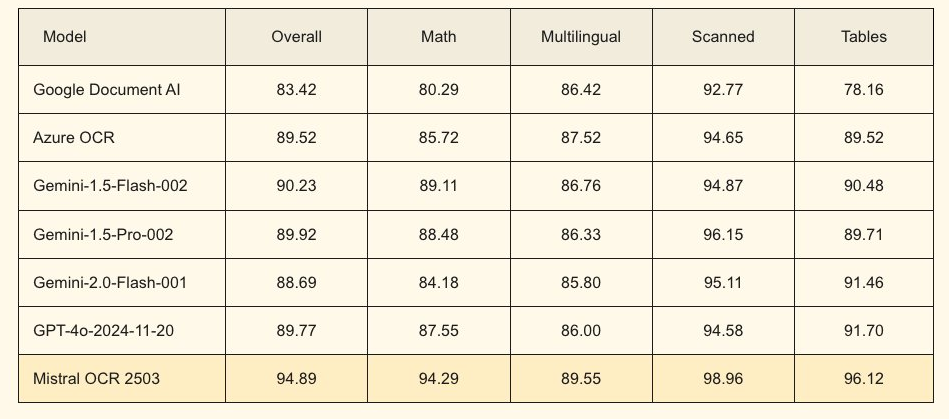
>近期,法国的AI初创公司Mistral AI发布了号称世界上最好用的OCR API,能够精确提取各种复杂文档,支持复杂PDF、图像、表格、数学公式、多语言文档等多种格式。官方测试显示,它的准确率为94.89%,处理速度更是达到了每分钟2000页。
这家AI初创公司的核心团队集结了DeepMind、Meta AI和FAIR三大顶尖实验室的骨干:
- Arthur Mensch(前DeepMind研究员):主导算法架构设计
- Timothée Lacroix(Meta AI前工程师):负责视觉模型优化
- Guillaume Lample(FAIR前成员):专攻多语言处理系统
他们把大语言模型的Transformer架构经验应用于OCR技术上,并采用了Dual-Stream Vision Transformer模型,可以同时处理文本和视觉信息。这种架构让系统能够分析文档结构,并通过自注意力机制找到不同内容之间的联系。
在PDF文档解析准确率测试中,Mistral OCR的表现优于Google Document AI 和Azure OCR。
在实际使用中,Mistral OCR有以下几个亮点:
1. 多模态认知引擎:它不仅能识别包含中日韩等多种语言的文档,还能准确识别数学公式(LaTeX格式输出)和流程图(自动生成SVG矢量图)。使用的动态布局分析算法,能够快速还原PDF的原始排版。

2. 高效处理能力:Mistral的OCR技术能够高效处理文档,性能表现出色。
3. 智能纠错系统:对于模糊的古籍、低分辨率的碑文等特殊文档,Mistral OCR的字符识别准确率较高。

Mistral的CTO Timothée Lacroix表示:「这不只是文字识别,更是文档认知的革命」。他还提到,他们的核心技术是「视觉-语言联合嵌入空间」,通过预训练让模型理解PDF中每个像素的含义(是文字、公式还是图片)。通过这种方式,能够将复杂的学术论文转换为Markdown格式,并且保留原始排版。
与RAG系统的结合也显示了他们的战略目标。开发者现在可以通过API直接获取结构化的JSON数据,包括:
- 文本块和它们的位置信息
- 数学公式的解析树
- 图片的CLIP嵌入向量
这样,企业在构建知识库时,通过集成Mistral API便可以实现多模态检索。据报道,欧洲一家出版社已经使用这项技术,将旧书籍数字化,大幅提高了效率。
从技术发展的角度来看,这可能是文档处理领域的一次重要突破。IBM于1959年推出第一台商用OCR设备时,需要特定的字体和严格的排版。但现在,AI驱动的多模态OCR已经实现将各种文档转化为可计算的数据。就像Mistral官网上的宣言:「我们正在重建巴别塔,但这次是用0和1。」