch_count if batch_count > 0 else float('inf')
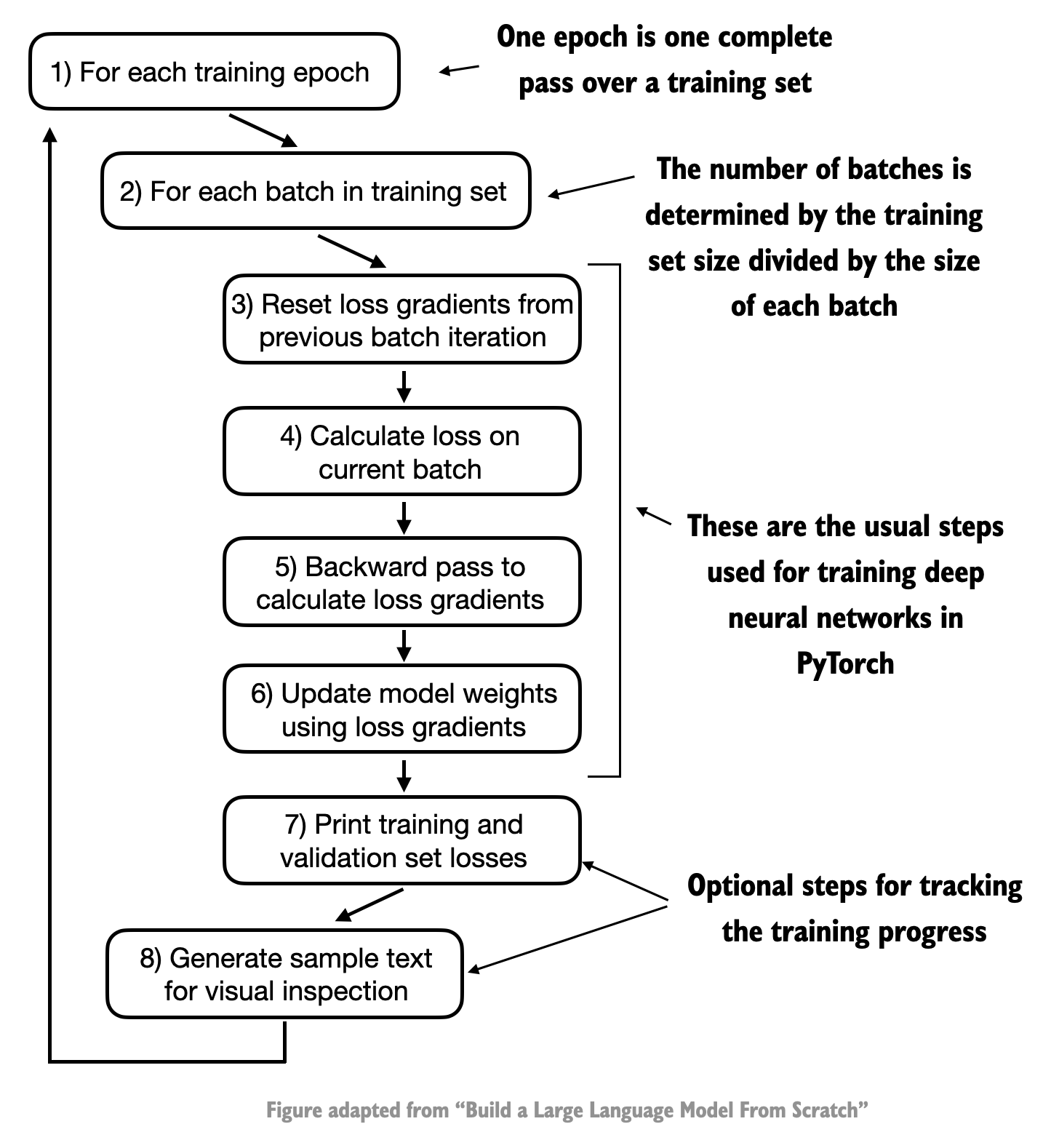{kind=link}
训练循环是LLM预训练的核心,完整的训练流程包括以下步骤:
1. 初始化模型和跟踪数据(损失值、处理的词元数等)
2. 对每个训练轮次(epoch)循环:
- 设置模型为训练模式
- 对每个批次的输入和目标:
- 重置梯度
- 计算损失
- 反向传播计算梯度
- 更新模型权重
- 跟踪处理的词元数
- 定期评估模型性能
- 每轮结束时生成样本文本
5.3 优化器选择
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)
5.4 学习率调度
学习率调度策略
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=7, gamma=0.1)
5.5 分布式训练
分布式训练设置示例
import torch.distributed as dist
from torch.utils.data.distributed import DistributedSampler
from torch.nn.parallel import DistributedDataParallel初始化分布式环境
def setup_distributed(rank, world_size):
dist.init_process_group(
backend='nccl', # 使用NCCL后端
init_method='tcp://localhost:12355',
world_size=world_size,
rank=rank
)创建分布式数据加载器
def create_distributed_dataloader(dataset, batch_size, rank, world_size):
sampler = DistributedSampler(
dataset,
num_replicas=world_size,
rank=rank
)
return DataLoader(
dataset,
batch_size=batch_size,
sampler=sampler
)分布式模型包装
def create_distributed_model(model, device_id):
return DistributedDataParallel(
model,
device_ids=[device_id]
)
5.6 训练加速技术
使用混合精度训练
scaler = torch.cuda.amp.GradScaler()
5.7 训练稳定性
使用早停策略
early_stopper = EarlyStopping(patience=3, delta=0.001)
执行训练
torch.manual_seed(123)
model = GPTModel(GPT_CONFIG_124M)
model.to(device)
optimizer = torch.optim.AdamW(model.parameters(), lr=0.0004, weight_decay=0.1)
num_epochs = 10
train_losses, val_losses, tokens_seen = train_model_simple(
model, train_loader, val_loader, optimizer, device,
num_epochs=num_epochs, eval_freq=5, eval_iter=5,
start_context="Every effort moves you", tokenizer=tokenizer
)
训练完成后,保存模型权重以便后续使用:
torch.save(model.state_dict(), "model.pth")
训练结果可视化:
epochs_tensor = torch.linspace(0, num_epochs, len(train_losses))
plot_losses(epochs_tensor, tokens_seen, train_losses, val_losses)
训练过程观察:
- 在训练初期,模型生成的文本是不连贯的单词串
- 随着训练进行,生成的文本逐渐形成语法正确的句子
- 从训练集和验证集损失曲线可以观察到过拟合现象
- 训练后期,模型倾向于直接记忆训练数据中的片段
过拟合分析:
- 过拟合在这个示例中特别明显,因为训练集非常小(仅一个短篇故事)
- 多次迭代同一小数据集导致模型简单记忆而非学习泛化能力
- 这种现象在实际大规模LLM训练中通过使用海量多样化数据来缓解
- 可以通过解码策略(如温度参数调节、top-k/top-p采样)在一定程度上减轻记忆问题
6. 损失计算
6.1 交叉熵损失详解
损失计算是LLM训练的核心,它衡量模型预测下一个词元的准确性:
import torch
import torch.nn.functional as F计算初始损失(训练前)
with torch.no_grad(): # 禁用梯度跟踪提高效率
train_loss = calc_loss_loader(train_loader, model, device)
val_loss = calc_loss_loader(val_loader, model, device)
交叉熵损失原理:
交叉熵损失测量预测分布与真实分布之间的差距。对于语言模型,我们用它来衡量模型预测下一个词的准确性:
def cross_entropy_loss(logits, targets):
"""
计算交叉熵损失
logits: [batch_size, seq_len, vocab_size] - 模型输出的未归一化概率
targets: [batch_size, seq_len] - 真实的目标词元索引
"""
# 将目标重塑为一维数组
targets = targets.reshape(-1)
# 将logits重塑为[batch_size*seq_len, vocab_size]
logits = logits.view(-1, logits.size(-1))
# 计算交叉熵损失
loss = F.cross_entropy(logits, targets, ignore_index=-1)
return loss
交叉熵损失的数学表达式:

对于语言模型,我们使用负对数似然作为训练目标,即最大化预测正确词元的概率:
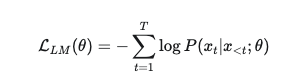
6.2 其他损失函数
除了标准的交叉熵损失,还可以考虑其他损失函数:
1. 带标签平滑的交叉熵:
import torch
import torch.nn.functional as F
def label_smoothed_cross_entropy(logits, targets, smoothing=0.1):
"""带标签平滑的交叉熵损失"""
confidence = 1.0 - smoothing
logprobs = F.log_softmax(logits, dim=-1)
# 创建平滑标签
nll_loss = -logprobs.gather(dim=-1, index=targets.unsqueeze(1))
nll_loss = nll_loss.squeeze(1)
smooth_loss = -logprobs.mean(dim=-1)
loss = confidence nll_loss + smoothing smooth_loss
return loss.mean()
2. KL散度损失:
def kl_divergence_loss(logits_student, logits_teacher, temperature=1.0):
"""知识蒸馏中使用的KL散度损失"""
log_softmax_student = F.log_softmax(logits_student / temperature, dim=-1)
softmax_teacher = F.softmax(logits_teacher / temperature, dim=-1)
loss = F.kl_div(log_softmax_student, softmax_teacher, reduction='batchmean')
return loss (temperature * 2)
6.3 损失计算实现
calc_loss_loader函数完整实现:
def calc_loss_batch(input_ids, target_ids, model, device):
"""计算单个批次的损失"""
input_ids = input_ids.to(device)
target_ids = target_ids.to(device)
# 前向传播获取logits
logits = model(input_ids)
# 计算损失(使用PyTorch内置的交叉熵损失)
loss = F.cross_entropy(
logits.view(-1, logits.size(-1)),
target_ids.view(-1),
ignore_index=-1
)
return loss
def calc_loss_loader(data_loader, model, device, max_batches=None):
"""计算数据加载器中所有批次的平均损失"""
model.eval() # 设置为评估模式
total_loss = 0
batch_count = 0
with torch.no_grad(): # 不需要计算梯度
for input_batch, target_batch in data_loader:
loss = calc_loss_batch(input_batch, target_batch, model, device)
total_loss += loss.item()
batch_count += 1
if max_batches is not None and batch_count >= max_batches:
break
return total_loss / batch_count if batch_count > 0 else float('inf')
7. 评估与可视化
7.1 损失曲线绘制
import matplotlib.pyplot as plt
def plot_losses(epochs, tokens_seen, train_losses, val_losses):
"""绘制训练和验证损失曲线"""
plt.figure(figsize=(12, 5))
# 绘制基于训练步骤的损失
plt.subplot(1, 2, 1)
plt.plot(epochs, train_losses, 'b-', label='训练损失')
plt.plot(epochs, val_losses, 'r-', label='验证损失')
plt.xlabel('训练轮次')
plt.ylabel('损失')
plt.title('训练进展')
plt.legend()
plt.grid(True)
# 绘制基于处理词元数的损失
plt.subplot(1, 2, 2)
plt.plot(tokens_seen, train_losses, 'b-', label='训练损失')
plt.plot(tokens_seen, val_losses, 'r-', label='验证损失')
plt.xlabel('处理词元数')
plt.ylabel('损失')
plt.title('词元处理进展')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
损失曲线展示了两种视角的训练进展:
1. 基于训练轮次的损失变化,展示模型随着训练轮次增加的学习趋势
2. 基于处理词元数的损失变化,展示模型随着处理更多数据的学习趋势
在训练过程中监控这些曲线有助于:
- 确定模型是否正在学习(损失是否下降)
- 识别过拟合开始的时间点(验证损失开始上升而训练损失继续下降)
- 判断是否需要调整学习率或应用早停
- 评估模型收敛速度和稳定性
7.2 评估指标详解
除了交叉熵损失,评估LLM还可以使用以下指标:
1. 困惑度(Perplexity, PPL):
困惑度是语言模型最常用的评估指标,它是交叉熵损失的指数:
import torch
def calculate_ppl(loss):
"""根据损失计算困惑度"""
return torch.exp(torch.tensor(loss))
困惑度可以解释为模型在每个位置上对词汇表的"不确定性",PPL越低,模型性能越好。
2. BLEU分数:
BLEU(Bilingual Evaluation Understudy)用于评估生成文本与参考文本的相似度:
需要先安装nltk: pip install nltk
from nltk.translate.bleu_score import sentence_bleu
def calculate_bleu(reference, candidate):
"""计算BLEU分数
reference: 参考文本分词列表的列表
candidate: 生成文本分词列表
"""
return sentence_bleu([reference], candidate)
3. ROUGE分数:
ROUGE(Recall-Oriented Understudy for Gisting Evaluation)用于评估生成摘要:
需要先安装rouge: pip install rouge
from rouge import Rouge
def calculate_rouge(reference, candidate):
"""计算ROUGE分数
reference: 参考文本
candidate: 生成文本
"""
rouge = Rouge()
scores = rouge.get_scores(candidate, reference)
return scores[0]
7.3 任务特定评估
对于特定任务,可以使用专门的评估方法:
1. 问答能力评估:
def evaluate_qa(model, qa_dataset, tokenizer, device):
"""评估问答能力
返回准确率、F1分数等
"""
correct = 0
total = 0
for question, answer in qa_dataset:
# 生成回答
predicted = generate_answer(model, question, tokenizer, device)
# 评估回答与标准答案的相似度
if is_correct_answer(predicted, answer):
correct += 1
total += 1
return correct / total
2. 推理能力评估:
def evaluate_reasoning(model, reasoning_dataset, tokenizer, device):
"""评估逻辑推理能力"""
# 实现推理任务评估逻辑
pass
7.4 早停策略
早停是一种防止过拟合的技术,在验证损失开始增加时停止训练:
class EarlyStopping:
"""早停策略实现"""
def __init__(self, patience=5, min_delta=0.0):
self.patience = patience
self.min_delta = min_delta
self.counter = 0
self.best_loss = None
self.early_stop = False
def __call__(self, val_loss):
if self.best_loss is None:
self.best_loss = val_loss
elif val_loss > self.best_loss - self.min_delta:
self.counter += 1
if self.counter >= self.patience:
self.early_stop = True
else:
self.best_loss = val_loss
self.counter = 0
return self.early_stop
7.5 高级可视化技术
1. 注意力可视化:
import matplotlib.pyplot as plt
import torch
def visualize_attention(model, input_text, tokenizer, layer_idx=0, head_idx=0):
"""可视化指定层和注意力头的注意力权重"""
# 对输入文本进行编码
input_ids = tokenizer.encode(input_text, return_tensors="pt")
# 获取注意力权重
with torch.no_grad():
outputs = model(input_ids, output_attentions=True)
# 提取所需层和头的注意力权重
attention = outputs.attentions[layer_idx][0, head_idx].detach().cpu().numpy()
# 可视化
tokens = tokenizer.convert_ids_to_tokens(input_ids[0])
plt.figure(figsize=(10, 8))
plt.imshow(attention, cmap="viridis")
plt.colorbar()
plt.xticks(range(len(tokens)), tokens, rotation=90)
plt.yticks(range(len(tokens)), tokens)
plt.title(f"Layer {layer_idx}, Head {head_idx} Attention")
plt.tight_layout()
plt.show()
2. 嵌入空间可视化:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.decomposition import PCA
from sklearn.manifold import TSNE
def visualize_embeddings(model, words, tokenizer, method='pca'):
"""可视化词嵌入空间"""
# 获取词的嵌入向量
embeddings = []
for word in words:
token_id = tokenizer.encode(word)[0]
embedding = model.get_embedding(token_id).detach().cpu().numpy()
embeddings.append(embedding)
embeddings = np.array(embeddings)
# 降维
if method == 'pca':
reducer = PCA(n_components=2)
else:
reducer = TSNE(n_components=2)
reduced_embeddings = reducer.fit_transform(embeddings)
# 可视化
plt.figure(figsize=(10, 8))
plt.scatter(reduced_embeddings[:, 0], reduced_embeddings[:, 1], marker='o')
# 添加词标签
for i, word in enumerate(words):
plt.annotate(word, (reduced_embeddings[i, 0], reduced_embeddings[i, 1]))
plt.title(f"Word Embeddings visualized with {method.upper()}")
plt.grid(True)
plt.show()
8. 文本生成
8.1 解码策略详解
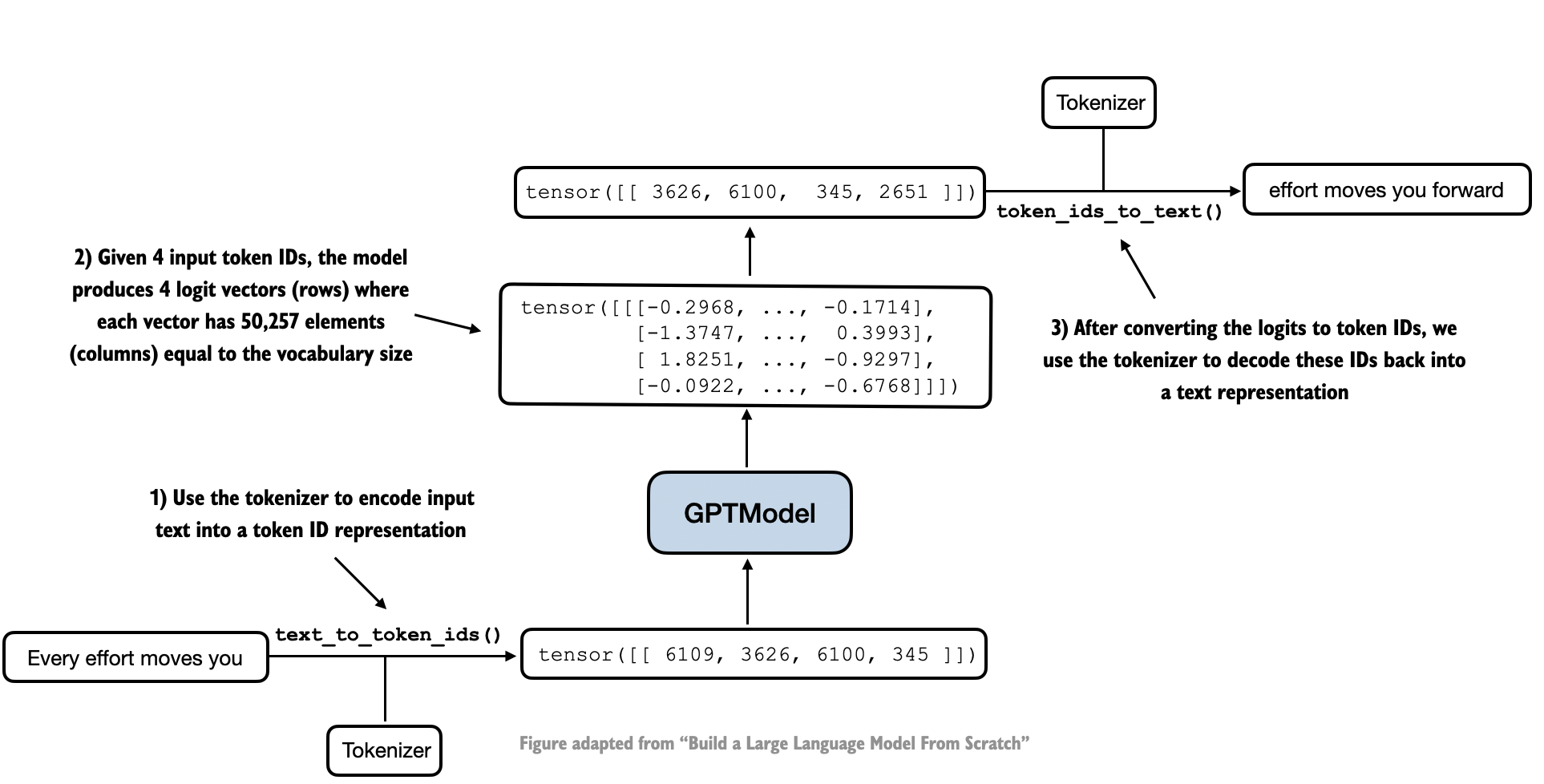{kind=link}
这个图展示了生成文本的过程:
1. 从起始文本获取词元ID
2. 通过模型预测下一个词元
3. 将预测的词元添加到序列中
4. 重复预测过程直到达到最大长度或生成结束标记
不同的解码策略会产生不同风格的文本:
1. 贪婪解码:
import torch
def greedy_decode(model, input_ids, max_length):
"""贪婪解码 - 每一步选择概率最高的词元"""
cur_ids = input_ids.clone()
for _ in range(max_length):
with torch.no_grad():
logits = model(cur_ids)
# 选择概率最高的词元
next_token_id = torch.argmax(logits[:, -1, :], dim=-1).unsqueeze(-1)
cur_ids = torch.cat([cur_ids, next_token_id], dim=-1)
# 检查是否生成了结束标记
if next_token_id.item() == 50256: # GPT-2的<|endoftext|>标记ID
break
return cur_ids
2. Beam Search解码:
import torch
import torch.nn.functional as F
def beam_search(model, input_ids, beam_size, max_length):
"""Beam Search解码 - 考虑多条可能路径"""
# 保存候选序列
sequences = [(input_ids, 0)] # (序列, 得分)
for _ in range(max_length):
all_candidates = []
# 扩展每个候选序列
for seq, score in sequences:
with torch.no_grad():
logits = model(seq)
# 获取最后一个词元的logits
next_token_logits = logits[:, -1, :]
# 获取前beam_size个最高概率
next_token_logprobs, next_tokens = torch.topk(
F.log_softmax(next_token_logits, dim=-1),
beam_size,
dim=-1
)
# 添加所有可能的扩展
for token_idx in range(beam_size):
next_token = next_tokens[0, token_idx].unsqueeze(0).unsqueeze(0)
next_score = score + next_token_logprobs[0, token_idx].item()
# 创建新的候选序列
candidate = (torch.cat([seq, next_token], dim=1), next_score)
all_candidates.append(candidate)
# 选择得分最高的beam_size个候选
ordered = sorted(all_candidates, key=lambda x: x[1], reverse=True)
sequences = ordered[:beam_size]
# 返回得分最高的序列
return sequences[0][0]
3. Top-K采样:
def top_k_sampling(model, input_ids, max_length, k=50, temperature=1.0):
"""Top-K采样 - 从概率最高的K个词元中随机选择"""
cur_ids = input_ids.clone()
for _ in range(max_length):
with torch.no_grad():
logits = model(cur_ids)
# 获取最后一个词元的logits并应用温度
next_token_logits = logits[:, -1, :] / temperature
# 过滤为概率最高的K个词元
top_k_logits, top_k_indices = torch.topk(next_token_logits, k, dim=-1)
# 创建一个新的logits分布,只保留Top-K
filtered_logits = torch.full_like(next_token_logits, float('-inf'))
filtered_logits.scatter_(1, top_k_indices, top_k_logits)
# 应用softmax获取概率分布
probs = F.softmax(filtered_logits, dim=-1)
# 采样下一个词元
next_token_id = torch.multinomial(probs, num_samples=1)
cur_ids = torch.cat([cur_ids, next_token_id], dim=-1)
# 检查是否生成了结束标记
if next_token_id.item() == model.config.eos_token_id:
break
return cur_ids
4. Top-P (Nucleus) 采样:
def top_p_sampling(model, input_ids, max_length, p=0.9, temperature=1.0):
"""Top-P (Nucleus) 采样 - 从累积概率达到P的词元中随机选择"""
cur_ids = input_ids.clone()
for _ in range(max_length):
with torch.no_grad():
logits = model(cur_ids)
# 获取最后一个词元的logits并应用温度
next_token_logits = logits[:, -1, :] / temperature
# 应用softmax获取概率分布
probs = F.softmax(next_token_logits, dim=-1)
# 按概率降序排序
sorted_probs, sorted_indices = torch.sort(probs, descending=True, dim=-1)
# 计算累积概率
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
# 删除累积概率超过p的词元
sorted_indices_to_remove = cumulative_probs > p
# 保留第一个超过阈值的词元
sorted_indices_to_remove[..., 1:] = sorted_indices_to_remove[..., :-1].clone()
sorted_indices_to_remove[..., 0] = 0
# 创建掩码
indices_to_remove = sorted_indices_to_remove.scatter(1, sorted_indices, sorted_indices_to_remove)
filtered_logits = next_token_logits.clone()
filtered_logits[indices_to_remove] = float('-inf')
# 重新计算概率分布
probs = F.softmax(filtered_logits, dim=-1)
# 采样下一个词元
next_token_id = torch.multinomial(probs, num_samples=1)
cur_ids = torch.cat([cur_ids, next_token_id], dim=-1)
# 检查是否生成了结束标记
if next_token_id.item() == model.config.eos_token_id:
break
return cur_ids
8.2 温度参数调节
温度控制生成文本的多样性和随机性:
- 低温度(<1.0):生成更确定、更保守的文本,重复性可能增加
- 高温度(>1.0):生成更多样、更创新的文本,但可能不太连贯
- 温度=1.0:不改变原始概率分布
def adjust_logits_with_temperature(logits, temperature):
"""使用温度参数调整logits"""
if temperature == 0:
# 贪婪解码(相当于无穷小的温度)
return torch.zeros_like(logits).scatter_(
1, torch.argmax(logits, dim=-1).unsqueeze(-1), 1.0
)
# 应用温度
logits = logits / temperature
# 返回概率分布
return F.softmax(logits, dim=-1)
8.3 长文本生成
对于超过上下文长度的文本生成,可以使用滑动窗口技术:
import torch
import tiktoken基本文本生成函数
def generate_text_simple(model, idx, max_new_tokens, context_size, temperature=1.0, top_k=None):
"""简单的文本生成实现"""
model.eval()
idx = idx.clone()
# 确保输入序列不超过上下文长度
if idx.size(1) > context_size:
idx = idx[:, -context_size:]
for _ in range(max_new_tokens):
# 截取上下文窗口
idx_cond = idx if idx.size(1) <= context_size else idx[:, -context_size:]
# 获取模型的logits输出
with torch.no_grad():
logits = model(idx_cond)
# 获取最后时间步的logits
logits = logits[:, -1, :] / temperature
# 可选: top-k过滤
if top_k is not None:
v, _ = torch.topk(logits, min(top_k, logits.size(-1)))
logits[logits < v[:, [-1]]] = -float('Inf')
# 应用softmax获取概率分布
probs = torch.nn.functional.softmax(logits, dim=-1)
# 采样下一个词元
idx_next = torch.multinomial(probs, num_samples=1)
# 附加到序列
idx = torch.cat((idx, idx_next), dim=1)
return idx
def generate_long_text(model, prompt, max_new_tokens, context_size, stride=None):
"""生成长文本的滑动窗口实现"""
# 如果未指定步长,默认使用上下文长度的一半
if stride is None:
stride = context_size // 2
# 初始化结果为提示文本
tokenizer = tiktoken.get_encoding("gpt2")
token_ids = torch.tensor(tokenizer.encode(prompt)).unsqueeze(0).to(next(model.parameters()).device)
all_token_ids = token_ids.clone()
# 循环生成,每次最多生成max_new_tokens个词元
tokens_to_generate = max_new_tokens
while tokens_to_generate > 0:
# 取最后context_size个词元作为当前上下文
if all_token_ids.shape[1] > context_size:
input_ids = all_token_ids[:, -context_size:]
else:
input_ids = all_token_ids
# 生成一定数量的新词元
new_tokens = min(tokens_to_generate, context_size // 4)
generated = generate_text_simple(
model=model,
idx=input_ids,
max_new_tokens=new_tokens,
context_size=context_size
)
# 添加新生成的词元
all_token_ids = torch.cat([all_token_ids, generated[:, input_ids.shape[1]:]], dim=1)
# 更新剩余需要生成的词元数
tokens_to_generate -= (generated.shape[1] - input_ids.shape[1])
return all_token_ids
8.4 辅助函数
import tiktoken
import torchdef text_to_token_ids(text, tokenizer):
encoded = tokenizer.encode(text, allowed_special={'<|endoftext|>'})
encoded_tensor = torch.tensor(encoded).unsqueeze(0) # 添加批次维度
return encoded_tensor
def token_ids_to_text(token_ids, tokenizer):
flat = token_ids.squeeze(0) # 移除批次维度
return tokenizer.decode(flat.tolist())
8.5 生成样例
start_context = "Every effort moves you"
tokenizer = tiktoken.get_encoding("gpt2")token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(start_context, tokenizer).to(device),
max_new_tokens=10,
context_size=GPT_CONFIG_124M["context_length"]
)
print("生成文本:\n", token_ids_to_text(token_ids, tokenizer))
9. 模型保存与加载
9.1 保存模型
torch.save(model.state_dict(), "model.pth")
9.2 加载模型
在新会话中
import torch
from supplementary import GPTModel
model = GPTModel(GPT_CONFIG_124M)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.load_state_dict(torch.load("model.pth", map_location=device))
model.eval()
9.3 模型量化技术
量化可以减小模型大小并加速推理:
1. 动态量化:
import torch8位整数动态量化
quantized_model = torch.quantization.quantize_dynamic(
model, {torch.nn.Linear}, dtype=torch.qint8
)
2. 静态量化:
准备静态量化
model.qconfig = torch.quantization.get_default_qconfig('fbgemm')
torch.quantization.prepare(model, inplace=True)校准模型(使用代表性数据)
with torch.no_grad():
for batch in calibration_loader:
model(batch)完成量化
torch.quantization.convert(model, inplace=True)
3. 权重量化:
def quantize_weights(model, bits=8):
"""简单的权重量化实现"""
for name, param in model.named_parameters():
if 'weight' in name:
# 计算最大和最小值
max_val = torch.max(param.data)
min_val = torch.min(param.data)
# 计算量化步长
scale = (max_val - min_val) / (2bits - 1)
# 量化
param.data = torch.round((param.data - min_val) / scale) * scale + min_val
9.4 模型导出格式
1. ONNX格式导出:
import torch
import torch.onnx创建模型的示例输入
dummy_input = torch.ones(1, 10, dtype=torch.long)导出到ONNX
torch.onnx.export(
model,
dummy_input,
"model.onnx",
export_params=True,
opset_version=11,
input_names=['input'],
output_names=['output'],
dynamic_axes={
'input': {0: 'batch_size', 1: 'sequence_length'},
'output': {0: 'batch_size', 1: 'sequence_length'}
}
)
2. TorchScript格式导出:
跟踪模式转换为TorchScript
traced_model = torch.jit.trace(model, dummy_input)
traced_model.save("model.pt")或使用脚本模式
scripted_model = torch.jit.script(model)
scripted_model.save("model_script.pt")
9.5 模型部署最佳实践
1. 构建REST API服务:
需要安装Flask: pip install flask
from flask import Flask, request, jsonify
import torch
import tiktokenapp = Flask(__name__)
model = None # 全局模型变量@app.route("/generate", methods=["POST"])
def generate():
prompt = request.json.get("prompt", "")
max_length = request.json.get("max_length", 50)
# 使用模型生成文本
tokenizer = tiktoken.get_encoding("gpt2")
input_ids = text_to_token_ids(prompt, tokenizer).to(next(model.parameters()).device)
output_ids = generate_text_simple(model, input_ids, max_length, model.config.context_length)
generated_text = token_ids_to_text(output_ids, tokenizer)
return jsonify({"generated_text": generated_text})def load_model():
global model
# 加载模型代码...
if __name__ == "__main__":
load_model()
app.run(host="0.0.0.0", port=5000)
3. 流式文本生成:
import torch
import torch.nn.functional as F
def stream_generate(model, prompt, tokenizer, max_length, callback):
"""流式文本生成,每生成一个词元就调用一次回调函数"""
device = next(model.parameters()).device
input_ids = text_to_token_ids(prompt, tokenizer).to(device)
past = None
generated = input_ids.clone()
# 一次生成一个词元并返回
for _ in range(max_length):
with torch.no_grad():
if past is None:
outputs = model(input_ids, use_cache=True)
# 注意:这里假设model支持use_cache参数和返回past_key_values
# 如果您的模型实现不同,需要相应调整
logits = outputs[0] if isinstance(outputs, tuple) else outputs
past = outputs[1] if isinstance(outputs, tuple) and len(outputs) > 1 else None
else:
# 同样,这部分需要根据您的模型实现调整
outputs = model(input_ids[:, -1:], past_key_values=past, use_cache=True)
logits = outputs[0] if isinstance(outputs, tuple) else outputs
past = outputs[1] if isinstance(outputs, tuple) and len(outputs) > 1 else None
next_token_logits = logits[:, -1, :]
# 采样下一个词元
probs = F.softmax(next_token_logits, dim=-1)
next_token = torch.multinomial(probs, num_samples=1)
# 添加到生成序列
generated = torch.cat([generated, next_token], dim=1)
input_ids = next_token
# 将最新生成的词元转换为文本
new_text = tokenizer.decode([next_token.item()])
callback(new_text)
# 检查是否生成了结束符
if next_token.item() == 50256: # GPT-2的<|endoftext|>标记ID
break
return generated
10. 常见问题
10.1 过拟合问题
症状:训练损失持续下降,验证损失开始上升,模型直接记忆训练集内容
解决方案:
- 使用更大、更多样化的训练集
- 应用正则化技术
- 调整超参数
- 采用早停策略
10.2 计算资源限制
症状:训练速度慢,内存不足错误
解决方案:
- 减小批量大小
- 减小上下文长度
- 减少模型参数量
- 使用混合精度训练
- 分布式训练
10.3 生成质量问题
症状:模型生成重复、不连贯或无意义的文本
解决方案:
- 增加训练数据量和质量
- 调整温度参数和采样策略
- 使用更先进的解码方法(beam search、nucleus sampling等)
- 微调预训练模型而非从头训练
10.4 多语言训练考量
中文等非英语语言训练需要特别注意:
1. 分词差异:
- 中文字符通常需要字符级分词而非单词级
- 混合语言文本需要特殊处理
2. 数据集选择:
- 使用高质量的中文语料库(如CLUE、中文维基百科等)
- 考虑语言特有的上下文和语法结构
3. 词汇表设计:
- 确保词汇表包含足够的中文字符和常用词组
- 考虑使用专门为中文设计的分词器(如jieba)
4. 评估方法:
- 使用适合中文的评估指标和任务
- 考虑语言特定的文化和语义因素
10.5 伦理与安全问题
LLM训练和部署需要考虑以下伦理问题:
1. 偏见与公平性:
- 训练数据可能包含社会偏见,导致模型输出有害内容
- 解决方案:数据过滤、偏见检测、人类反馈强化学习(RLHF)
2. 隐私考量:
- 训练数据可能包含个人身份信息
- 解决方案:数据匿名化、同态加密、差分隐私
3. 安全与误用:
- 模型可能被用于生成有害内容或恶意应用
- 解决方案:内容过滤、红线设置、安全框架
4. 透明度与可解释性:
- 大型模型的决策过程不透明
- 解决方案:模型文档、决策追踪、解释性研究
11. 参考资源
学习资料
1. 书籍:
- "Build a Large Language Model from Scratch" by Sebastian Raschka
- "Transformers for Natural Language Processing" by Denis Rothman
- "深度学习与自然语言处理" by 邱锡鹏
2. 课程:
- Stanford CS224N: Natural Language Processing with Deep Learning
- DeepLearning.AI: Natural Language Processing Specialization
- 李宏毅:自然语言处理课程
3. 论文:
- "Attention Is All You Need" (Transformer架构)
- "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding"
- "Language Models are Few-Shot Learners" (GPT-3)
- "Training language models to follow instructions with human feedback" (RLHF)
工具与库
1. 框架:
- PyTorch: https://pytorch.org/
- TensorFlow: https://www.tensorflow.org/
- JAX: https://github.com/google/jax
2. LLM库:
- Hugging Face Transformers: https://huggingface.co/transformers/
- DeepSpeed: https://github.com/microsoft/DeepSpeed
- FSDP: https://pytorch.org/docs/stable/fsdp.html
3. 数据集:
- The Pile: https://pile.eleuther.ai/
- C4: https://www.tensorflow.org/datasets/catalog/c4
- CommonCrawl: https://commoncrawl.org/
- 中文数据:CLUE benchmark, WuDaoCorpora
社区与论坛
1. Hugging Face社区: https://huggingface.co/
2. Stack Overflow
3. Reddit r/MachineLearning
---
本指南提供了LLM预训练的基本框架,实际应用中,您可能需要针对具体需求和可用资源进行调整。对于生产级模型,建议使用更大的训练集和更强大的计算资源。
12. 练习部分
完成以下练习,以巩固所学知识并获得实践经验。
练习1:使用预训练LLM生成文本
使用我们的训练好的模型生成新文本:
start_context = "Every effort moves you"
tokenizer = tiktoken.get_encoding("gpt2")device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(start_context, tokenizer).to(device),
max_new_tokens=10,
context_size=GPT_CONFIG_124M["context_length"]
)
print("生成文本:\n", token_ids_to_text(token_ids, tokenizer))
练习2:在新会话中加载预训练模型
打开一个新的Python会话或Jupyter笔记本,加载之前保存的模型:
import torch从本地文件导入
from supplementary import GPTModel
model = GPTModel(GPT_CONFIG_124M)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.load_state_dict(torch.load("model.pth", map_location=device))
model.eval()
练习3(可选):使用自己喜欢的文本训练LLM
尝试使用您自己选择的文本数据集进行LLM训练:
1. 选择一个适合的文本文件(如小说、文章集合等)
2. 按照本指南中的步骤处理文本数据
3. 使用相同的训练流程训练模型
4. 比较不同文本数据集对模型生成内容风格的影响
5. 尝试调整超参数(如学习率、批大小等)观察对训练效果的影响