引言
随着我们不断探索如何从大型语言模型(LLM)中挖掘商业价值,基础的 LLM 尽管在许多场景中表现出色,但其工具使用和推理能力仍有不足,难以半自主地解决实际商业问题。我们期待 OpenAI o1 及类似模型在未来的表现。本文将深入探讨在智能代理系统中实现记忆机制的相关思考。
智能代理系统的基本构成
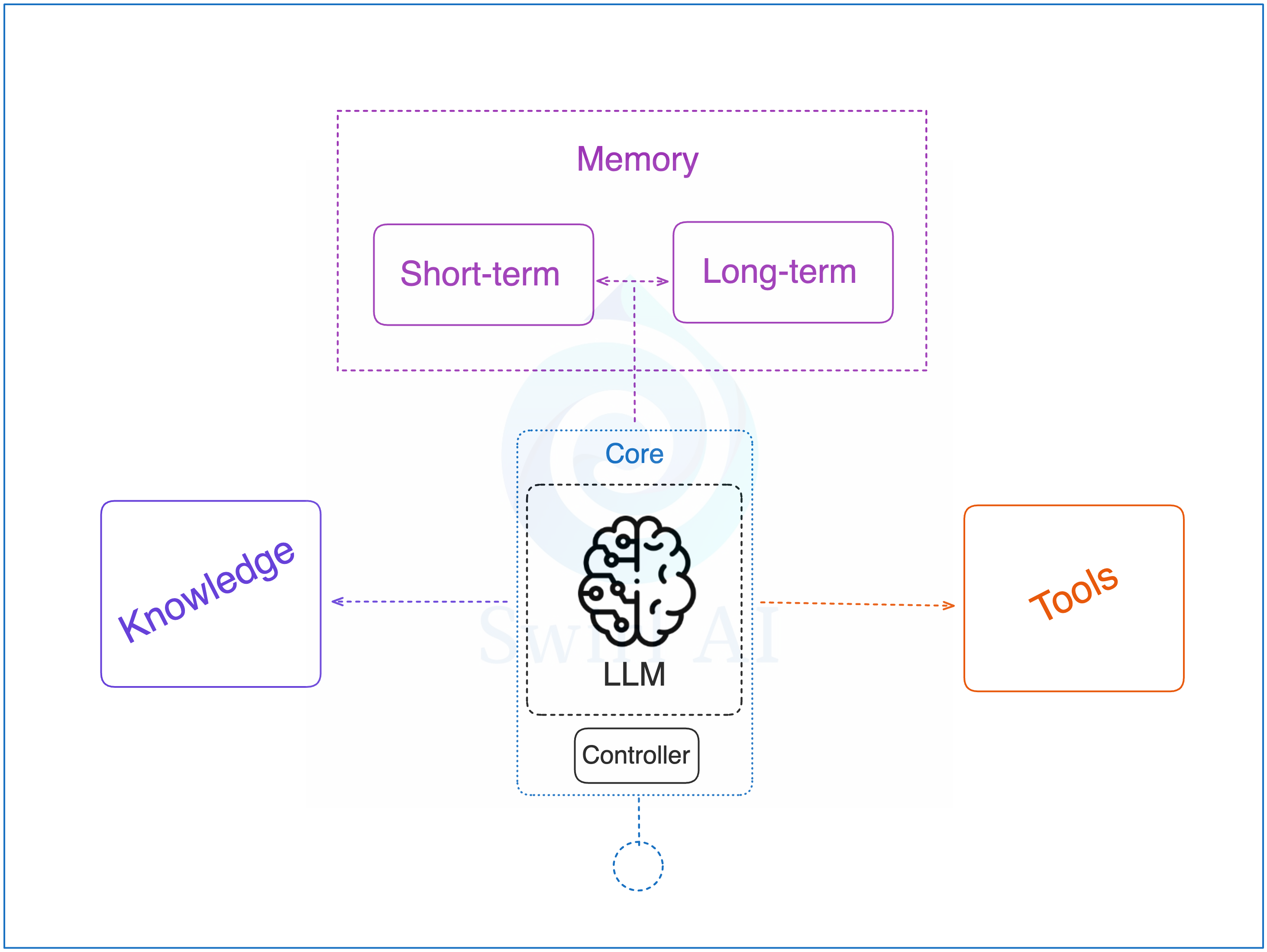
智能代理系统的核心定义包括以下几个部分:
1. 控制器应用:负责协调代理的行为,以 LLM 作为核心“大脑”,制定一系列行动步骤以实现目标。控制器利用赋予的能力,随后执行这些行动。
2. 知识库:为代理提供额外的上下文信息,类似于检索增强生成(RAG)系统中的检索模块,通常是 LLM 无法通过其他途径获取的私有上下文。
3. 长时记忆:控制器可能需要回顾短期记忆无法容纳的历史交互记录。短期记忆通常受限于 LLM 的上下文窗口大小,并通过记忆压缩技术进行补充。
4. 工具集:控制器可调用的一组功能,通常通过系统提示(System Prompt)告知 LLM 可用的工具集合,包括从计算器到互联网浏览,甚至调用另一个 LLM。
5. 指令集:控制器可使用的提示词清单(即 Prompt)。
智能代理中的记忆组件
本文将重点探讨智能代理的记忆组件。我们通常借鉴人类的记忆模式来构建和描述代理的记忆机制。据此,代理的记忆可分为两类:
- 短期记忆,有时也称为工作记忆。
- 长时记忆,进一步细分为多个子类型。
在本文开头的示意图中,短期记忆是代理的核心组成部分。它在推理循环中持续参与,帮助决定下一步行动。为了清晰起见,我们有必要单独提取记忆元素进行讨论。
{kind=link}
接下来,我们将逐一探讨各类记忆的具体特点和实现方式。
短期记忆
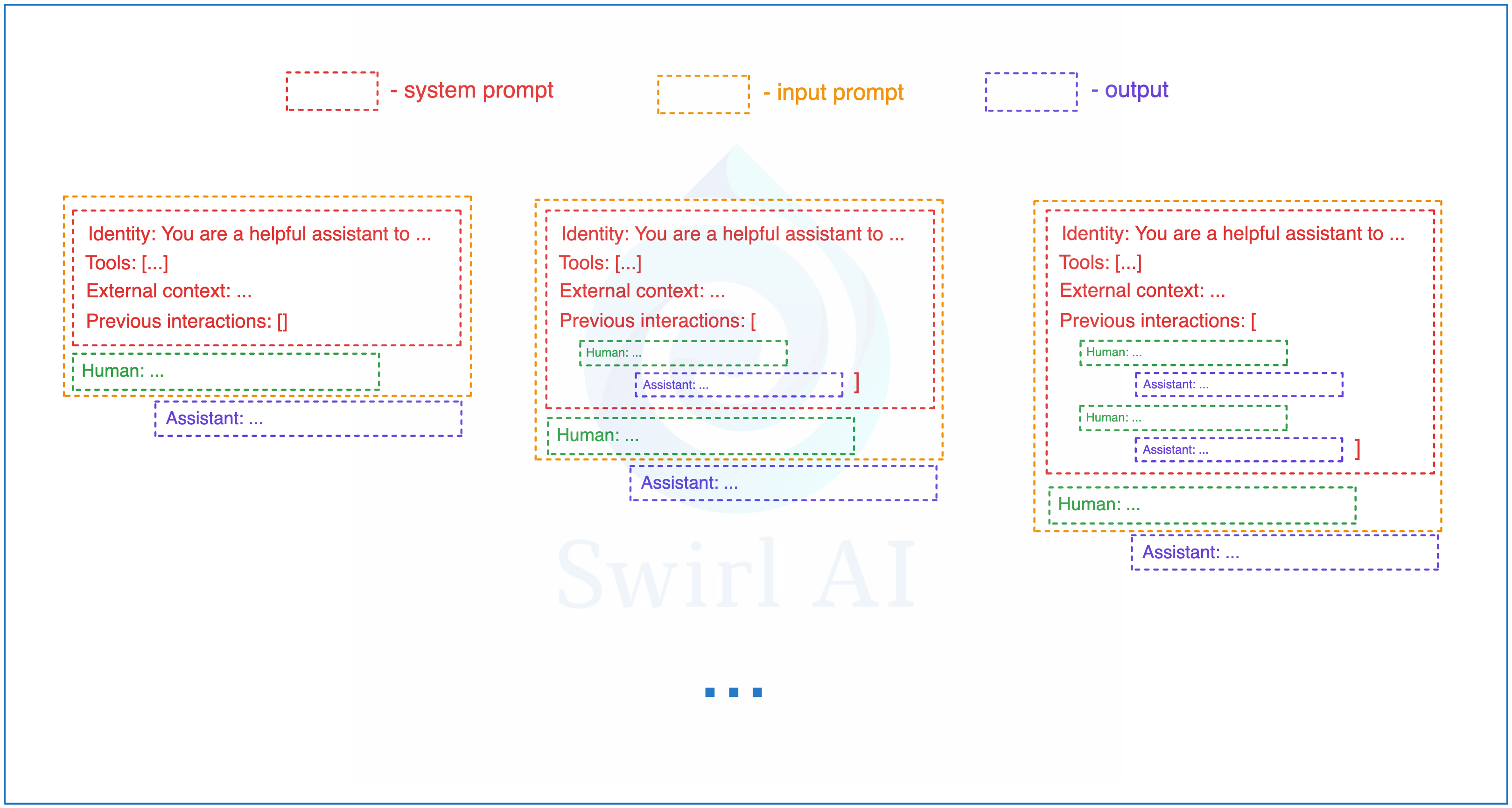
短期记忆在智能代理应用中至关重要。它通过系统提示为代理提供额外的上下文信息,帮助系统做出正确决策,完成人类交付的任务。
以简单的聊天代理为例,在与助手对话的过程中,当前交互内容会持续输入到系统提示中。这使得系统能够记住已执行的操作,并从中提取信息以规划下一步行动。需要注意的是,在智能代理系统中,助手的响应可能涉及更复杂的操作,例如外部知识查询或工具调用,而不仅仅是基础 LLM 生成的普通回答。这表明短期记忆可以通过从代理可用的各类记忆中获取信息而不断丰富,具体的实现方式将在后续章节中讨论。
{kind=link}
管理短期记忆的挑战
为什么我们不能简单地持续更新系统提示中的上下文?以下是几个主要原因:
- 上下文窗口大小受限:LLM 的处理能力有限,无法处理过多的信息。随着系统提示内容增加,可能无法完全容纳所有信息,因为 LLM 的上下文窗口有其容量限制。
- 上下文处理能力下降:即便上下文窗口很大(例如,某些模型可能支持 100 万个 token),LLM 在处理大量数据时,综合考虑所有相关上下文的能力会随着数据量增加而下降。
- 成本增加:随着每次与代理交互时系统提示的扩展,上下文会不断传递给 LLM 以生成下一步行动。这使得每次交互的成本增加。如果赋予代理更多自主性,输入 token 的数量可能迅速攀升,单次人类意图的解决可能轻易达到 50 万个输入 token。
为了解决上述问题及其他挑战,我们引入了长时记忆机制。
长时记忆
可以将代理的长时记忆视为工作记忆之外的任何信息,这些信息可以在任意时间点被调用。(一个有趣的思维实验是,设想多个相同代理的实例与不同人类交互时,能够独立访问这一记忆,形成一种“蜂巢思维”,是否会让你想起电影《Her》?)根据 CoALA 论文(链接),长时记忆可分为三类:
- 情景记忆(Episodic Memory):包含代理过去执行的交互和行动记录,类似于人类的个人经历记忆。
- 语义记忆(Semantic Memory):包含代理可用的外部信息和关于自身的知识。
- 程序记忆(Procedural Memory):包含我们为代理编入的内容,如系统提示结构和工具。
情景记忆
情景记忆包含代理过去执行的交互和行动记录。就像人类记住过去的对话和经历一样,代理也可以通过情景记忆记住与用户的交互。随着上下文的增加,并非所有信息都能保留在工作记忆中,原因包括:
- 如前所述,持续的交互可能无法完全纳入 LLM 的上下文窗口。
- 我们可能希望结束代理会话并在未来重新访问,此时交互历史必须存储在外部。
- 可以创造一种“蜂巢思维”体验,让记忆在与代理的不同交互会话中共享,甚至可能同时进行——这是一个令人兴奋的可能性!
- 交互记录越旧,相关性可能越低。尽管其中可能包含有用信息,我们仍需仔细筛选,只提取相关内容,以避免工作记忆被无关信息占用。
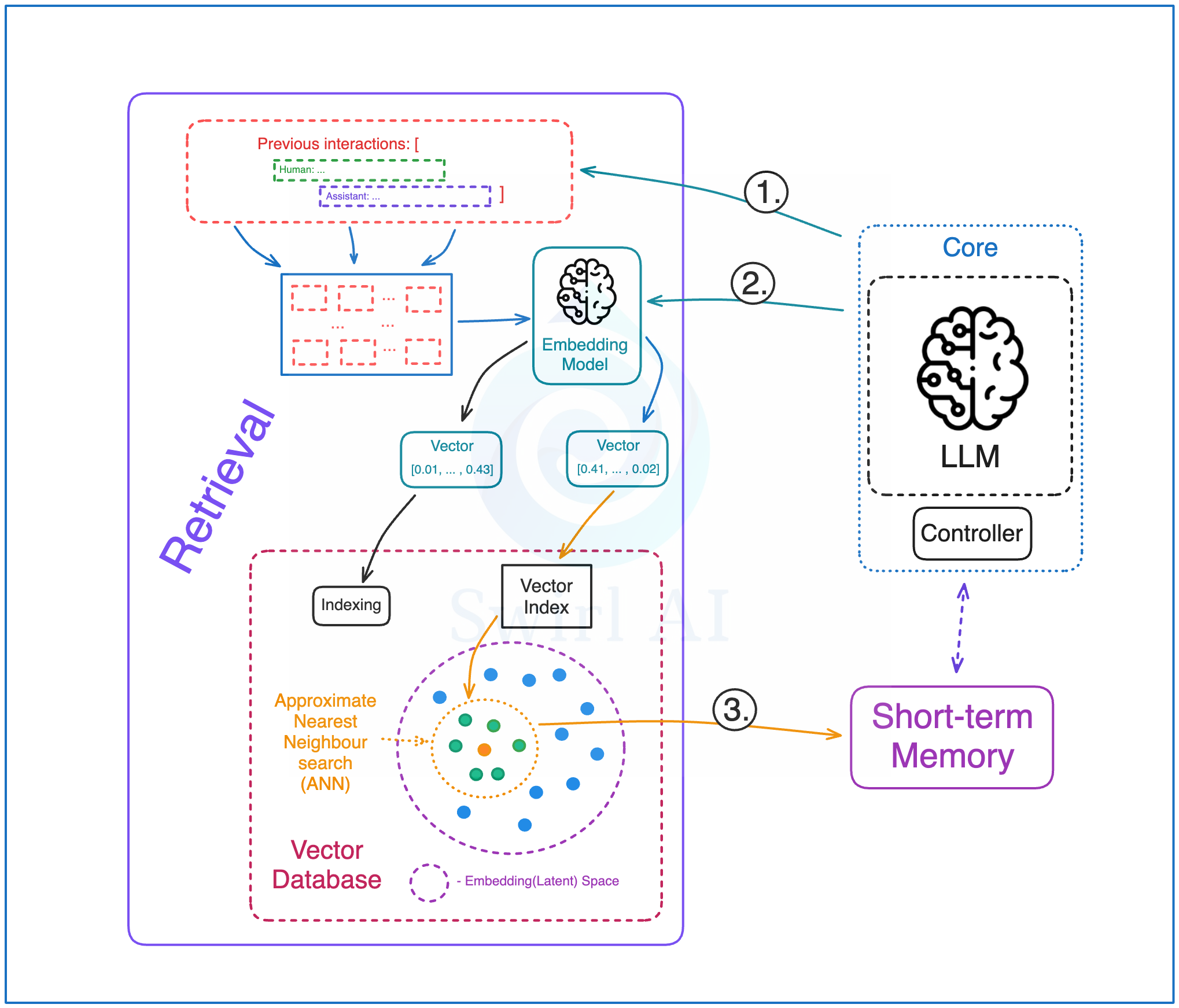
有趣的是,情景记忆的实现方式与常规的检索增强生成(RAG)系统非常相似。区别在于,我们存储用于检索的上下文来自代理系统内部,而非外部来源。
{kind=link}
实现情景记忆的步骤如下:
1. 在与代理持续交互的过程中,执行的操作被写入某种存储介质,可能支持语义检索。相似性搜索是可选的,在某些情况下,普通数据库也可能满足需求。示例图中使用了向量数据库(Vector Database),通过 LLM 持续嵌入操作信息。
2. 必要时,检索历史交互记录,以丰富短期上下文。
3. 这些额外上下文作为系统提示的一部分存储在短期(工作)记忆中,供代理规划下一步行动。
语义记忆
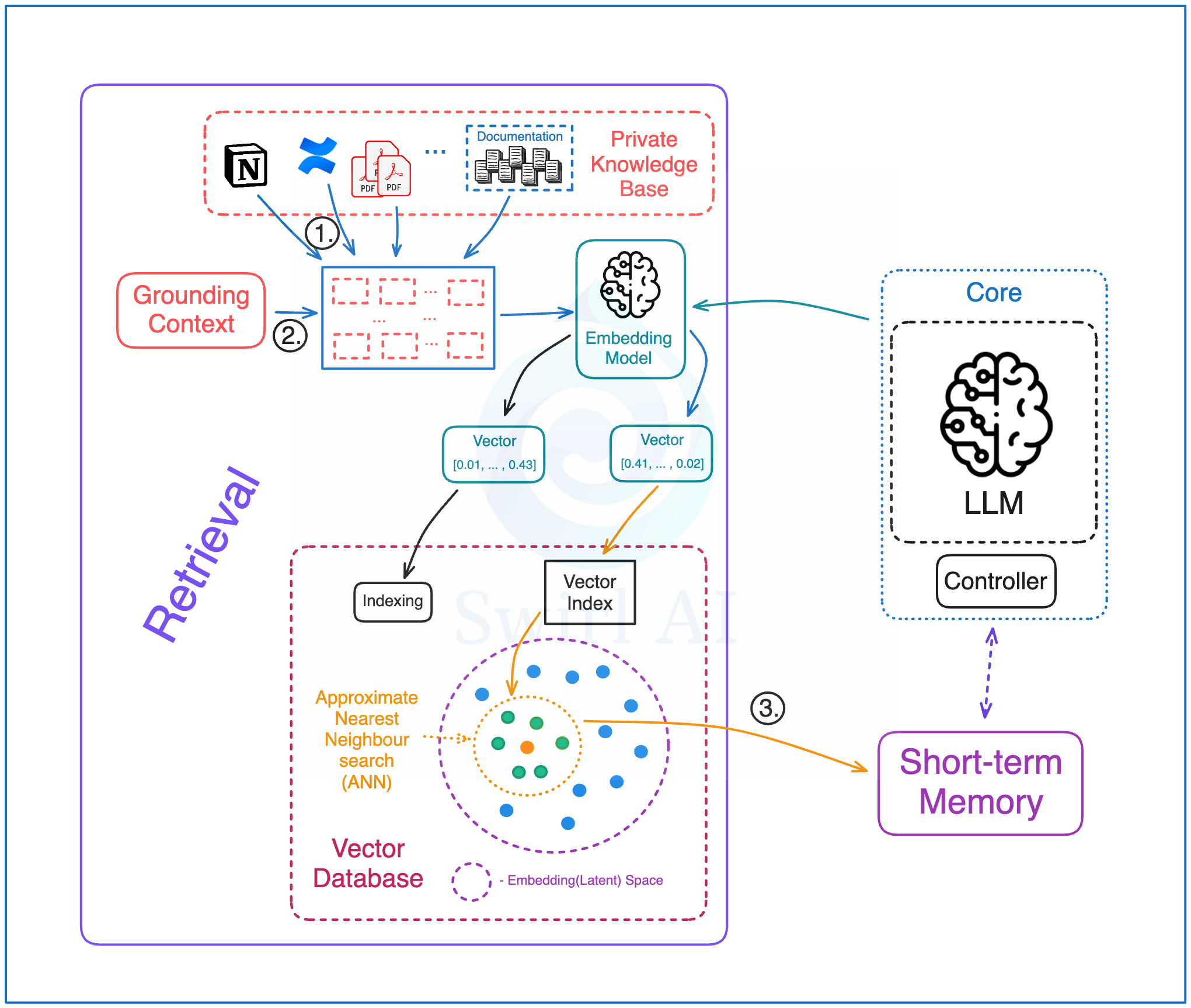
根据前述论文,语义记忆被定义为代理可用的任何外部信息,以及代理关于自身的任何知识。本文开头提到的“知识元素”就属于语义记忆的一部分。与情景记忆相比,语义记忆系统与 RAG 非常相似,包括从外部来源获取用于检索的信息。
{kind=link}
实现语义记忆的步骤如下:
1. 代理系统外部的知识存储在某种支持语义检索的存储介质中。这些信息可能是组织内部的,LLM 无法通过其他途径获取。
2. 信息也可以是“Grounding Context”(基础上下文),即存储 LLM 训练所用的大规模网络数据中的一小部分,确保 LLM 规划的行动基于特定上下文。
3. 通常,我们会通过系统提示中提供的工具,允许代理搜索这些外部信息。
语义记忆可分为多个部分,我们可以让代理通过不同工具访问特定知识领域。实现方式可能包括:
- 使用不同的数据库存储不同类型的语义记忆,并将不同工具指向特定的数据库。
- 在同一数据库中添加特定元数据,标识记忆类型,并为每个工具定义不同的预过滤查询,在应用搜索之前筛选特定上下文。
值得一提的是,系统提示中提供的代理身份信息也被视为语义记忆的一部分。这类信息通常在代理初始化时检索,用于对齐(Alignment)。
程序记忆
程序记忆被定义为我们为代理编入的任何内容,包括:
- 系统提示的结构。
- 提供给代理的工具。
- 对代理设置的防护栏(Guardrails)。
- 当前代理尚未完全自主,程序记忆还包括代理系统的拓扑结构。
总结与展望
在智能代理系统中,记忆是实现基于相关上下文进行规划的核心工具之一。在构建代理架构时,需要综合考虑记忆机制的诸多方面。
不同的代理应用开发框架以不同方式实现记忆功能,建议深入研究其具体实现方式,以避免潜在问题。