在文本生成、机器翻译等任务中,Transformer作为一种神经网络架构,已成为主流选择。但在Transformer之前,RNN和LSTM是处理序列数据的主要模型。然而,这些模型在处理长距离依赖关系时存在局限性,因为它们的序列处理机制既难以并行化运算,又捕捉不到远端上下文关联。
Transformer通过引入注意力机制有效解决了这个问题,该机制能够动态评估输入各部分的重要性,无论目标位置远近,都能准确捕捉关键信息。
{kind=link}
什么是注意力机制?为何不可或缺?
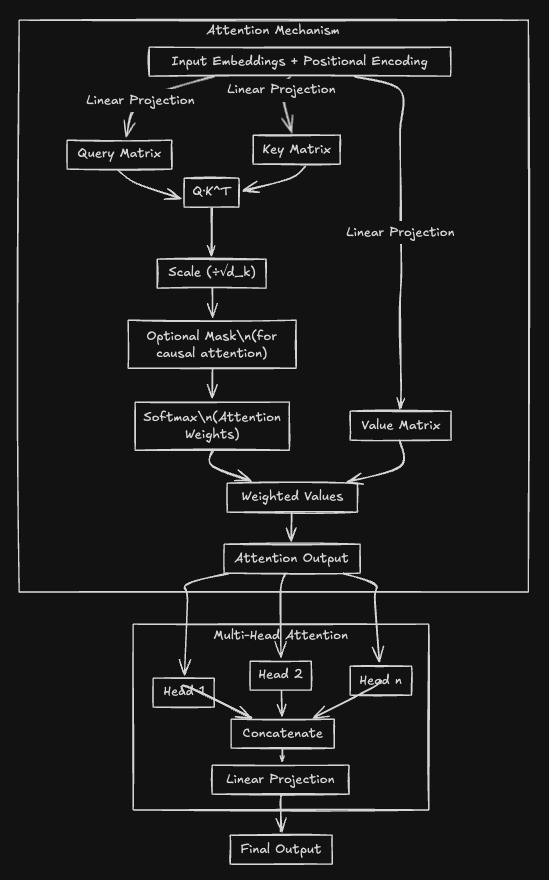
注意力机制本质上是一种根据相关度加权整合信息的技术。它通过计算查询向量(Query)与键向量(Key)的相关性权重,动态调整各输入值的贡献比重。
运作原理详解
在处理语句时,每个词语(token)都会生成三个核心向量:
- 查询向量(Query):当前词的信息需求
- 键向量(Key):上下文中的位置标识
- 值向量(Value):实际携带的语义信息
当某个词语提出查询请求时,系统会将查询向量与其他词语的键向量进行匹配度计算。基于匹配结果生成注意力权重图谱,最终将这些权重与对应的值向量进行加权融合。
接下来,我们将详细探讨注意力机制的具体运作原理。
三向量生成方法
这三个核心向量源自输入嵌入(input embeddings)的线性变换:
1. 输入词语首先转化为嵌入向量
2. 通过三组独立权重矩阵(Wq、Wk、Wv)进行线性投影
3. 最终得到定制化的查询、键、值向量
在进行注意力评分时,首先计算查询和键向量的点积。为防止梯度消失,将结果除以键向量维度的平方根进行缩放。之后经过softmax函数归一化处理获得概率分布权重,最终通过加权求和得到注意力输出。
通过上述步骤,我们可以得到注意力机制的数学表示。
数学公式详解
注意力机制的核心公式如下:
Attention(Q,K,V)=softmax(Q·K^T/√d_k)·V
符号解析:
- Q(查询矩阵):信息需求的数学表征
- K(键矩阵):上下文位置的映射关系
- V(值矩阵):实际语义的价值载体
计算四部曲:
1. 点积运算:构建词语关联度矩阵
2. 维度缩放:避免梯度弥散风险
3. 概率归一:转化为注意力权重
4. 价值整合:生成最终特征表示
这个过程称为自注意力机制,允许序列中的每个位置与其他所有位置进行交互。
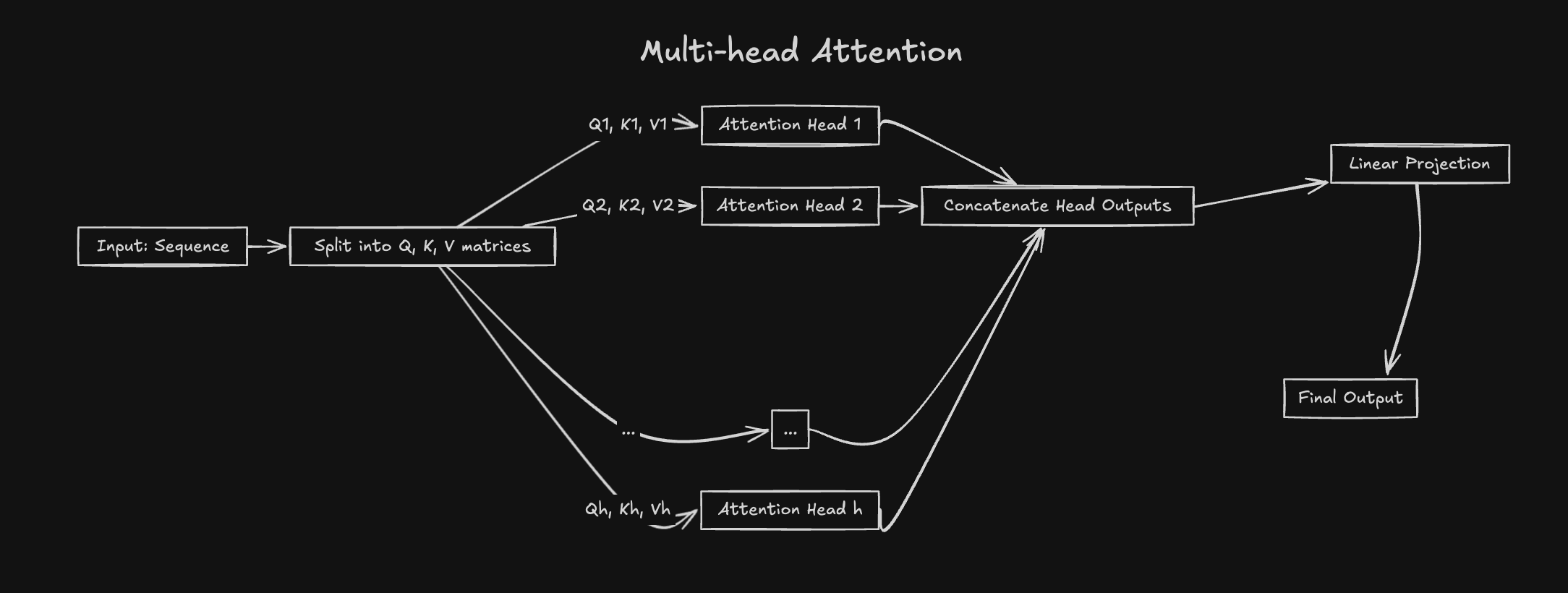
多头注意力:多维度处理机制
{kind=link}
Transformer的设计不止步于单一注意力机制。通过实现多头注意力,模型将输入投影到不同的概念空间,每个"注意力头"专注于捕捉特定类型的语义关系:
- 每个头独立计算注意力特征
- 所有头的输出按维度拼接
- 经过最终线性变换融合多维信息
这种设计赋予模型多维度理解和并行处理能力,好比电影导演通过多个分镜头捕捉不同维度的剧情重点,最终整合成完整的叙事画面。
多头注意力可以从不同的角度捕捉语义关系,从而提高模型的表达能力。
自注意力的语言解析力
以下通过经典例句进行说明:
> 猫睡着了,因为它很累
通过自注意力机制,代词"它"能精准关联到"猫",这种全向上下文感知能力彻底克服了RNN/LSTM单向扫描的局限。Transformer正因具备这种语境全知能力,在处理复杂语义关系时展现出超凡表现。
Transformer架构中的注意力分工
编码器(Encoder)
- 采用自注意力层层递进解析输入(如待翻译的英文句子)
- 每层网络优化语义表示并传递给下一层
解码器(Decoder)
- 应用掩码自注意力:仅关注已生成内容,避免窥见未来信息(如正在生成的法语翻译)
- 搭载交叉注意力:建立目标语与原语的语义对齐(如法语代词与英语主语对应)
编码器将输入序列转化为语义表示,解码器则根据这些语义表示生成目标序列。自注意力和交叉注意力在编码器和解码器中发挥了关键作用。
注意力机制的聚光灯模型
理解注意力机制的一种比喻是:可以将注意力机制比作剧场中的智能追光系统。查询(Query)是导演的指令:“聚焦主角!”,键(Key)是全体演员的定位标识,值(Value)是他们正在演绎的台词。这盏聚光灯能根据剧情发展实时调整光束,在关键处照亮最重要的舞台区域。这种动态聚焦机制,正是Transformer理解复杂语义关系的精髓所在。