随着基础模型的兴起,向量数据库的需求显著增加,成为机器学习领域的热门话题。值得注意的是,向量数据库的应用场景远不止于大语言模型(LLM)。
在机器学习领域,我们经常处理向量嵌入。向量嵌入是一种数值表示,通过特定的机器学习模型将对象的上下文信息(特征)映射到潜在空间,用于表征数据的特征。向量数据库是为处理向量嵌入而专门设计的,擅长存储、更新和检索向量数据。可以将向量数据库想象成一个高效的图书馆管理员,专门管理和查找书籍(向量嵌入)的位置。
在检索过程中,通常是查找与查询向量最相似的向量。查询向量需嵌入到相同的潜在空间中,然后传递给向量数据库进行比对。这种检索过程被称为“近似最近邻搜索”(Approximate Nearest Neighbor, ANN,后文第10点会详细介绍)。
查询的形式多种多样。例如,可以是一张图片,用于查找相似的图片;也可以是一个问题,用于检索相关上下文,再通过大语言模型生成答案。
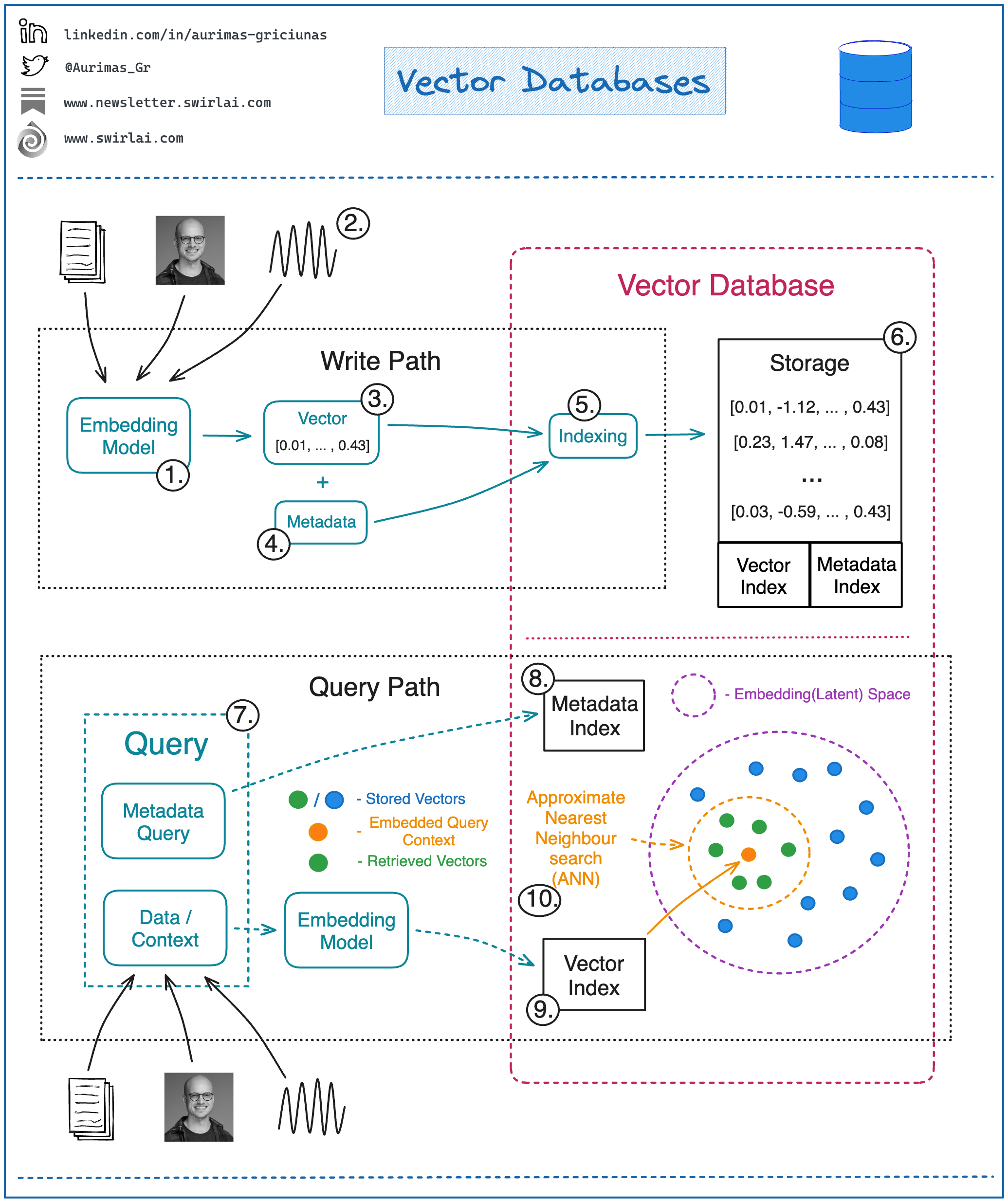
接下来,我们来看看如何与一个典型的向量数据库进行交互(见图1):
{kind=link}
#### 写入和更新数据
1. 选择嵌入模型:选择一个用于生成向量嵌入的机器学习模型。
2. 支持多种数据类型:可以嵌入文本、图片、音频、表格等多种类型的数据,具体选择的机器学习模型取决于数据类型,用于生成嵌入。
3. 生成向量表示:将预处理后的数据输入嵌入模型,得到数据的向量表示。
4. 存储元数据:大多数现代向量数据库允许在存储向量嵌入的同时保存额外的元数据。这些元数据后续可用于在近似最近邻搜索(ANN)之前或之后进行结果过滤。
5. 索引构建:向量数据库会分别对向量嵌入和元数据构建索引,以加速查询时的检索效率。构建向量索引的方法多种多样,包括随机投影、乘积量化(一种用于压缩和搜索高维向量的方法)、局部敏感哈希(一种用于快速查找相似项的技术)和层次可导航小世界图(一种用于高效索引和搜索的图结构)等。
6. 数据存储:向量数据与其索引一起存储。
#### 从向量数据库读取数据
7. 查询组成:对向量数据库的查询通常包含两部分:
- 用于近似最近邻搜索的数据,例如一张图片,希望找到相似的图片;
- 用于排除特定条件的元数据查询,例如在搜索相似公寓图片时,可以通过元数据排除特定位置的公寓(如果元数据中包含位置信息)。
8. 执行元数据查询:元数据查询通过元数据索引进行,可在近似最近邻搜索前后执行。
9. 嵌入查询数据:使用与写入时相同的模型将查询数据嵌入到潜在空间中。
10. 执行近似最近邻搜索:根据索引方法的不同,数据库可能需要对查询向量进行索引处理,然后执行近似最近邻搜索,返回最相似的向量嵌入。常用的相似性度量方法包括:
- 余弦相似度(Cosine Similarity)
- 欧几里得距离(Euclidean Distance)
- 点积(Dot Product)
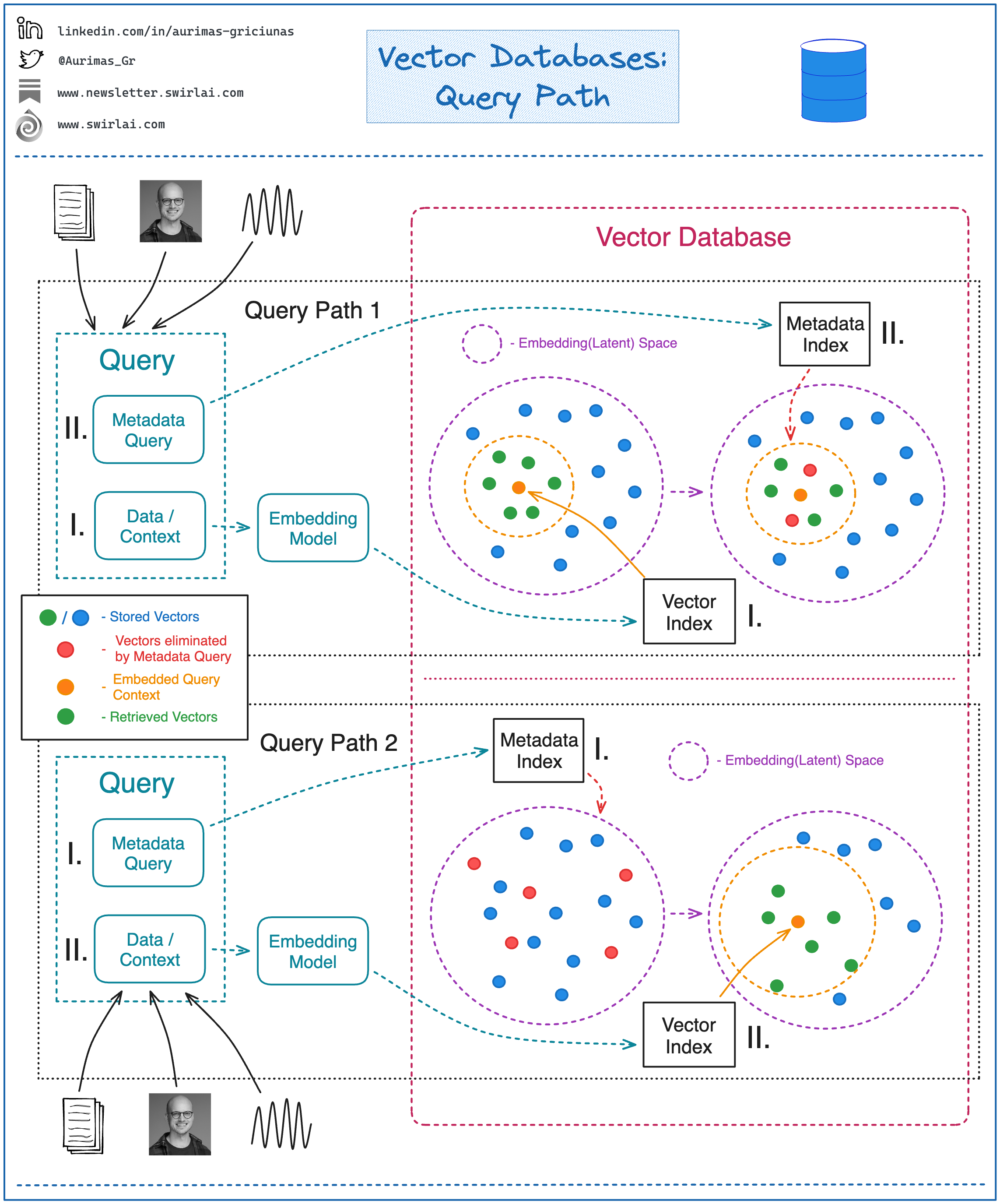
#### 向量数据库的查询路径
如前所述,当涉及元数据查询时,有两种可能的查询路径(见图2):
{kind=link}
- 路径1:先执行近似最近邻搜索,再对检索结果进行元数据查询过滤。
- 路径2:先执行元数据查询过滤数据,再对过滤后的结果进行近似最近邻搜索。
两种路径各有优缺点。例如,若先执行元数据查询,可能会丢失一些与近似最近邻搜索相关的上下文信息;但先执行元数据查询可以显著缩小搜索范围,提升整体查询性能。
向量数据库的应用场景
任何数据都可以嵌入为向量表示,因此向量数据库在现实生活中有广泛应用。以下是几个典型例子:
- 自然语言处理(NLP)
一个常见的应用是为大语言模型提供上下文信息。例如,你想创建一个聊天机器人,仅回答与你的 Substack 文章相关的问题。可以将所有文章嵌入为向量并存储在向量数据库中。当用户提问时,将问题嵌入到相同的潜在空间,通过查询向量数据库检索最相关的文本内容,然后将这些文本发送给大语言模型生成答案。
- 计算机视觉
一个典型案例是从不同角度拍摄的照片中识别相同对象。例如,你想判断 Airbnb 上列出的房间是否与 Booking.com 上的房间相同,可以将 Airbnb 的照片通过 Booking.com 的向量数据库索引进行近似最近邻搜索,找出特征上最相似的房间。
- 推荐系统
推荐系统通常分为两个连续步骤:
- 候选检索:根据查询,检索出少量候选项,供后续使用计算成本较高的模型进行排序。此时向量数据库非常适用,因为它能高效检索大量与查询向量相似的向量。例如,在 Netflix 上,当你搜索一部电影时,系统首先通过向量数据库快速检索出与你搜索内容相似的电影。
- 排序:使用计算成本较高的模型对候选项重新评分。
向量数据库的补充说明
- 常见的向量数据库包括:Qdrant、Pinecone、Weaviate、Milvus、Faiss。
- 此外,虽然不是专用的向量数据库,但越来越多的数据库供应商开始支持近似最近邻搜索功能,如 Redis、Cassandra 等。