本文为您提供关于通过重排序(reranking)提升检索系统效果的实用见解。我们将详细探讨以下关键问题:何时需要引入重排序模型?是选择预训练模型、微调现有模型,还是从零构建新模型?
检索过程是RAG(检索增强生成)或智能工作流的核心。聊天机器人和问答系统依赖检索器在对话中为每次回复获取相关上下文。大多数检索器默认采用向量搜索(vector search)。直觉上,改进嵌入表示(embedding representation)应能带来更好的搜索结果。
{kind=link}
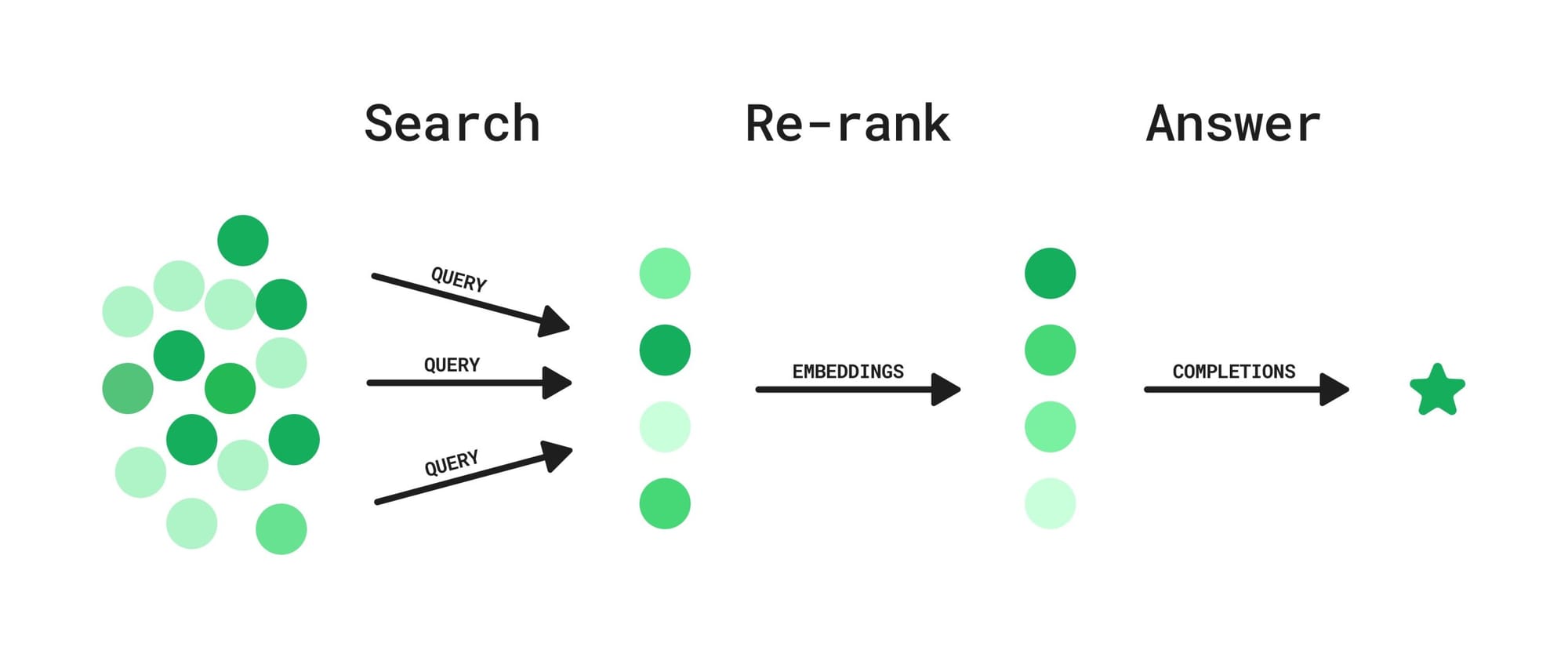
在本系列博客中,我们将从检索过程的最后一个环节——重排序开始,逐层展开讨论。
重排序在检索中的角色
要理解重排序模型的重要性,首先需要明确嵌入模型(embedding model)与重排序模型(ranking model)的区别。一个常见问题是:既然优化嵌入模型可以提升搜索结果,为什么不专注于改进或微调嵌入模型,或者尝试全新的模型?
嵌入模型与重排序模型的区别
嵌入模型和重排序模型的根本区别在于:
- 嵌入模型:将任意数据点转化为特定向量空间中的向量表示(即将数据转换为数学向量,以便进行计算和比较),旨在让语义相似的文档或查询在向量空间中彼此靠近。向量搜索时,这些相似的文档会被检索出来作为查询的潜在结果。
- 重排序模型:根据与查询的相关性,对检索到的数据点(或文档)进行重新排序,确保最相关的结果排在前面。此外,在需要整合多个独立搜索结果集(例如向量搜索和全文搜索的结果)时,重排序也非常有用。
!重排序示意图
来源:https://unfoldai.com/rag-rerankers/
{kind=link}
为什么不直接用重排序模型进行搜索?
重排序通常是一个成本更高的操作,远超向量搜索。您无法对整个数据库逐行运行重排序模型。与嵌入模型不同,重排序模型无法提前离线生成文档的向量表示,因为它需要同时处理查询和文档来计算排名。
以下是嵌入模型与重排序模型的更多比较:
| 特性 | 嵌入模型 | 重排序模型 |
|---------------------|---------------------------------------|-----------------------------------------|
| 主要目标 | 生成捕捉语义的向量表示 | 计算查询与候选项对的相关性得分 |
| 输入 | 单一项(查询或文档/数据点) | 一对(查询和候选项) |
| 输出 | 稠密数值向量(嵌入) | 每对输入的相关性得分 |
| 典型用途 | 初始候选检索、语义搜索、聚类 | 优化/重新排序检索到的顶部候选 |
| 流程阶段 | 早期阶段(候选生成/检索) | 后期阶段(优化/重新排序) |
| 计算成本 | 每项成本通常较低(嵌入可预计算) | 每对成本通常较高(需评估交互) |
| 可扩展性 | 高(通过向量搜索适用于大数据集) | 较低(仅应用于少量候选) |
| 架构 | 独立编码各项目 | 同时处理查询和项目以捕捉交互 |
| 质量与速度权衡 | 针对大数据集优化速度和广度召回 | 针对小数据集优化精度/质量 |
| 示例 | 将文档编码为向量存入向量数据库 | 根据相关性得分对前50个结果重新排序 |
> 注:对于交叉编码器(cross-encoder),每次单独计算查询-文档对的相似度;而基于晚期交互(late interaction)的模型(如ColBERT)则批量计算文档表示,并通过与查询表示的MaxSim操作进行重排序。
微调的利弊权衡
嵌入模型的微调
升级嵌入模型——无论是切换到新模型还是在您的数据上微调基础模型——可以显著提升基础检索性能。然而,微调嵌入模型会改变整个嵌入空间,这可能会损害模型的整体表现。此外,这在操作上具有破坏性,因为您需要重新生成所有嵌入。对于许多只支持每条记录一个向量字段的向量数据库而言,这意味着需要管理多个不同的表来进行实验。更多信息可参考大语言模型(LLM)中的“灾难性遗忘”(catastrophic forgetting)现象,即模型在学习新任务后可能会遗忘旧任务(类似学习新知识时忘记旧知识)。
重排序模型的微调
相比之下,由于重排序模型在检索流程的后期阶段使用,您可以方便地切换模型、训练新模型,或者完全移除它们,无需重新摄入数据或更新查询/源嵌入器。这种方式通常是提升检索流程质量的更简单途径。
从零开始训练重排序模型
本文将深入探讨重排序模型,介绍如何在短时间内使用私有数据基于基础大语言模型(而非基础重排序模型)进行训练,从而显著提升检索性能。当然,您也可以从已训练的重排序模型开始,在自己的数据集上进行微调。
数据集
本文使用的数据集是 gooaq,包括超过300万(3M)对查询和答案数据。具体使用方式如下:
- 前200万条数据用于训练。
- 接下来的10万条数据被导入LanceDB。
- 从这10万条中抽取2000个样本用于评估命中率(hit rate)。
基准模型
{kind=link}
使用的基准模型:
在训练交叉编码器(cross-encoder)和ColBERT模型时,我们使用了以下两个基础模型:
1. MiniLM-v6:一个非常小的基础模型,仅有约600万参数。
2. ModernBert-base:一个相对较大的基础模型,拥有约1.5亿参数(但仍远小于最先进的重排序模型)。
通过这两个模型,我们可以分析模型规模(及延迟)与质量提升之间的权衡,例如通过比较不同模型在相同数据集上的表现。
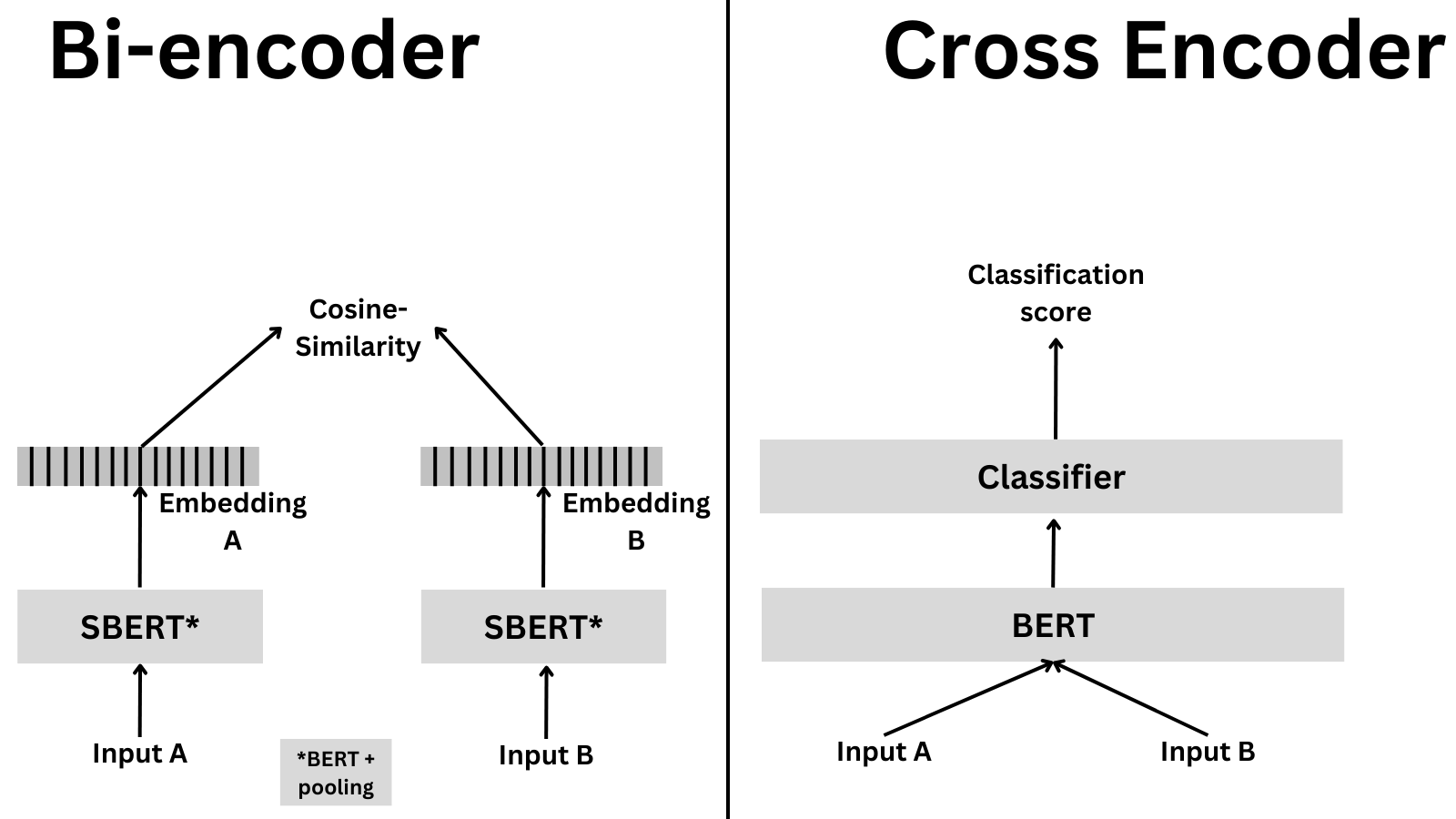
训练交叉编码器
交叉编码器是一种用于比较文本对的神经网络架构。与分别编码文本的双编码器(bi-encoder)不同,交叉编码器同时处理两段文本,通过交叉注意力机制实现更精确的比较(就像图书管理员同时阅读两本书以判断其相关性)。
{kind=link}
- 联合处理:查询和文档/段落拼接后一起输入到Transformer模型,如BERT或RoBERTa。
- 交叉注意力:Transformer对整个拼接文本应用自注意力机制,让每个token可以关注两段文本中的所有其他token。
数据集预处理:
- 将数据集的训练子集格式化为适合交叉编码器模型训练的形式,使用二元交叉熵损失(BinaryCrossEntropy loss)。为此,数据集需格式化为:查询/锚点,正例,标签。
- 评估时,评估集被构建为包含多个负例的格式,如锚点,正例,负例1,负例2……。
最后,为了从数据集中创建训练和测试划分,我们会从数据集中提取“硬负例”(hard negatives)。硬负例是指与查询正例答案语义相似的负例。我们使用独立的嵌入模型来找到与查询(也称为锚点)语义相近的负例。
关于训练方法的深入内容,请参阅sentence-transformer的交叉编码器训练指南。
简言之,训练流程如下:
{kind=link}
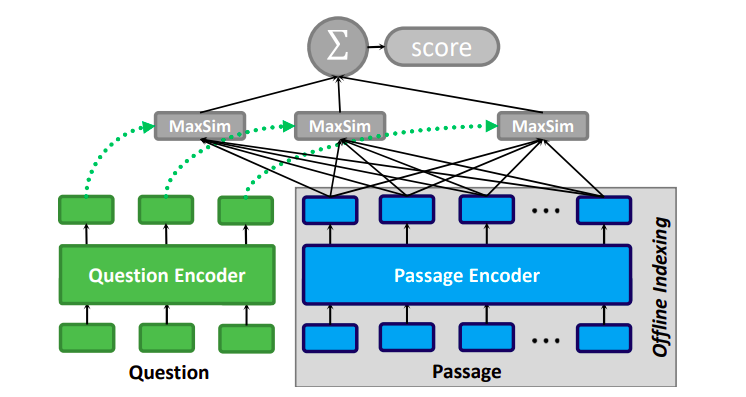
训练ColBERT重排序模型
{kind=link}
对于训练ColBERT这样的晚期交互模型,我们使用sentence-transformer的库Pylate,该库实现了晚期交互工具。训练脚本的唯一区别在于:
- 对比损失(Contrastive loss)用于训练晚期交互模型,具体步骤是:
- Token嵌入:提取并归一化查询和文档的token级表示。
- MaxSim评分:对每个查询token,计算与任意文档token的最大相似度,然后求和。
- 标签分配:生成标签以标识哪些文档与每个查询匹配。我们会得到两个分数,一个对应负例,一个对应正例,从而转化为分类问题。
- 交叉熵损失:在相似度分数和标签之间使用交叉熵损失。
- ColbertTripletEvaluator:与交叉编码器相似,但使用晚期交互多向量嵌入。
使用PyLate Python包来微调晚期交互ColBERT模型。
从零开始训练和微调模型使用相同的流程。
在LanceDB中使用微调后的重排序模型
LanceDB与所有流行的重排序模型均有集成,切换到新模型只需更改一个参数。
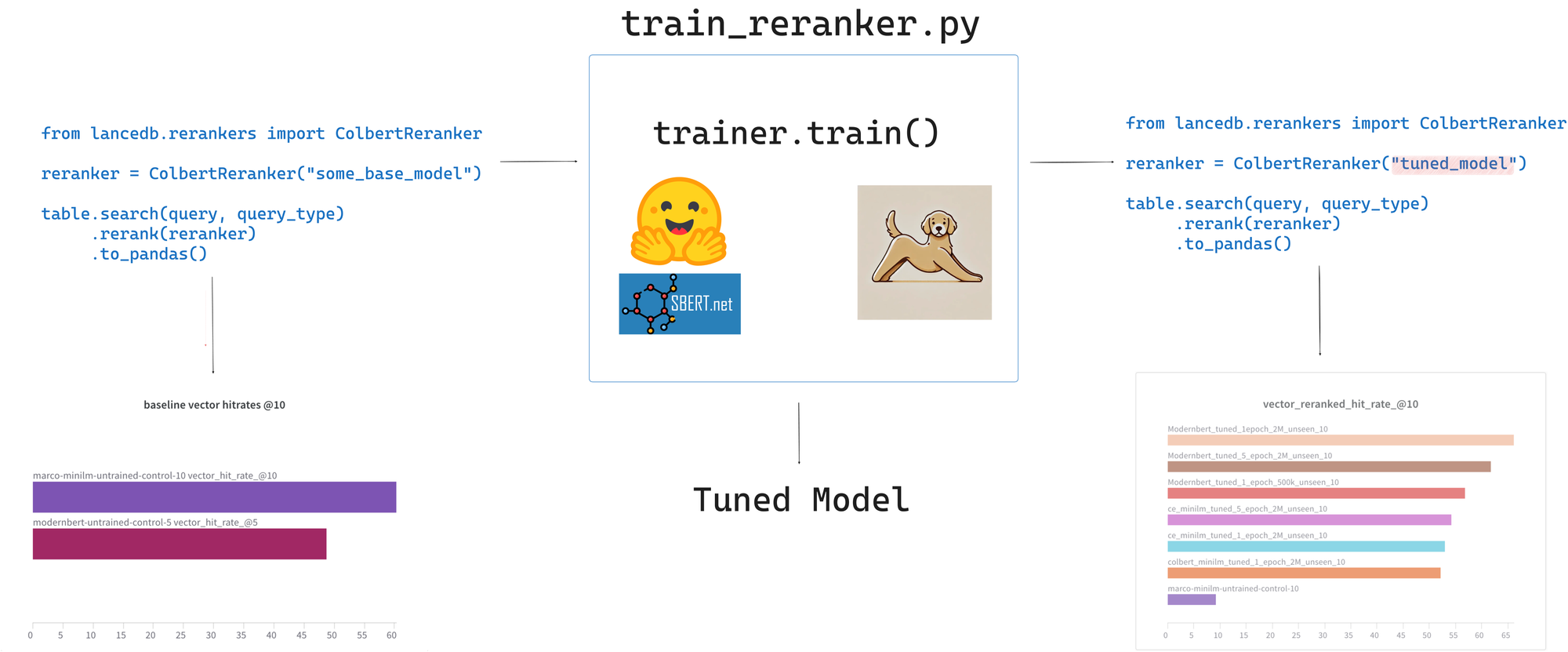{kind=link}
以下是如何在LanceDB中使用ColBERT模型作为重排序器,并采用混合搜索查询类型:
from lancedb.rerankers import ColbertRerankerreranker = ColbertReranker("my_trained_model/") # 本地或Hugging Face Hub
rs = tbl.search(query_type="hybrid") \
.vector([...]) \
.text(query) \
.rerank(reranker) \
.to_pandas()
LanceDB集成了许多其他重排序器,包括Cohere、交叉编码器和AnswerdotaiRerankers等。Answerdotai重排序器集成支持多种类型的重排序架构。以下是如何通过Answerdotai集成使用ColbertReranker的示例:
from lancedb.rerankers import AnswerdotaiRerankersreranker = ColbertReranker(
"colbert", # 模型类型
"trained_colbert_model/" # 本地或Hugging Face Hub
)
rs = tbl.search(query_type="hybrid") \
.vector([...]) \
.text(query) \
.rerank(reranker) \
.to_pandas()
性能对比
实验仪表板包括模型架构、基础模型及top_k组合的所有结果。以下是一些总结数据,便于比较性能并评估速度与精度的权衡。
对照实验:未使用重排序的基准运行,与上文提到的相同。
{kind=link}
基础模型重排序性能:
结果显示,未经重排序模型训练的基础模型输出结果较差。
本实验中所有重排序结果以4倍的量进行过采样(overfetching),然后重排序,最后选择top_k结果。这样可以让重排序模型发挥作用。如果不进行过采样,性能不会有差异。
{kind=link}
与专用重排序模型的对比:
经过大量优化技巧并在庞大数据集上训练的专用重排序模型显著提升了搜索性能。
{kind=link}
从零开始训练模型
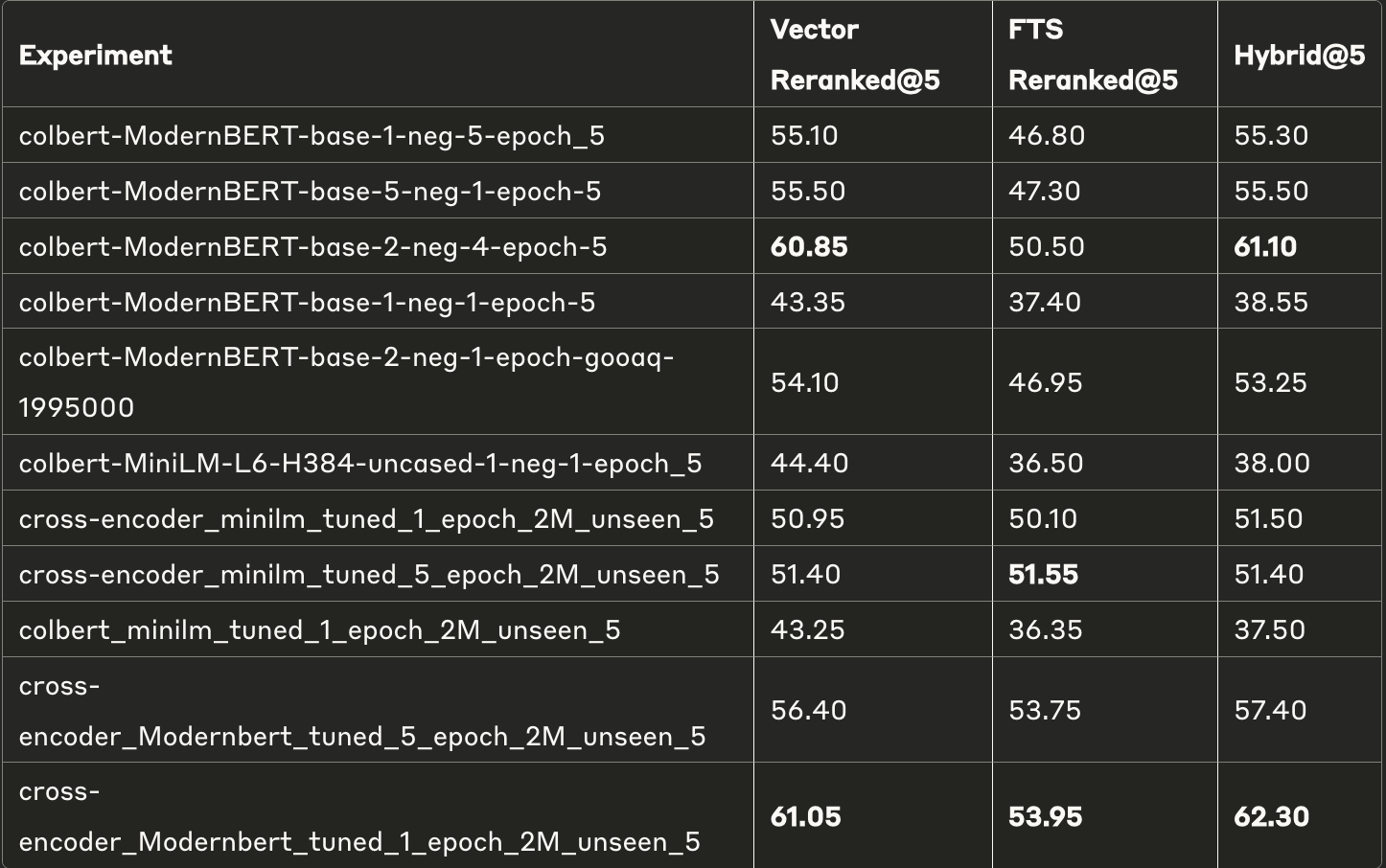
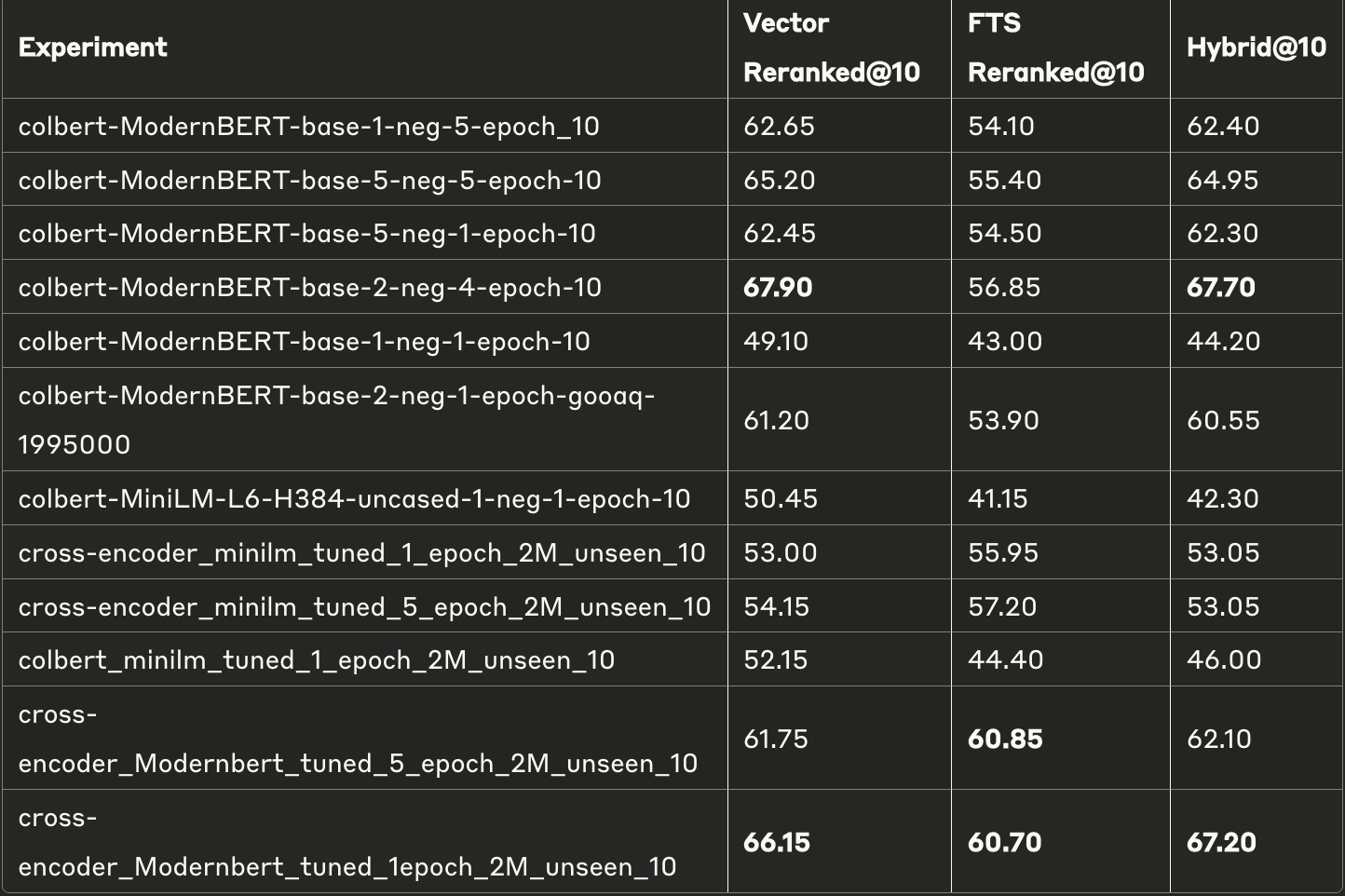
除了表格中第一行外,所有模型均是从零开始训练的。命名规则是{重排序架构}{基础架构}{负例数量}_{训练轮数}。
{kind=link}
{kind=link}
关键发现
1. 重排序效果评估:
- 向量搜索性能经重排序显著提升,在前5名时提升高达12.3% ,在前10名时提升6.6% 。
- 全文搜索(FTS)结果在重排序后的提升不同,部分模型提升高达20.65% ,而其他模型性能有所下降。
2. 模型架构比较:
- 基于ModernBERT的模型性能最佳,尤其是2负例4轮训练的变体,在前10名时接近基准性能(-0.51%)。
- 基于MiniLM的模型相较于ModernBERT模型性能较差,这在意料之中,因为这些模型非常小。
- 但它们显著提升了基础性能——这表明重排序是一个容易实现的优化手段。
- 交叉编码器模型在全文搜索重排序中表现优异,优于基于ColBERT的方法。
3. 训练参数效应:
- 增加负例样本通常提升各种架构的模型性能。
- 2负例4轮训练的组合在性能与训练成本之间达到最佳平衡。
- 大多数模型训练轮数超过2轮后收益递减,这可能反映了过拟合或灾难性遗忘的问题。
> 注意:本文并非“如何训练最佳模型”的入门指南。通过标准的随机/网格搜索进行微调,相同模型和配置应能展现更好的性能。这超出了本文范围,本文主要讨论重排序的原理及其是否适合您的用例。
4. 最优非微调模型:
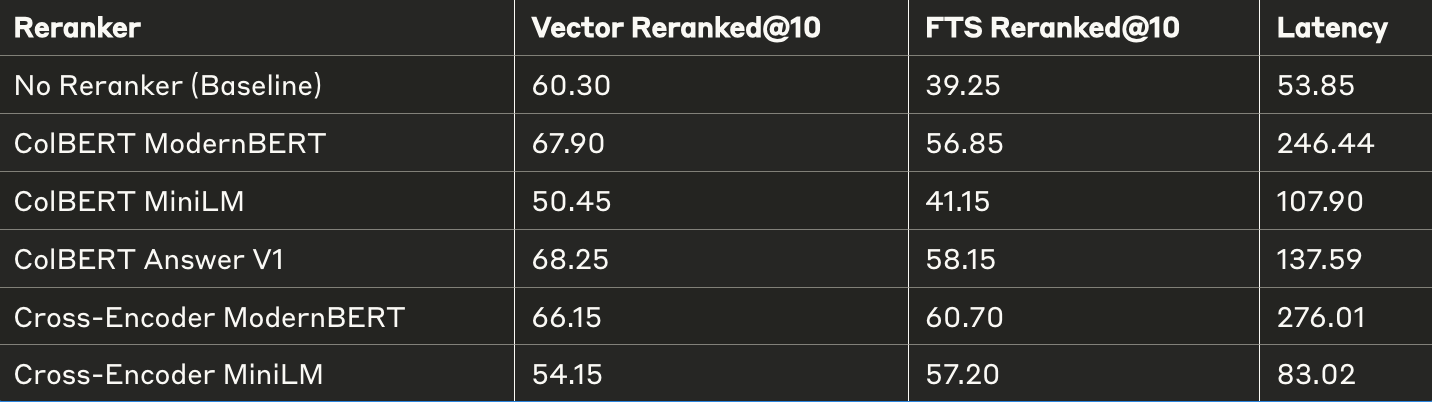
- 前5名:cross-encoder_Modernbert_tuned_1_epoch_2M_unseen_5(向量:61.05,全文:53.95,混合:62.30)
- 前10名:cross-encoder_Modernbert_tuned_1epoch_2M_unseen_10(向量:66.15,全文:60.70,混合:67.20)
可见,仅在几百万数据点(包括数据增强)上训练的模型,其性能即可接近在更大语料库上精心训练的专用重排序模型。
5. 混合搜索的多样性:
- 混合搜索性能因各组件搜索的个体结果质量而异。
- 当某一组件结果性能较差时,混合搜索甚至可能不如向量搜索。
- 但当全文搜索和向量搜索的结果集都表现出色时,混合搜索的表现优于任何单一搜索类型。混合搜索的灵活性使其成为多种搜索场景下的最佳选择。
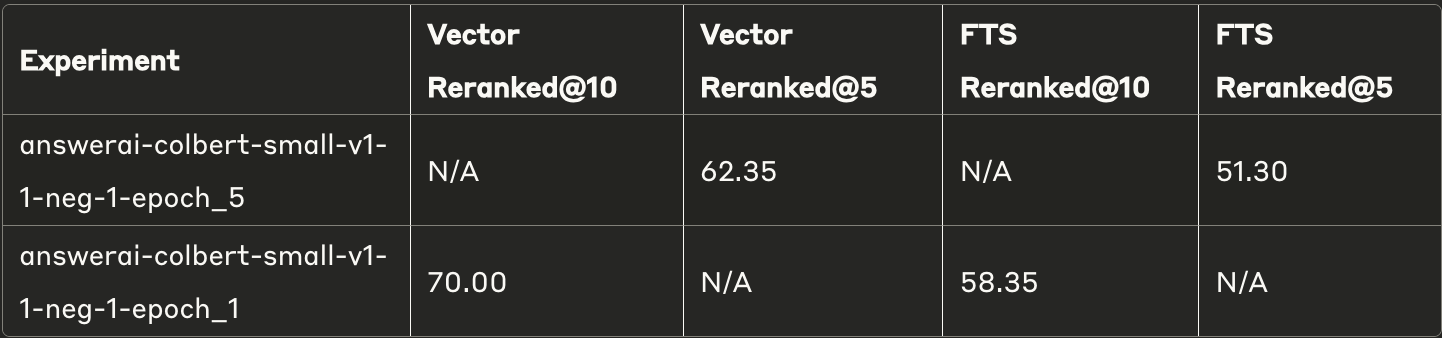
微调现有重排序模型
当您拥有足够的高质量数据时,也可以通过微调现有重排序模型来提升性能。微调后的answerai-colbert模型在所有配置中性能始终优于其他模型,具体数据如下:
专用重排序模型的基准表现:
!基准表现
{kind=link}
微调后表现:
{kind=link}
是从零训练还是微调重排序模型?
这取决于数据集的规模和质量。从零训练与微调的经验法则同样适用于重排序模型。
需从零训练的情况:
当您选择的基准模型没有现成的重排序模型时。ModernBERT本身并非重排序模型,我们将其作为基础,构建交叉编码器和ColBERT架构的重排序模型,因此需要从零开始训练。
需微调的情况:
当您选择的架构已有重排序模型时,但您怀疑自己的数据集可能过于专业化,或者数据分布与训练这些重排序模型的原始数据集已发生偏移。
应记住的一般规则是,微调现有架构的收敛速度更快。此外,应注意大语言模型中的“灾难性遗忘”问题,即模型在学习新任务后,可能会遗忘或显著降低对先前学习任务的表现。
权衡考量
根据“没有免费午餐定理”,没有一种优化算法能普遍适用于所有问题,重排序检索结果时也涉及多种平衡。
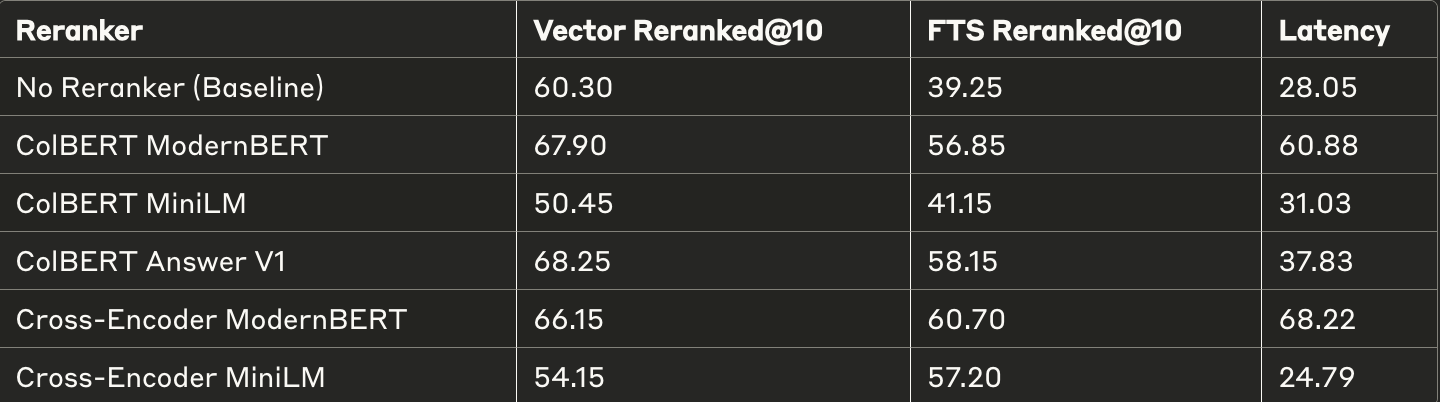
延迟与性能的平衡:
以下是性能改进数据(来自上表):
!性能改进
{kind=link}
下图显示不同top_k下的延迟对比:
!延迟对比
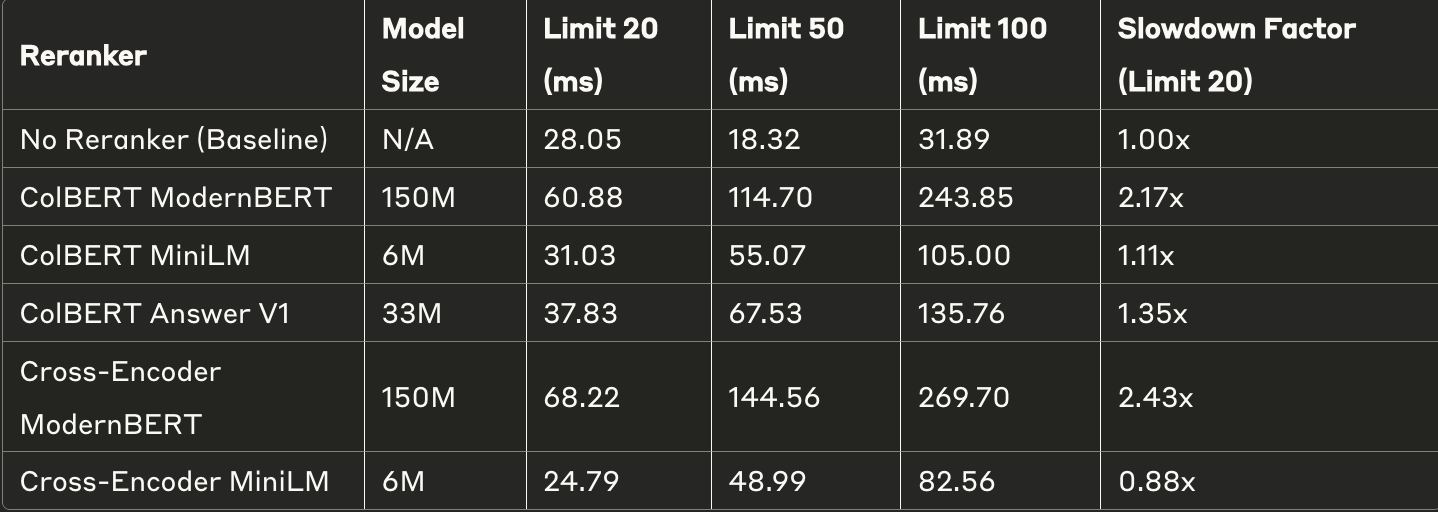{kind=link}
这些数据由L4 GPU(性能与T4相当)计算,选用这类GPU的原因是它们价格低廉且易于获取。
> 注意:通过多种技术可以进一步优化这些数据,从而显著提升性能。一些简单的优化方法包括:
> - 应用torch.compile。
> - 量化处理(Quantization)。
> - 使用更强大的GPU。
谁适用重排序模型?谁不适用?
- 如预期,重排序会增加查询时间的延迟。
- 依据具体用例,这种延迟可能较为显著。
- 当您的目标是始终保持延迟低于100毫秒时,需谨慎评估重排序是否值得付出延迟代价。
- 对于延迟增加不超过约50毫秒不会造成重大影响的通用场景,则应优先考虑重排序,而非更具破坏性的技术,如微调或切换到新的嵌入模型。
当您的用例对延迟没有严格限制时,可以继续使用CPU,因为即使不加速,重排序模型也仅增加几百毫秒的延迟。
{kind=link}
API重排序模型:
本文讨论的是开源模型,但您也可以选择API重排序模型。最优方式是通过手动评估其准确性和速度来决定是否使用。基于API的方法有多个未知因素,无法在本实验中直接比较:
1. 延迟波动较大。
2. 模型架构不明。
3. 一般无法在自己的数据上训练或微调。
在部分实验中,基于API的重排序模型表现出极高的准确性,但延迟不稳定。更多详情请参阅我们的文档中的示例。
可复现性
- 复现本文实验的代码和说明在此:https://github.com/lancedb/research/tree/main/reranking?ref=blog.lancedb.com。
- 所有训练产出物在此:https://huggingface.co/ayushexel?ref=blog.lancedb.com。
结语:如果您对提升检索系统性能感兴趣,建议尝试使用本文介绍的重排序模型,并根据您的具体需求进行微调或从零训练,找到最适合您的解决方案。